







[ICASSP 2022]
Motivation
融合卷积编码器-解码器(CED)结构和循环结构的卷积递归网络(CRN)在单耳语音增强中取得了良好的性能。然而,跨频率上下文的特征表示是高度受限的,这是因为在CED卷积中感受野受限。本文提出了一种卷积循环编码器(CRED)结构,以提高沿频率轴的特征表示。除了CRED,还在编码器和解码器之间插入两个堆叠的FSMN层,以进一步模拟时间动态。将提出的框架命名为Frequency Recurrent CRN (FRCRN)。
Method
目的是从已损坏的语音信号x = y * h + z∈R中估计干净语音信号y,其中y * h是混响操作,z是加性噪声。FRCRN模型主要由提出的CRED和一个循环模块组成。CRED包括编码器模块和解码器模块。两个模块都包含多个卷积循环(CR)块,递归模块由两个堆叠的复杂FSMN (CFSMN)层组成。在FRCRN中,循环模块对长期的时间依赖性进行建模。在残差连接上添加注意块CCBAM,以促进信息流。通过应用不对称填充使所有卷积在时间上具有因果关系。
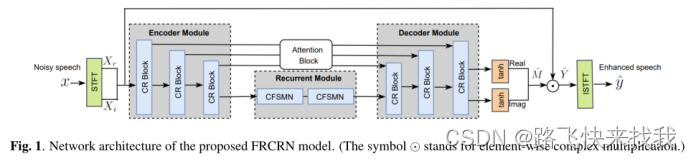
A Convolutional recurrent (CR) block
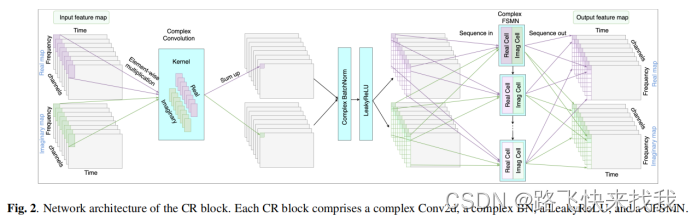
每个CR块由一个复数二维卷积层(Conv2d)、一个复数批归一化层(BN)、一个LeakyReLU函数和一个CFSMN层组成。复数二维卷积层的输出U可表示为:
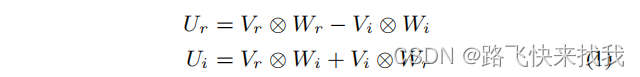
使用T’ = 2, stride = 1执行因果卷积,并在时间方向上使用零填充。在频率方向上,使用F’ = 5, stride = 2,不带零填充,在encoder中逐块将频率轴上的特征映射减半。对于FRCRN中的所有CR块,使用C’ = 128来保持相同数量的feature map。
Conv2d层的输出被发送到CFSMN层。之所以采用FSMN而不是LSTM,是因为FSMN不仅可以达到LSTM的竞争性能,而且只需要LSTM的四分之一左右的参数。
CFSMN在FRCRN中使用的操作如下。考虑feature map U的实部Ur,将其从C’ × T × F’’ 转换成T × F’’ × C’ 。对于Ur∈的当前帧t,形成了频率序列Sr(t)∈
={
1(t)、
2(t)、···、
’’(t)∈
}。将CFSMN的实部单元应用于序列Sr(t),第l个分量的输出采用以下形式:
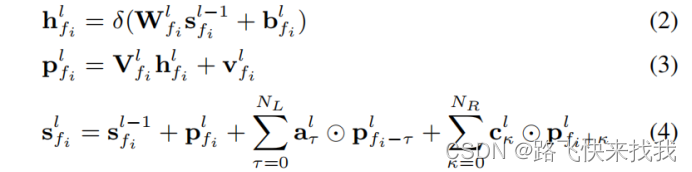
这里,和
分别表示第l个内存块的回顾和前瞻顺序。将
=20和
=0设置为只回顾实验中所有的序列。由于我们在CR块中使用单一的CFSMN层,l的值是1。对于虚部,应用一个与实部单元具有相同操作的CFSMN虚单元。CFSMN输出Sout可以定义为:
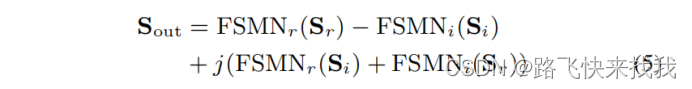
其中,FSMNr和FSMNi代表CFSMN的实部单元和虚部单元。Sr和Si表示频率序列的实部和虚部。在递归模块中,CFSMN输入的实部被重塑为Ur∈和H=F’’×C’。然后形成一个时间序列Qr={qt1,qt2,···,qT∈
}。CFSMN的输出遵循等式5。
B loss
时域损失函数SI-SNR是一种常用的噪声抑制评价指标。它是信号级的损失,直接在信号本身上执行。除了SI-SNR,还考虑了cIRM的实部Mr和虚部Mi估计的均方误差(MSE)损失。具体通过以下联合损失函数对FRCRN模型进行优化,其中λ=1:
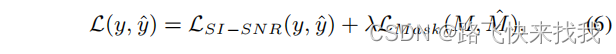
其中,LSI−SNR(y,ˆy)为定义为以下的SI-SNR损耗:
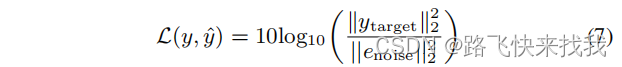
Mask loss L(M、ˆM)定义为:
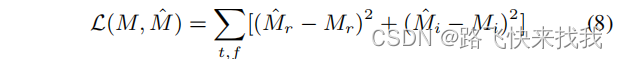
实验步骤
1)数据集1:WSJ0语料库
训练和验证:选择了131个说话者50小时的干净演讲,从RNNoise中选择了50小时的噪音。40小时的干净演讲和40小时的噪音用于训练和验证,
测试:其余的用于测试集。测试集中包含了从0dB到10dB之间的广泛的信噪比。
2)数据集2:DNS-2020数据集
训练和开发:DNS-2020数据集包含500小时的纯语音、65K噪声剪辑和80K RIR剪辑。生成了总共3K小时的noise-clean对,用于训练和开发,其中30%的清洁语言与RIR片段进行了卷积。在生成训练数据时,信噪比在0 ~ 15 dB之间随机选取。
测试:采用非盲综合测试集。
3)数据集3:VoiceBank+Demand数据集。
训练:来自28个发言者的11,572对干净噪声训练对。
测试:来自另外2个发言者的824对用于测试。
4)数据集4:全频带DNS-2022数据集
使用DNS-2022提供的全频带数据,生成了总共3K小时的噪声清除对,其中30%是混响语音。
实验结果
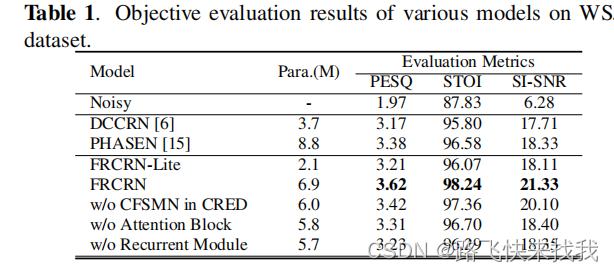
结果如表1所示。可以看到,所提出的全FRCRN模型在所有评估指标上都优于基线。其中FRCRN-Lite将卷积通道C’和CFSMN单元大小设置为64,它的可训练参数比完整的FRCRN模型少三倍。FRCRN-Lite的复杂性比DCCRN要低,但仍然提供了一个具有竞争力的性能。消融研究是通过逐步(1)从CRED中去除CFSMN层;(2)去除注意块CCBAM;(3)去除循环模块。性能下降的趋势表明,所有的组件都有贡献。
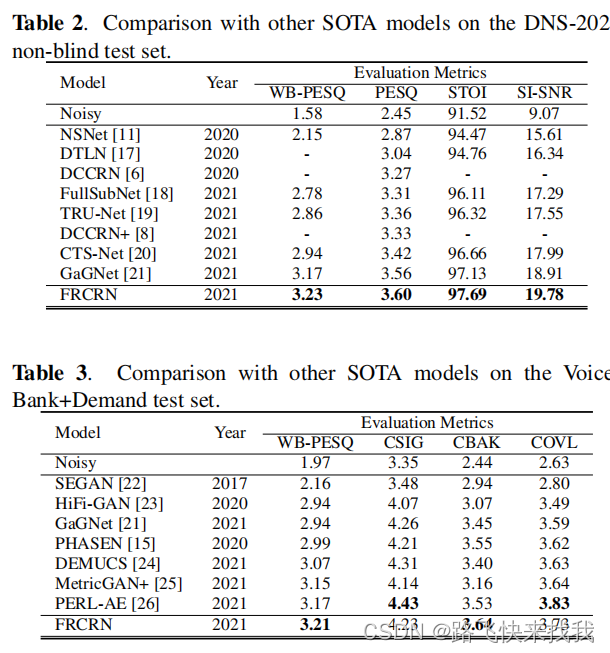
表2和表3显示了与SOTA模型公布结果的性能比较。提出的FRCRN模型在大多数评估指标上优于以前的SOTA方法,除了PERL-AE利用大规模预训练模型在CSIG和COVL上的表现更好。
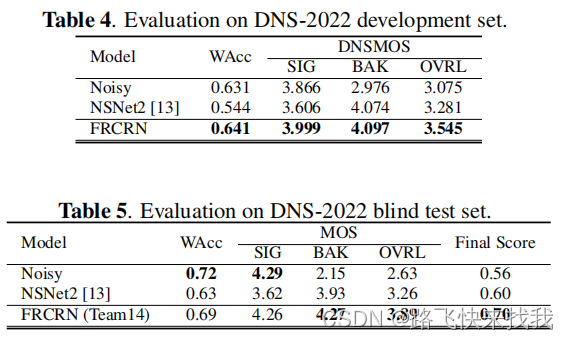
从表4可以看出,与基线相比,模型在所有指标上都取得了更好的结果。使用相同的模型对盲测集进行增强,表5显示了DNS-2022 P .835主观评价结果和WAcc结果。模型具有一致的更好的性能比基线的语音质量和WAcc的退化更轻。提交的作品在非个性化的赛道中最终得分排名前2。
总结
提出了一种卷积递归编码器-解码器结构(CRED),以增强基于频率递归的特征表示。将频率递归应用于沿频率轴的三维卷积特征映射,并通过前馈顺序记忆网络有效地实现。FRCRN模型利用CRED捕捉长程频率相关性,利用时间循环模块捕捉时间动态。在复数域实现了FRCRN,并使用联合损失函数进行优化。FRCRN模型在宽带基准上实现了SOTA性能,并在ICASSP 2022 DNS挑战中获得了全频带非个性化赛道的第二名。
2022.5.4














 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









