






基于注意力的卷积递归神经网络的复杂频谱映射,用于语音增强
Liming Zhou1, Yongyu Gao1,Ziluo Wang1,Jiwei Li1,Wenbin Zhang11CloudWalk Technology Co., Ltd., Shanghai, China 1fzhouliming,gaoyongyu,wangziluo,lijiwei,zhangwenbing@cloudwalk.cn
摘要
语音增强已经从深度学习在可懂度和感知质量方面的成功中获益。传统的时频(TF)域方法侧重于通过天真卷积神经网络或递归神经网络来预测TF掩码或语音频谱。最近的一些研究是基于复杂频谱映射卷积递归神经网络(CRN)。这些模型直接从编码器层的输出和解码器层的输入跳过,这可能是不周到的。与CRN模型相比,所提出的CARN模型在PESQ、CBAK、COVL、CSIG和son等几个指标上相对提高了10%以上,并且在DNS Challenge 2020的实时和非实时跟踪中,这些指标都优于第一名的模型。
关键词: 语音增强,CRN,注意力机制,DNSMOS,PESQ
1. 绪论
增强技术对于改善经典的语音增强技术至关重要,包括频谱减法[2]、维纳滤波[3]、最小均方误差(MMSE)估计器[4]和优化修正的对数光谱振幅语音估计器[5]。这些基于时频域的信念方法在静止噪声环境中取得了相对较好的性能,而在处理大多数场景中的非静止噪声时却不够强大。
在过去的几年里,深度神经网络(DNNs)极大地评估了语音增强的性能[6]。与传统技术相比,现有的DNN方法提供了更好的结果。在[7][8]中,递归神经网络(RNNs)被用来模拟时间特征。在[9]中,自动编码器被用于语音增强,而第一个语音增强基准将DNN作为非线性回归函数[10]。卷积递归神经网络(CRN)被用来提取长文信息[11]。 语音增强技术也以图像合成为例,使用生成对抗网络(GAN)架构来重建目标语音信号[12-16]。这些基于DNN监督的语音增强方法比传统的算法更有优势。
最近,U-net结构取得了巨大的成功,在各种机器学习任务中,包括医疗诊断[17]、语义分割[18]、歌唱源分离[19]等,其性能已经超过了基本的DNN架构。在这种成功的激励下,语音增强在原始波形[12, 20-22]和时间频率特征[23]中都探索了U-net结构。在[24]中,Wave-U-Net在编码器和解码器中采用了GLU的激活,以及中间的双向LSTM。DCCRN[25]利用U-net和深度复杂网络[26]的优势进行去噪。注意力单元和U-net的结合使语音增强的性能更上一层楼。自我注意是一种有效的上下文信息聚合机制,它对输入序列本身进行操作,可以用于任何有顺序输入和输出的任务。注意力波浪网[27]在语音银行语料库(VCTK)数据集上的表现超过了所有其他已发表的语音增强方法。
基于掩码的目标,描述了干净的语音和背景噪声之间的时间-频率关系,被用来训练网络。通常情况下,由理想二进制掩码(IBM)[28]、理想比率掩码(IRM)[29]和频谱幅度掩码(SMM)[30]组成的矩阵只考虑清洁波形和混合音频之间的幅度。随后,相位被考虑在内,其中相位敏感掩码(PSM)[31]是第一个显示相位信息可行性的方法,复数比掩码(CRM)[32]被宣布可以通过同时增强清洁语音和混合语音频谱图的实部和虚部来正确地重构语音。此后不久,CRN[33]使用一个编码器和两个解码器进行复数频谱映射(CSM),以巧合地估计混合语音的实数和虚数频谱。值得注意的是,CRM和CSM拥有语音信号的全部信息,因此它们在理论上可以实现最佳的甲骨文语音增强性能。
在本文中,我们提出了一个名为CARN的网络,该网络融合了U-net、注意力机制、跳过连接、编码-解码器之间的LSTM和时频域的CRM等高效组件。我们还研究了将门卷积网络与CARN模型结合起来,形成一个名为GCARN的模型。我们表明,根据2020年DNS挑战赛[34]的语音质量指标(PESQ等)和Valentini[35]发布的数据集,在时频域中利用注意力-LSTM-UNET的CRM取得了明显的改进效果,超过了这些数据集上其他已发表的语音增强方法。
2. CARN模型
CRN模型首先由Ke Tan[36]提出,并进一步研究了复杂频谱映射[33]机制和门卷积[37]。根据上述研究,我们研究了一个名为CARN的新模型,它将CRN与注意力机制相结合。在CARN模型中,我们使用了基于注意力的编码层到解码层的跳过连接。此外,我们将我们提出的模型与基于门卷积的CRN模型以及以前的一些工作进行了对比。
2.1. CARN结构
编码器和解码器都由6个具有PReLU激活函数的Conv2d块组成,旨在从输入特征中提取高张力的特征,并降低分辨率。该模型如图1所示。我们将频谱特征作为输入。LSTM层的隐藏大小为512,T-F核大小为3,跨度为1∗2,每个Conv2d或ConvTranspose2d层。每个Conv2d或ConvTranspose2d层之后都有一个batchnorm层。在最后一个ConvTranspose2d层之后嵌入一个线性层,以映射输出特征的复数比率掩码(CRM)。最后,CRM与输入的stft频谱图相乘,得到干净的stft频谱图,参考(4)和(5)。所有的激活函数都是PReLU。
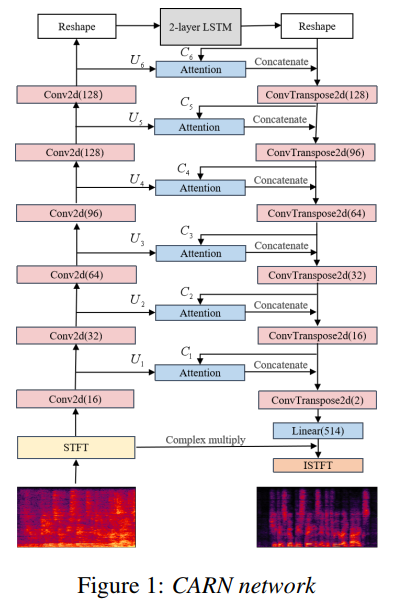
2.2 注意机制
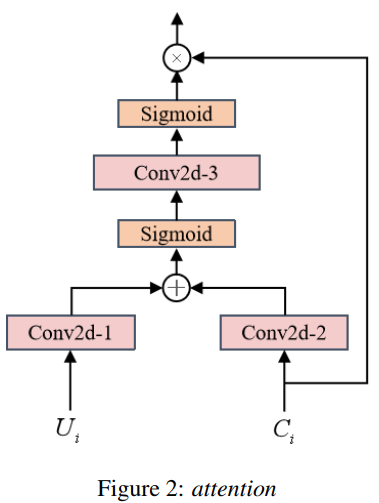
与传统的CRN结构不同,自我注意掩码通过跳过连接与编码器的输出相乘。注意层的输出与最后一个解码器的输出相连接,用于下一个解码器的输入。
图2中描述了AttentionBlock[27]。Ui是编码器结构的输出,Ci是LSTM层或解码器卷积层的输出。另外两个2维卷积,核大小为3,输出通道为输入通道的两倍,称为Wg和Wx,用于将Ui和Ci映射到高维空间特征,用于建立注意力机制模型。高维空间特征的分值是Ci分值的两倍;高维空间特征层的输出可以描述为(1):
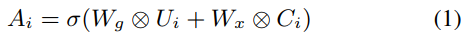
其中Ui和Ci分别表示编码器和解码器的第i层。 σ是sigmoid函数。自我注意区块的输出,其中Wf表示另一个2维卷积层。
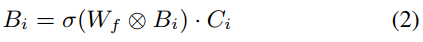
2.3. 培训目标
CARN估计CRM,并通过信号逼近(SA)进行优化。给定干净语音S和噪声语音Y的复变STFT频谱图,CRM可以定义为
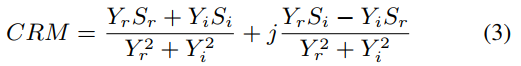
其中,Yr和Yi分别指的是噪声复数频谱的实部和虚部,Sr和Si同样指的是干净复数频谱的实部和虚部,让Sr和Si分别指的是估计去噪音频复数频谱的实部和虚部。 Mr和Mi表示CRM的实部和虚部,那么
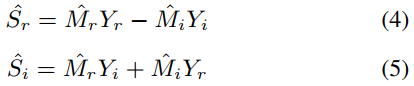
2.4. 损失函数
我们用损失函数训练模型为
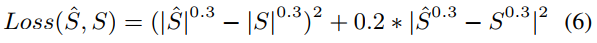
其中S^和S分别表示估计去噪音频和清洁音频。S0:3 = jSj0:3ej\S ,是功率压缩的STFTs。这个损失函数由谱图MSE(均方误差)和功率压缩STFTs MSE组成。
3. 经验
3.1. 数据集
在我们的实验中,我们在两个数据集上评估所提出的模型。
3.1.1. 数据集1:噪声语音数据库
第一个数据集1,是由Valentini等人发布的[35]。[35],广泛用于语音增强研究,它对不同说话人的各种类型的噪声进行了概括。这个数据集包括48kHz采样频率的干净和嘈杂的音频数据,在训练和测试时需要降频到16kHz。干净的数据集是来自各种文本段落的句子录音,并从Voice Bank语料库[38]中选择了30个英语演讲者,包括有各种口音的男性和女性。28个和2个说话者分别被分配到训练和测试集。测试集由20种不同的噪声条件组成,其中5种噪声来自DEMAND数据库,产生824个测试项目,每个测试者在每种条件下大约有20个不同的句子。[35]
3.1.2. 数据集2:DNS 2020
第二个数据集是基于Interspeech 2020 DNS挑战赛数据集提供的数据[34]。DNS挑战赛数据集包括180小时的噪声集,其中包括150个类别和65,000个噪声片段,以及超过500小时的干净语音,其中包括来自2150个发言人的音频片段。清晰的语音数据集来自名为Librivox的公共有声读物数据集。噪声片段选自Audioset和Freesound。我们随机选择了24000个带有所有噪声片段的演讲者,创建了200小时的噪声训练集,单噪声范围从0dB到40dB。每个被选中的演讲者的音频片段都被串联成30秒,同时混合各种噪声片段。我们用DNS-Challenge无盲点测试数据集和盲点测试数据集来评估所提出的模型。这两个数据集都包括合成数据集和真实录音。
3.2. 训练设置和基线
我们在这两个数据集上使用Adam优化器退火训练,学习率为1e-3和64小批。当j∆Loss损失j小于0.05时,通过提前停止选择模型。STFT窗长和跳数分别被调制为32毫秒和16毫秒。汉宁窗和512FFT长度被应用。我们将FFT谱图的实部和虚部叠加在一起作为输入。我们将提出的模型与几个模型进行了比较,描述如下:
- CRN:一个因果复杂频谱映射卷积递归网络[33],作为对比在第一个数据集上进行了评估。除了注意力机制外,该模型的结构与所提出的CARN模型相同。它由六个卷积层编码器和六个对称层解码器组成,它们之间有两个lstm层。
- GCRN:一个因果复杂谱系映射门卷积递归网络[37],在第一个数据集上作为对比进行评估。这个模型的结构与上述CRN相同,除了门卷积层。
- DCCRN-E:由[25]提出的模型,基于CRN架构,但有复杂的卷积层,在2020年深度噪声抑制挑战赛的实时赛道上获得了第一名。我们使用官方开放的源代码2在两个数据集下对该模型进行了比较。
- CARN。建议的模型,在第2节有很好的描述,分别在两个数据集上进行训练和测试。
- GCARN。与CARN结构相同,除了门卷积层,是一个对比度模型。
3.3. 评价:客观指标和结果
我们在两个测试数据集上评估了宽带语音质量感知评估(PESQ)-ITU-T P.862.2[39],以及CSIG、CBAK、COVL[40]和STOI的综合指标。这些指标在某些方面评估了我的模型性能。但这些指标需要参考干净的语音,不能在真实录音中使用。DNS-Challenge 2020中的盲测数据集由真实录音和合成噪声音频组成。我们用另一个指标,即DNSMOS,在这个数据集上评估了我们提出的模型。
DNSMOS指标是由Chandan K A Reddy等人最近提出的。[DNSMOS指标是一个非侵入性的客观语音质量指标,适用于宽频带情况,比其他广泛使用的客观指标如SDR和POLDA更可靠,并且不需要参考干净的语音。
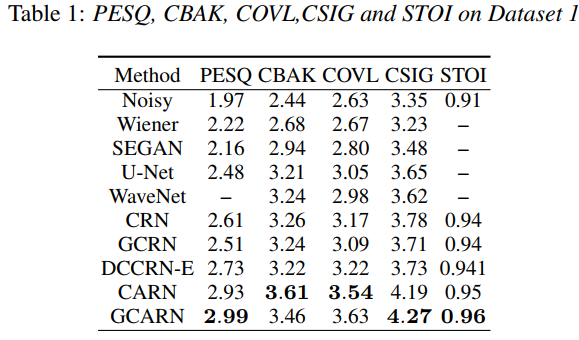
在表1中,我们列出了几种方法在第一个数据集上的结果,如Wiener、SEGAN[12]、U-Net[19]、WaveNet[20]、CRN、GCRN、DCCRN-E以及我们提出的模型CARN和GCARN。CRN和GCRN模型比Wiener,SEGAN,U-Net和WaveNet好,除了CBAK分数,在PESQ上不如DCCRN-E好。 我们通过在编码器层和解码器层之间用注意力代替直接连接来改进CRN和GCRN,我们分别称之为CARN和GCARN模型,在所有这些指标上都取得了明显的改进。CARN在PESQ、CBAK、COVL、CSIG上对CRN的改进分别为12.2%、10.7%、11.7%、10.8%,GCARN在这些指标上对GCRN的改进分别为19.1%、6.8%、17.5%、15.1%。CARN和GCARN是它们中最好的模型。当CRN和CARN与GCRN和GCARN进行比较时,结果表明在这个问题上,门卷积可能是不必要的。
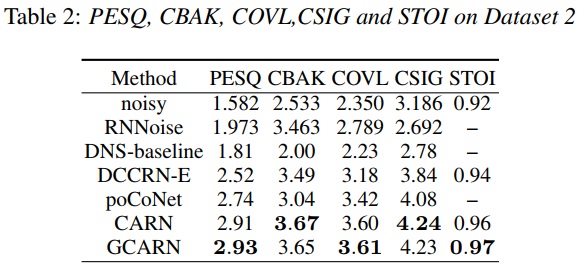
在表2中,我们在DNS-Challenge数据集上训练和评估了CARN和GCARN模型。我们将我们提出的模型与RNNoise、DNS-Challenge基线[34]、DCCRN-E和在2020年深度噪声抑制挑战赛的非实时跟踪中获得第一名的poCoNet[42]作了比较。CARN在PESQ、CBAK、COVL、CSIG方面分别以15.5%、5.2%、13.2%、10.4%的成绩优于DCCRN-E,并在这些指标上分别以6.2%、20.7%、5.3%、3.7%的成绩优于poCoNet。
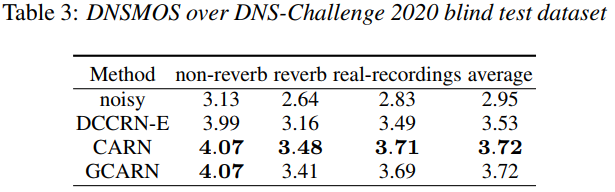
在表3中,我们在DNS-Challenge 2020盲测数据集上对我们提出的模型和DCCRNE进行了评估,采用了DNSMOS指标。与DCCRN-E相比,CARN和GCARN可以实现语音质量的显著提高。
4. 总结
对两个数据集的实验表明,与直接连接相比,注意力机制可以显著提高CRN架构的性能。一个合理的解释是,注意力机制过滤了一些从编码器层连接到解码器层的噪声特征。我们提出的模型CARN在2020年DNS挑战赛的实时和非实时跟踪中,在许多指标上都超过了第一名的模型。
5. 参考文献
[1] P. C. Loizou, Speech Enhancement. New York: CRC Press, 2013.
[2] S. Boll, “Suppression of acoustic noise in speech using spectral subtraction,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 27, no. 2, pp. 113–120, 1979.
[3] J. S. Lim and A. V. Oppenheim, “Enhancement and bandwidth compression of noisy speech,” Proceedings of the IEEE, vol. 67,no. 12, pp. 1586–1604, 1979.
[4] Y. Ephraim and D. Malah, “Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 32, no. 6, pp. 1109–1121, 1984.
[5] I. Cohen and B. Berdugo, “Speech enhancement for nonstationary noise environments,” Signal Processing, vol. 81, no. 11,pp. 2403–2418, 2001.
[6] D. L. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” 2017.
[7] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder,” in INTERSPEECH 2013,14th Annual Conference of the International Speech Communication Association, Lyon, France, August 25-29, 2013, F. Bimbot,C. Cerisara, C. Fougeron, G. Gravier, L. Lamel, F. Pellegrino, and P. Perrier, Eds. ISCA, 2013, pp. 436–440.
[8] J. M. Valin, “A hybrid dsp/deep learning approach to real-time full-band speech enhancement,” 2017.
[9] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder,” in INTERSPEECH 2013,14th Annual Conference of the International Speech Communication Association, Lyon, France, August 25-29, 2013, F. Bimbot,C. Cerisara, C. Fougeron, G. Gravier, L. Lamel, F. Pellegrino, and P. Perrier, Eds. ISCA, 2013, pp. 436–440.
[10] “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Transactions on Audio Speech and Language Processing, 2015.
[11] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement,” 06 2018.
[12] S. Pascual, A. Bonafonte, and J. Serra, “Segan: Speech enhance- `ment generative adversarial network,” 2017.
[13] S. W. Fu, C. F. Liao, Y. Tsao, and S. D. Lin, “Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement,” 2019.
[14] J. Lin, S. Niu, Z. Wei, X. Lan, A. J. van Wijngaarden, M. C.
Smith, and K.-C. Wang, “Speech Enhancement Using Forked Generative Adversarial Networks with Spectral Subtraction,”in Proc. Interspeech 2019, 2019, pp. 3163–3167. [Online].
Available: http://dx.doi.org/10.21437/Interspeech.2019-2954[15] D. Baby and S. Verhulst, “Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty,” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019.
[16] J. Lin, S. Niu, A. J. van Wijngaarden, J. L. McClendon,M. C. Smith, and K. Wang, “Improved speech enhancement using a time-domain GAN with mask learning,” in Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China,25-29 October 2020, H. Meng, B. Xu, and T. F. Zheng,Eds. ISCA, 2020, pp. 3286–3290. [Online]. Available: https://doi.org/10.21437/Interspeech.2020-1946[17] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015.
[18] V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” 2017.
[19] H. E. M. N. B. R. K. A. W. T. Jansson, A., “Singing voice separation with deep u-net convolutional network,” 2017.
[20] D. Stoller, S. Ewert, and S. Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” 2018.
[21] C. Macartney and T. Weyde, “Improved speech enhancement with the wave-u-net,” 2018.
[22] O. Ernst, S. E. Chazan, S. Gannot, and J. Goldberger, “Speech dereverberation using fully convolutional networks,” in 2018 26th European Signal Processing Conference (EUSIPCO), 2018.
[23] M. H. Soni, N. Shah, and H. A. Patil, “Time-frequency maskingbased speech enhancement using generative adversarial network,”in ICASSP, 2018.
[24] A. Defossez, N. Usunier, L. Bottou, and F. Bach, “Demucs: Deep ´extractor for music sources with extra unlabeled data remixed,”2019.
[25] Y. Hu, Y. Liu, S. Lv, M. Xing, and L. Xie, “Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement,” 2020.
[26] C. Trabelsi, O. Bilaniuk, Y. Zhang, D. Serdyuk, D. Subramanian,J. F. Santos, S. Mehri, N. Rostamzadeh, Y. Bengio, and C. J.
Pal, “Deep complex networks,” in ICLR 2018 Conference,February 2018. [Online]. Available: https://www.microsoft.com/en-us/research/publication/deep-complex-networks/[27] R. Giri, U. Isik, and A. Krishnaswamy, “Attention wave-u-net for speech enhancement,” in 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2019.
[28] D. L. Wang, “On ideal binary mask as the computational goal of auditory scene analysis,” Springer US, 2005.
[29] A. Narayanan and D. L. Wang, “Ideal ratio mask estimation using deep neural networks for robust speech recognition,” in IEEE International Conference on Acoustics, 2013.[30] Y. Wang, A. Narayanan, and D. Wang, “On training targets for supervised speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 12, pp. 1849–1858, 2014.
[31] H. Erdogan, J. R. Hershey, S. Watanabe, and J. L. Roux, “Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks,” in ICASSP 2015 - 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015.
[32] D. S. Williamson, Y. Wang, and D. L. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Transactions on Audio Speech and Language Processing, 2016.
[33] “Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019.
[34] C. K. Reddy, E. Beyrami, H. Dubey, V. Gopal, R. Cheng, R. Cutler, S. Matusevych, R. Aichner, A. Aazami, S. Braun et al., “The interspeech 2020 deep noise suppression challenge: Datasets,subjective speech quality and testing framework,” arXiv preprint arXiv:2001.08662, 2020.
[35] C. Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[36] K. Tan and D. Wang, “A convolutional recurrent neural network for real-time speech enhancement.” in Interspeech, 2018, pp.
3229–3233.
[37] ——, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 380–390, 2019.
[38] C. Veaux, J. Yamagishi, and S. King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in 2013 international conference oriental COCOSDA held jointly with 2013 conference on Asian spoken language research and evaluation (O-COCOSDA/CASLRE). IEEE, 2013,pp. 1–4.
[39] ITU, “Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs,” 2001.
[40] P. C. Loizou, Speech Enhancement: Theory and Practice.
Speech Enhancement: Theory and Practice, 2007.
[41] C. K. Reddy, V. Gopal, and R. Cutler, “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” arXiv preprint arXiv:2010.15258, 2020.
[42] U. Isik, R. Giri, N. Phansalkar, J.-M. Valin, K. Helwani,and A. Krishnaswamy, “Poconet: Better speech enhancement with frequency-positional embeddings, semi-supervised conversational data, and biased loss,” arXiv preprint arXiv:2008.04470,2020.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









