







文章目录
Listen,Attend,and Spell[Chorowski.et al.,NIPS15]
Listen就是指的Encoder,Spell指的就是Decoder。This paper is the typical seq2seq with attention.
模型框架
Listen
Encoder
Input:acoustic features{ x 1 , x 2 , . . . , x T {x^1,x^2,...,x^T} x1,x2,...,xT}
Output:high-level representations{ h 1 , h 2 , . . . , h T h^1,h^2,...,h^T h1,h2,...,hT}

输入和输出的长度是一样的。
Encoder 可以用很多模型来做,在2020年左右比较流行的是CNN+RNN,然后还有Self-attention Layers
这个Encoder的目标主要是:
- 抽取相关的信息Extract content information
- 移除说话者的口音还有一些噪声Remove speaker variance, remove noises
Down Sampling
Why:序列长度过长,并且相邻的向量之间表示的信息量不会差别太大。
下采样有许多不同的方法:
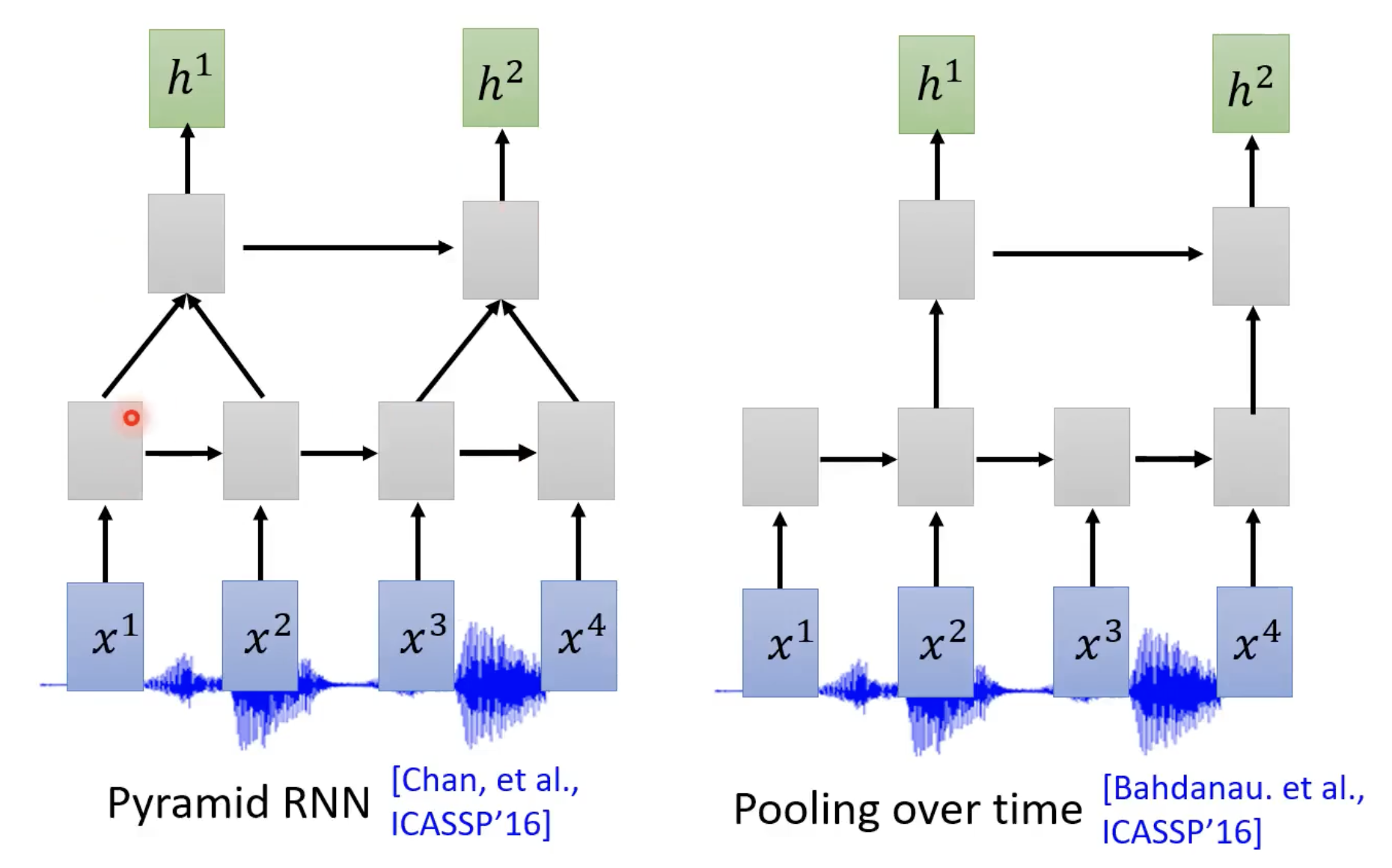
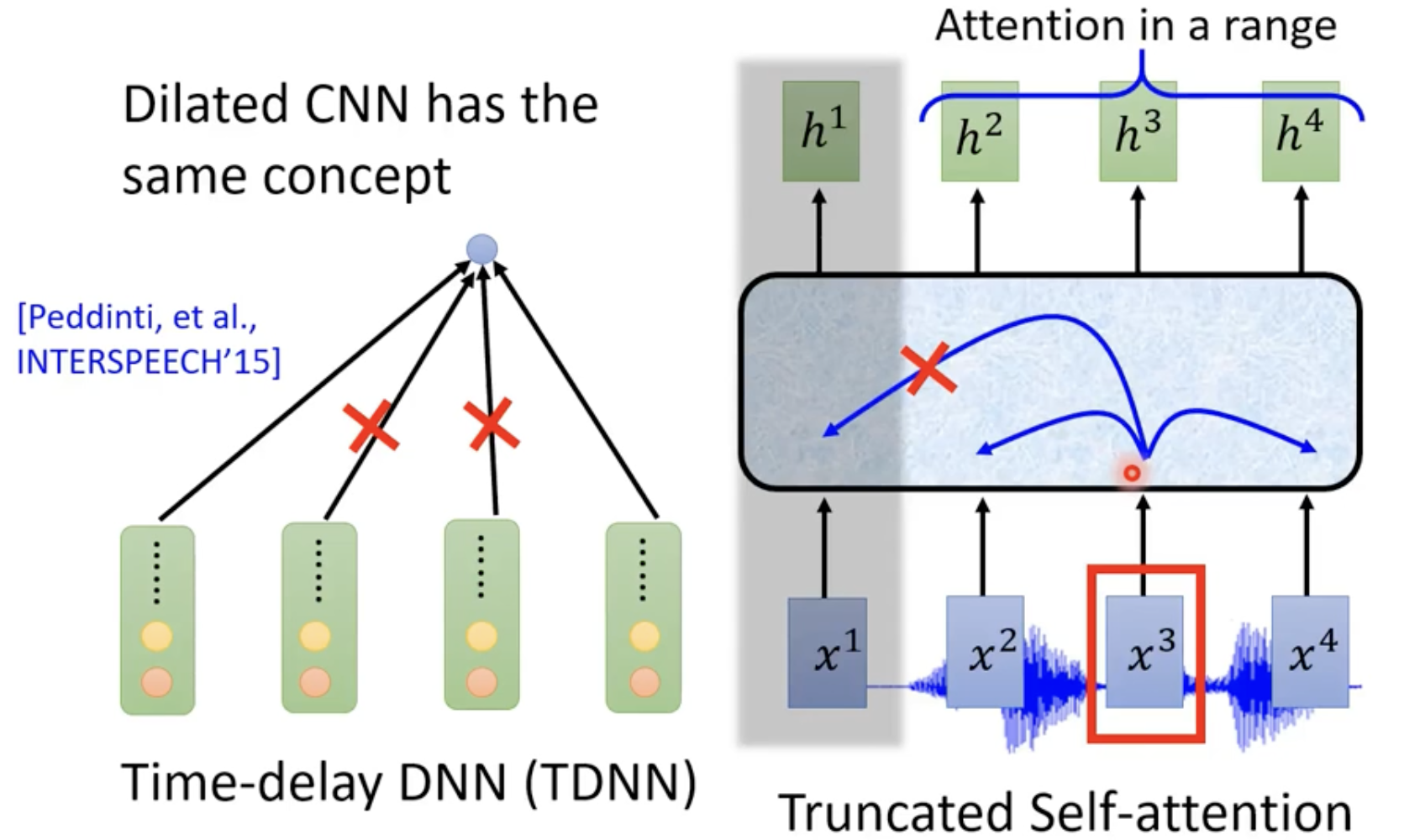
Pyramid RNN这些下采样方法是很重要的,可能会导致有些模型(LAS)train不起来。
Truncated Self-attention与Time-delay DNN最主要的区别在于,后者能够节约更多的计算资源,不要关注过多的前后信息。
Attend
这里就是注意力机制
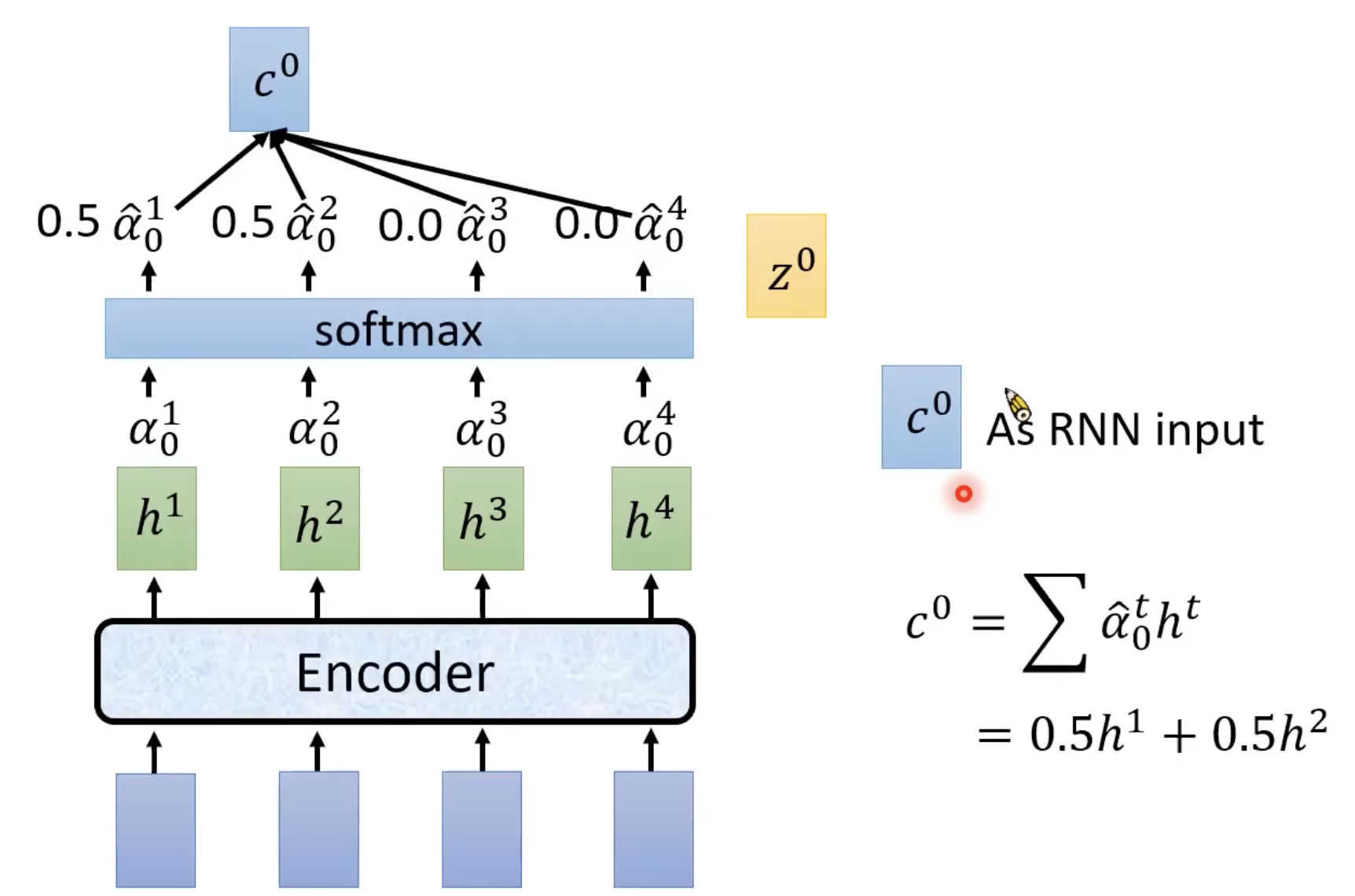
拿到每个隐层的注意力系数。 c 0 c^0 c0就作为后续RNN的输入
spell
Spell拼写,可以说就是在解码。
一下图片展示了输出第一个字母的完整过程:
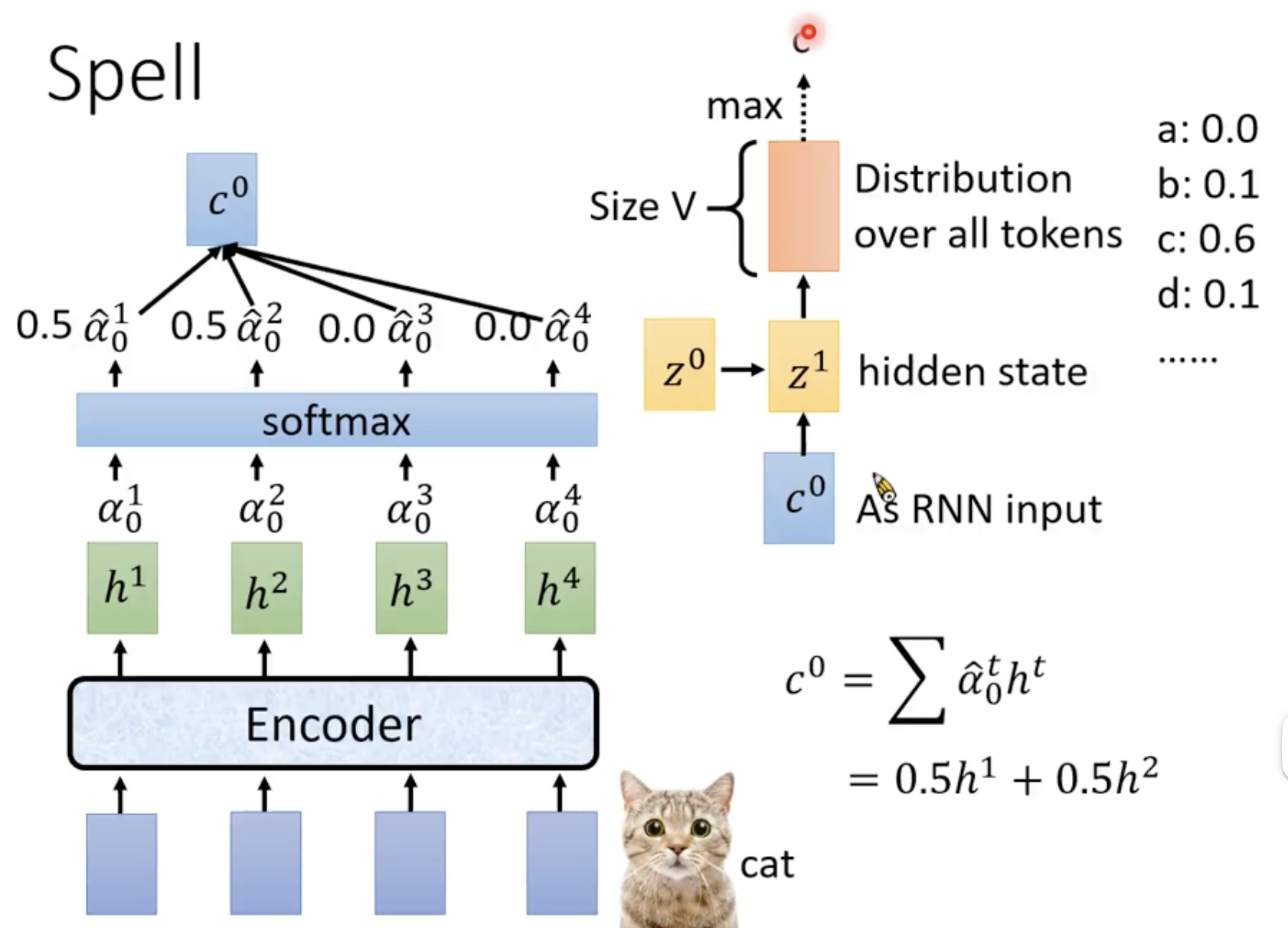
将上文中的 c 0 c^0 c0通过解码器后,可以拿到最后隐层的向量表示,通过一个softmax可以拿到其token的分布,最后输出 c c c
Spell后的全过程图
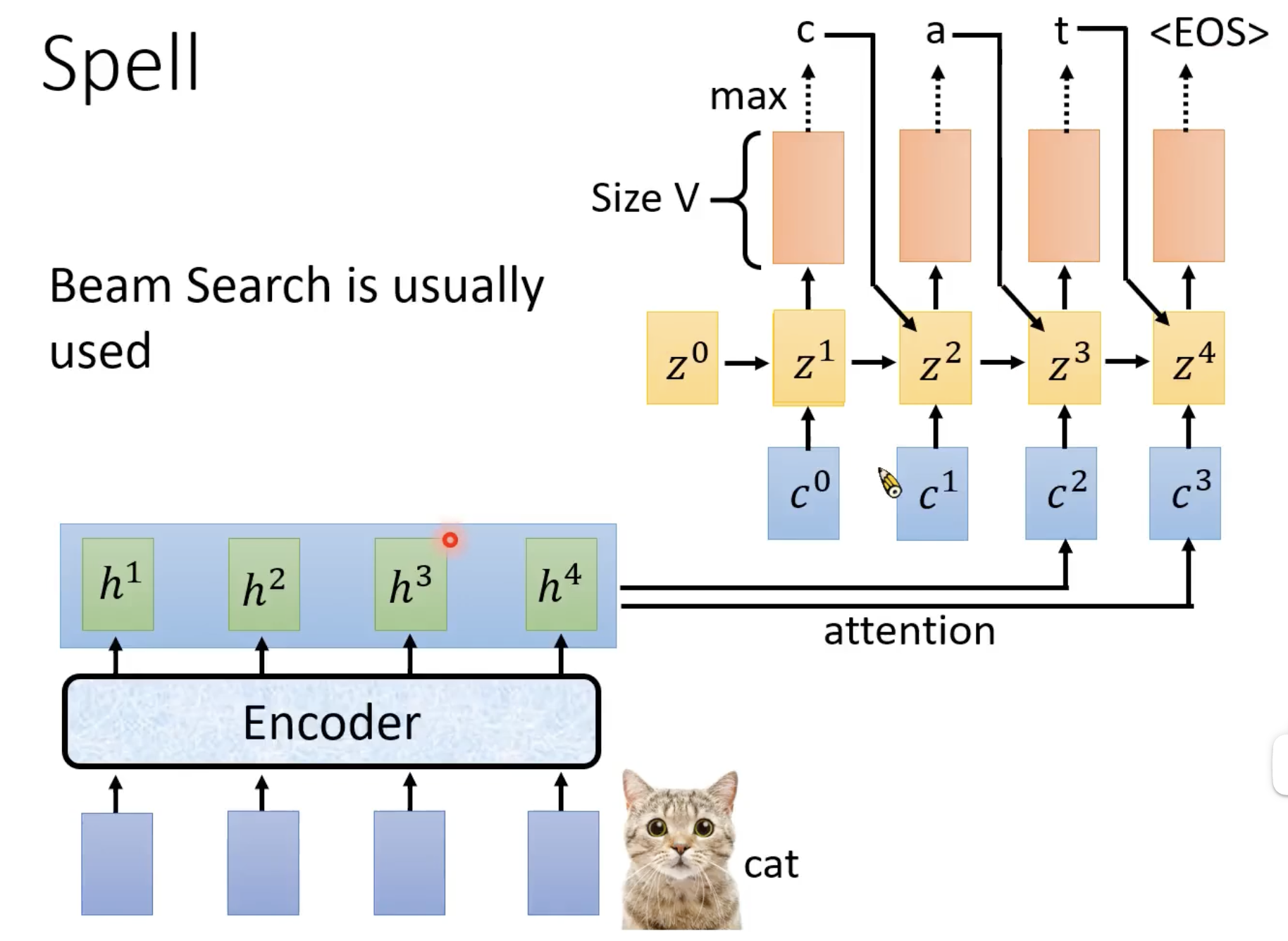
Beam Search is usually used
Greedy Decoding
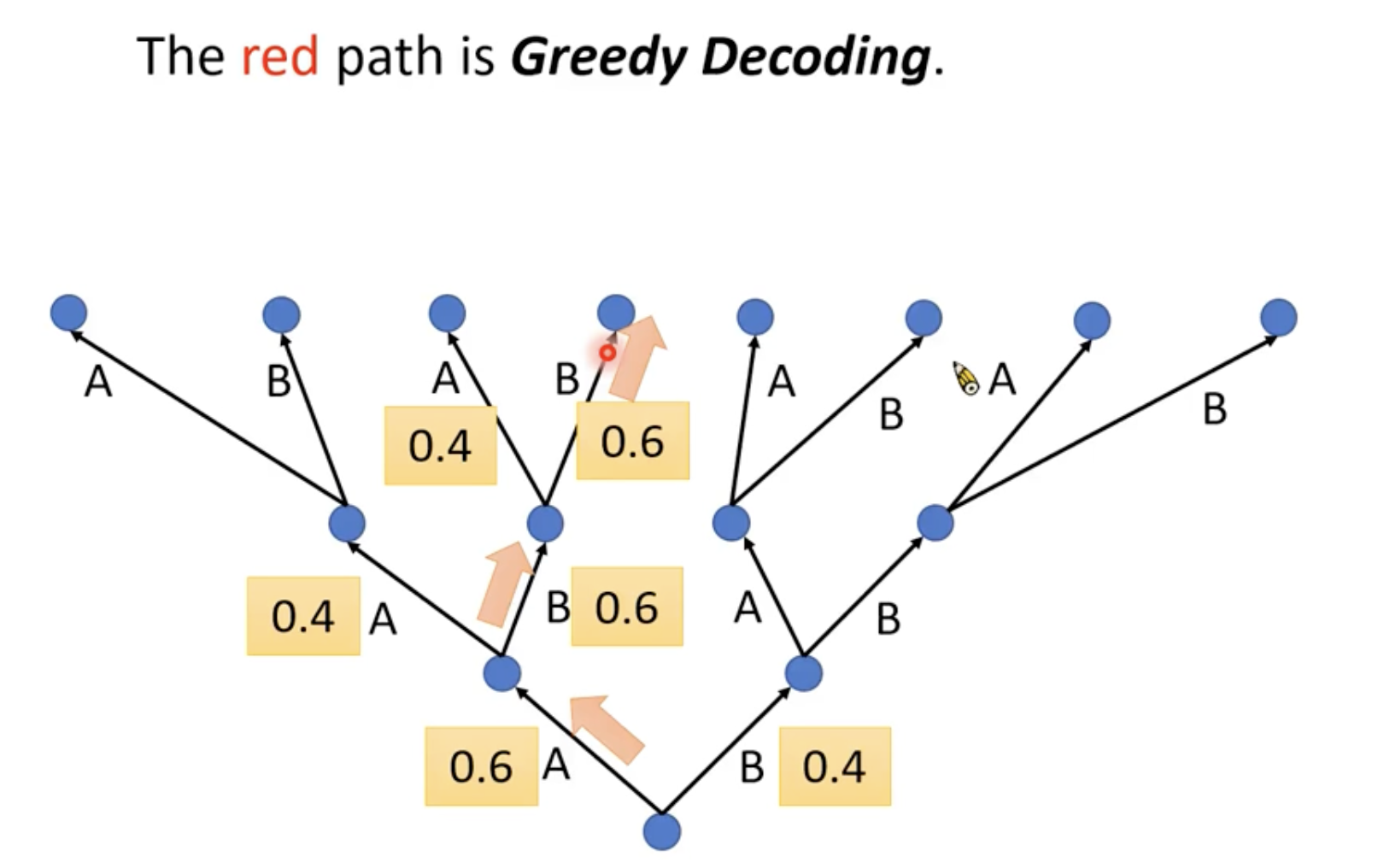
假设现在世界上只有两个token即A和B。在Decoder产生第一个distribution的时候,A的几率是0.6,B的几率是0.4。在Decoder的时候我们选几率最大的一个。所以就往左边走,因为输出的结果会是下一次产生输出时候的输入,也就是如果第一次输出了A,会影响到接下来Decoder的结果。最后我们走出这条路径的策略就是贪心搜索。
但是贪心搜索不一定能帮我们找到输出最大的那个结果。
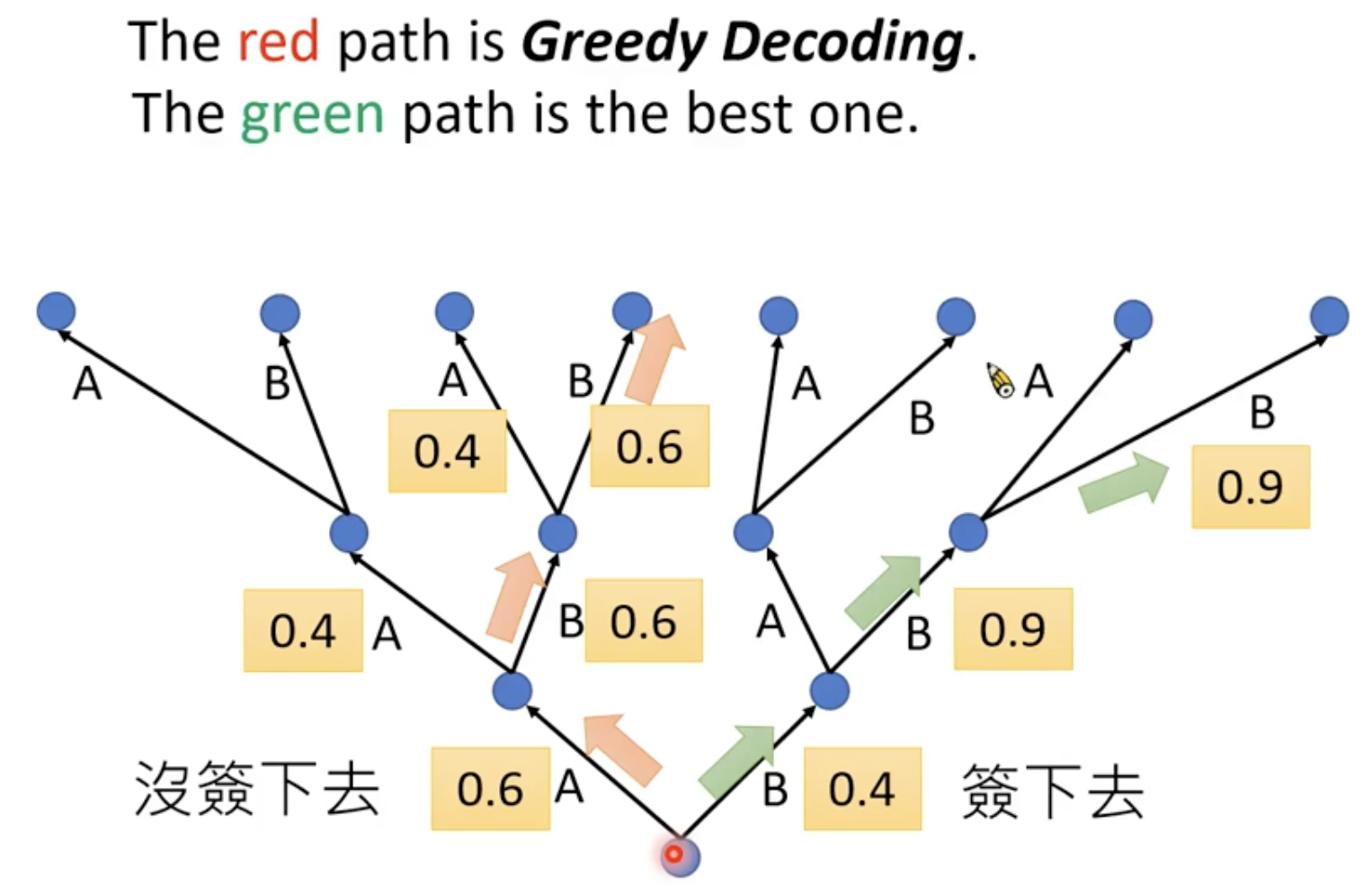
Beam Search
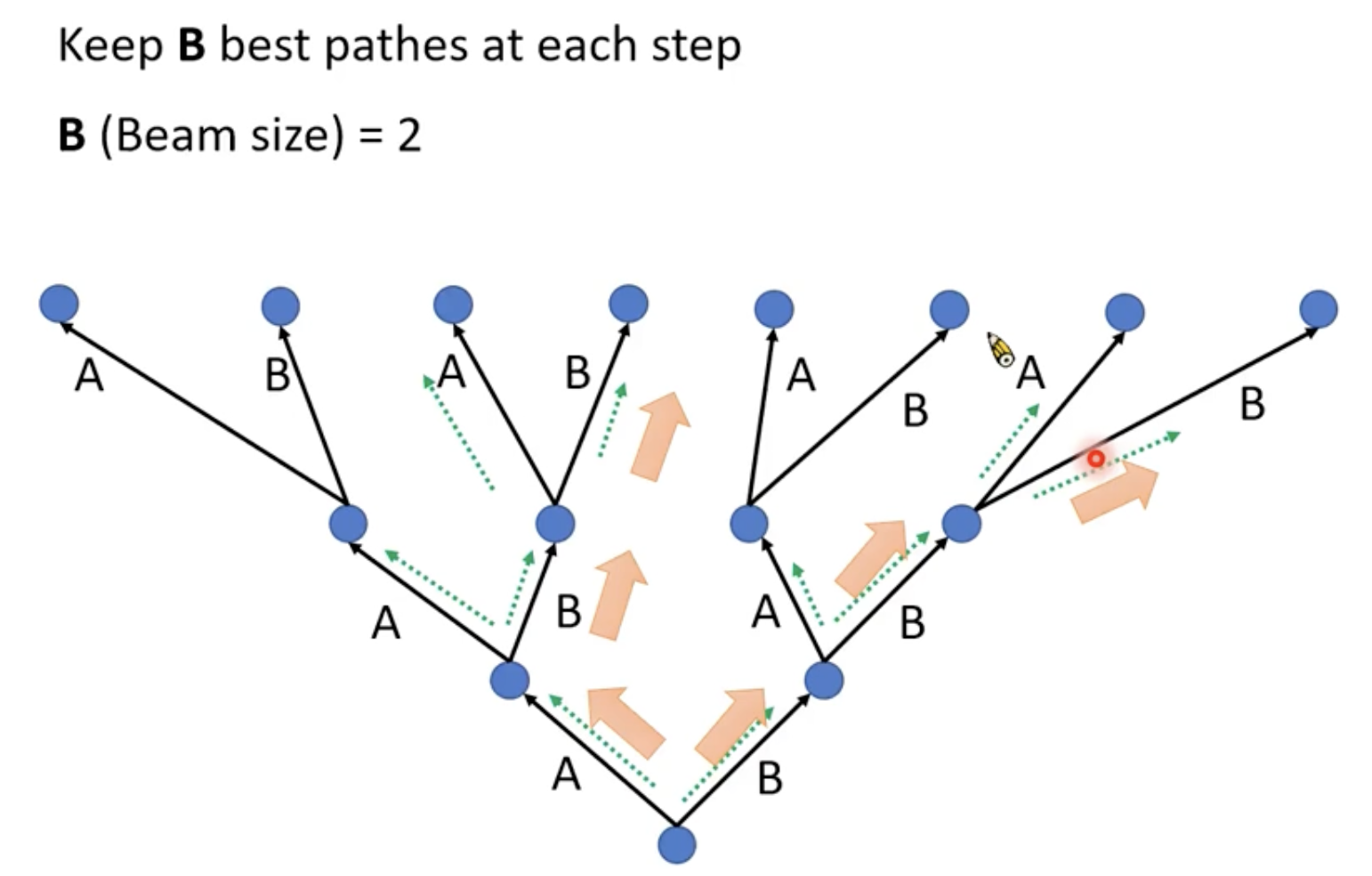
BeamSearch其实也不能保证找到的结果一定是全局最优,但是效果已经是比贪心算法更好的。关于B这个超参数,就需要我们自己来尝试了
训练过程
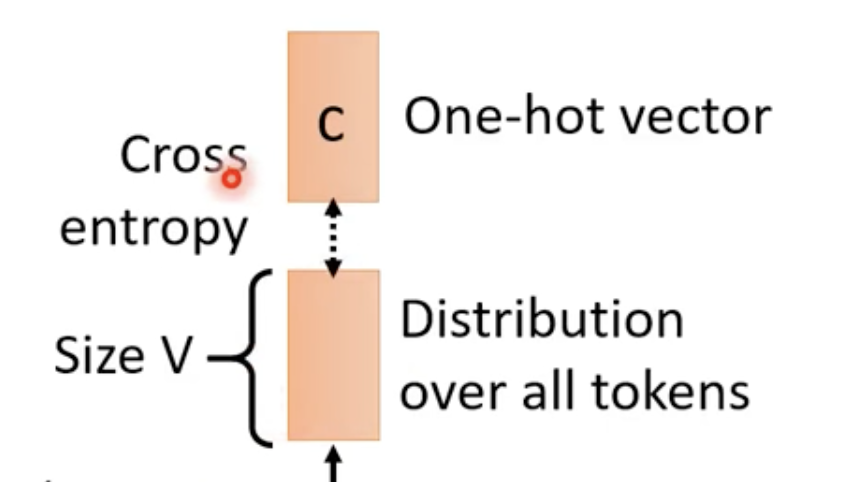
让输出的结果和One-hot vector做交叉熵,这就是我们的训练目标。
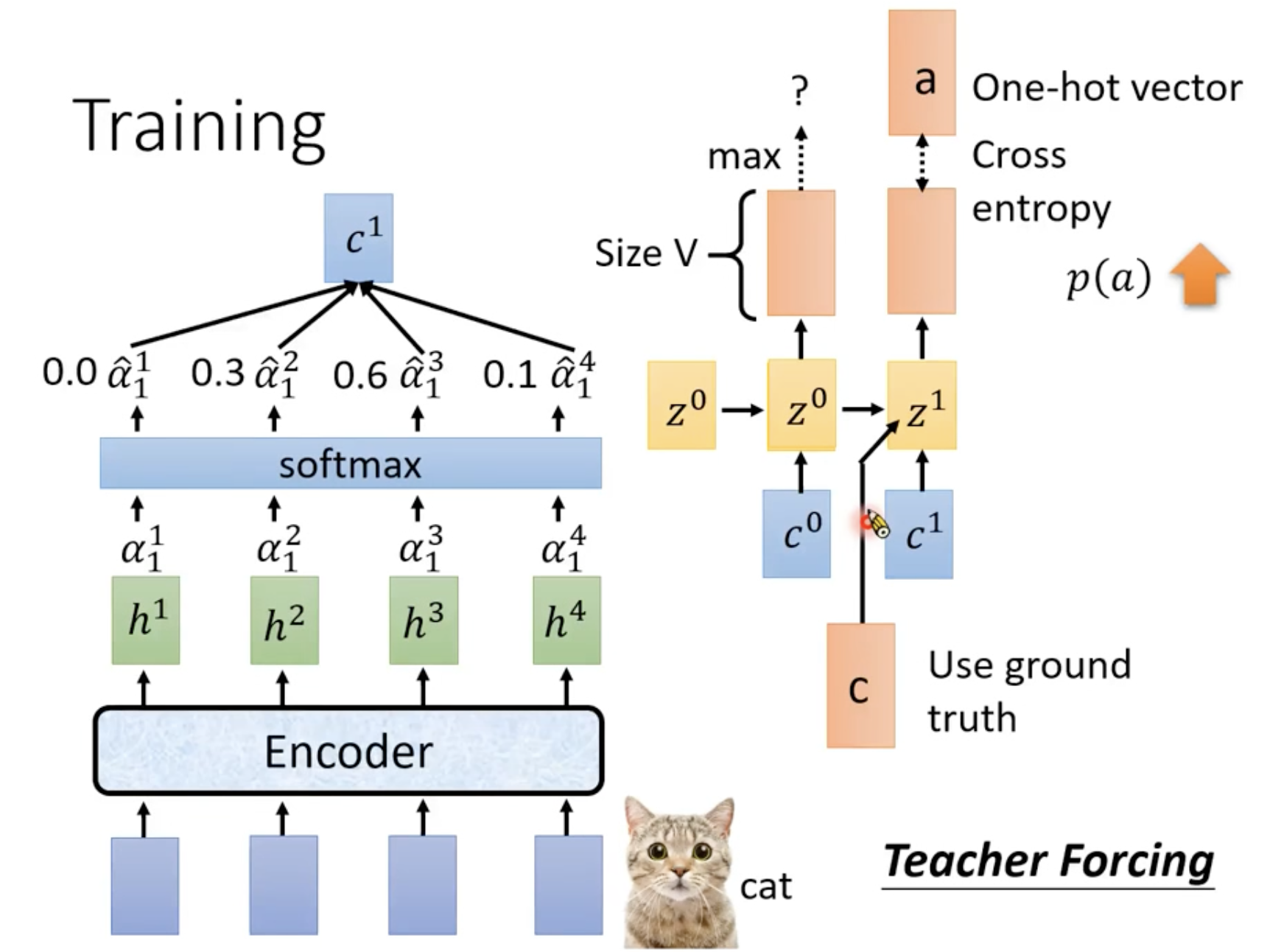
Teacher Forcing
在训练阶段,我们一般不会拿第一个字母直接预测第二个字母,这是模型的推理阶段,训练时我们在产生第二个字母的时候,会直接拿正确答案中的第一个字母来喂给第二个hidden state
Why Teacher Forcing?
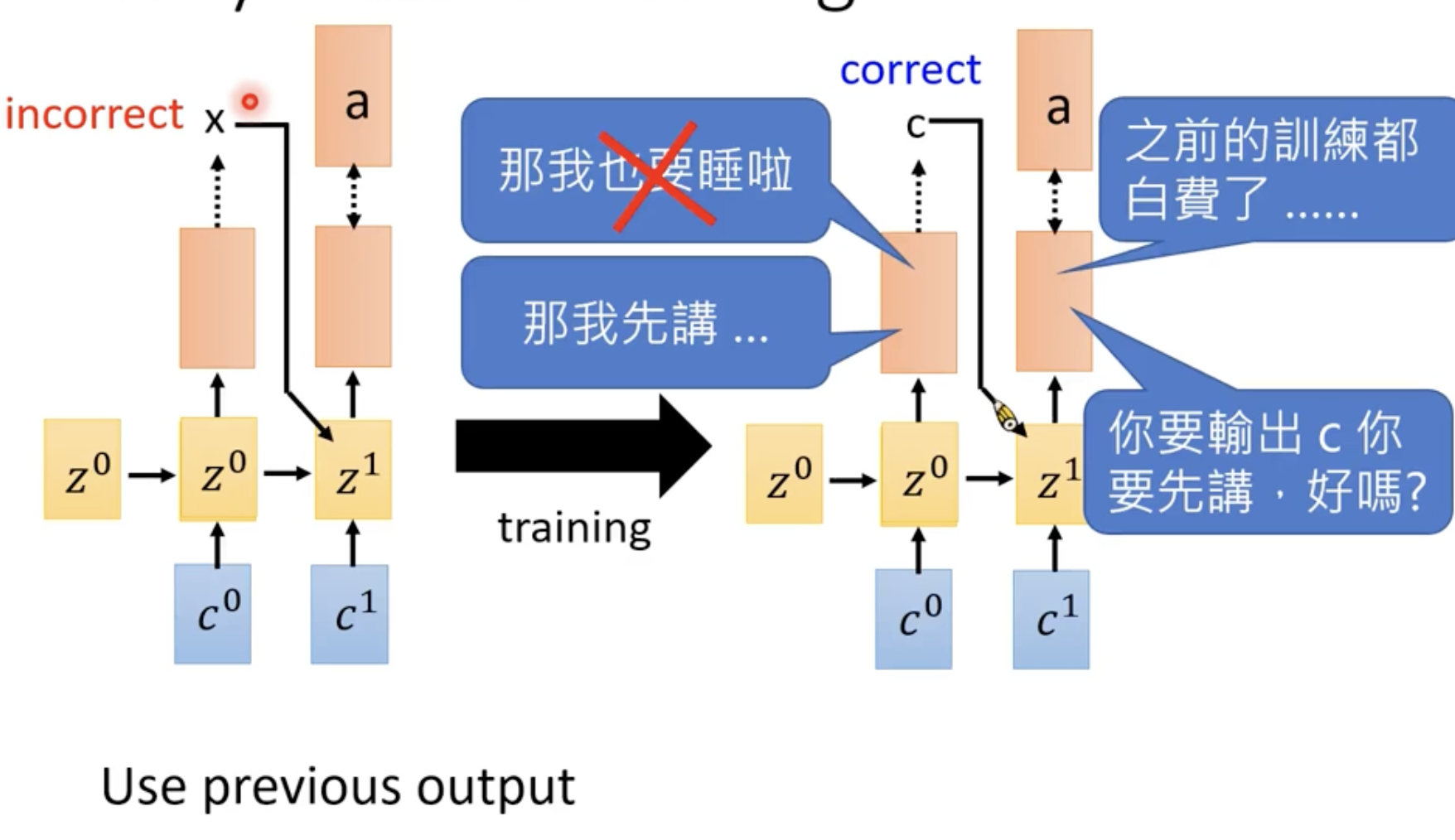
什么叫先讲呢,就是直接把正确答案打进来。
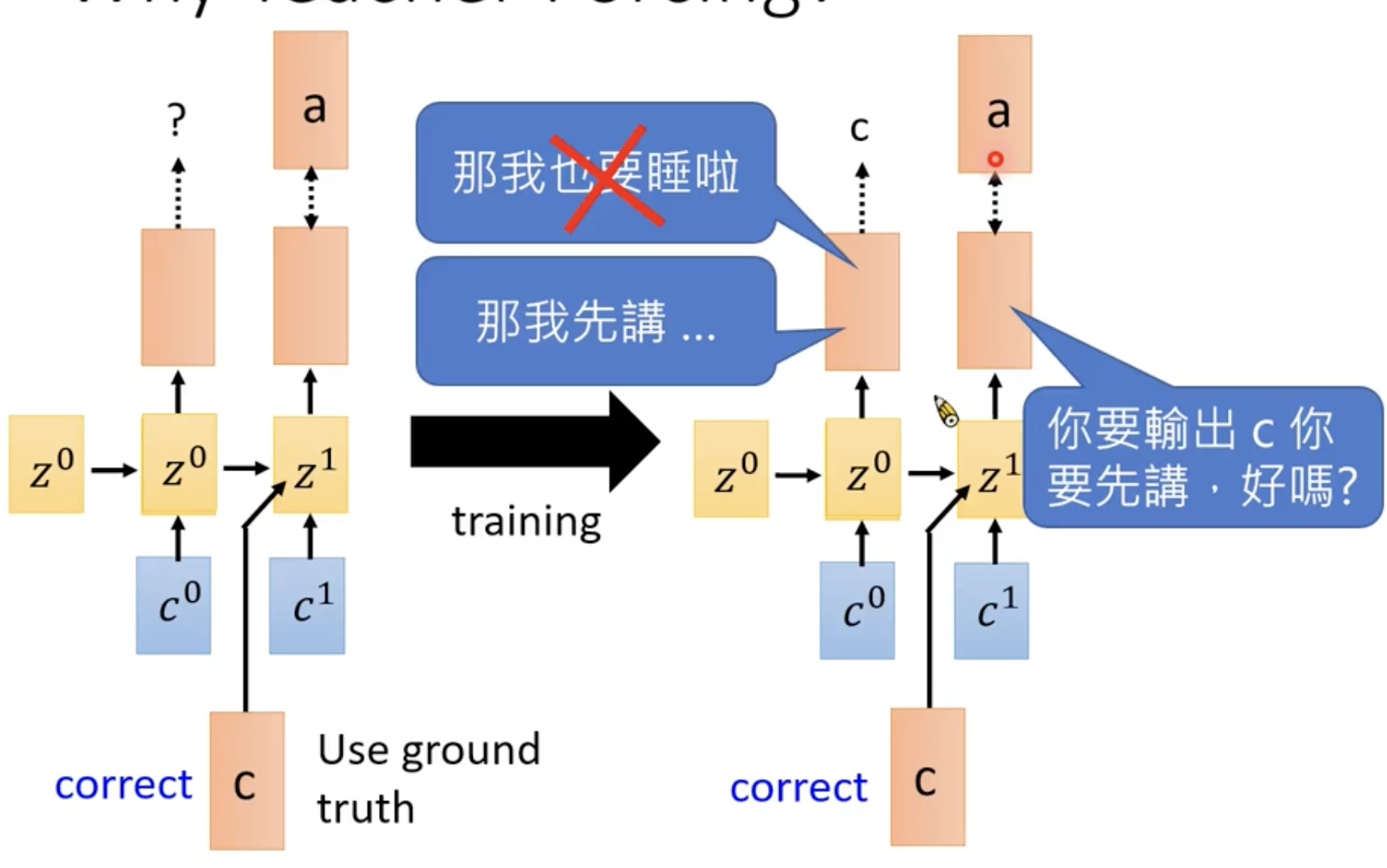
在Seq2Seq的过程中,Teacher Forcing是很重要也是很常用的方法。
Back to Attention
有两种Attention与RNN结合的常见架构:
一个是当前attention的值给后一时刻使用,另一种是当前attention的值给当前时刻使用。
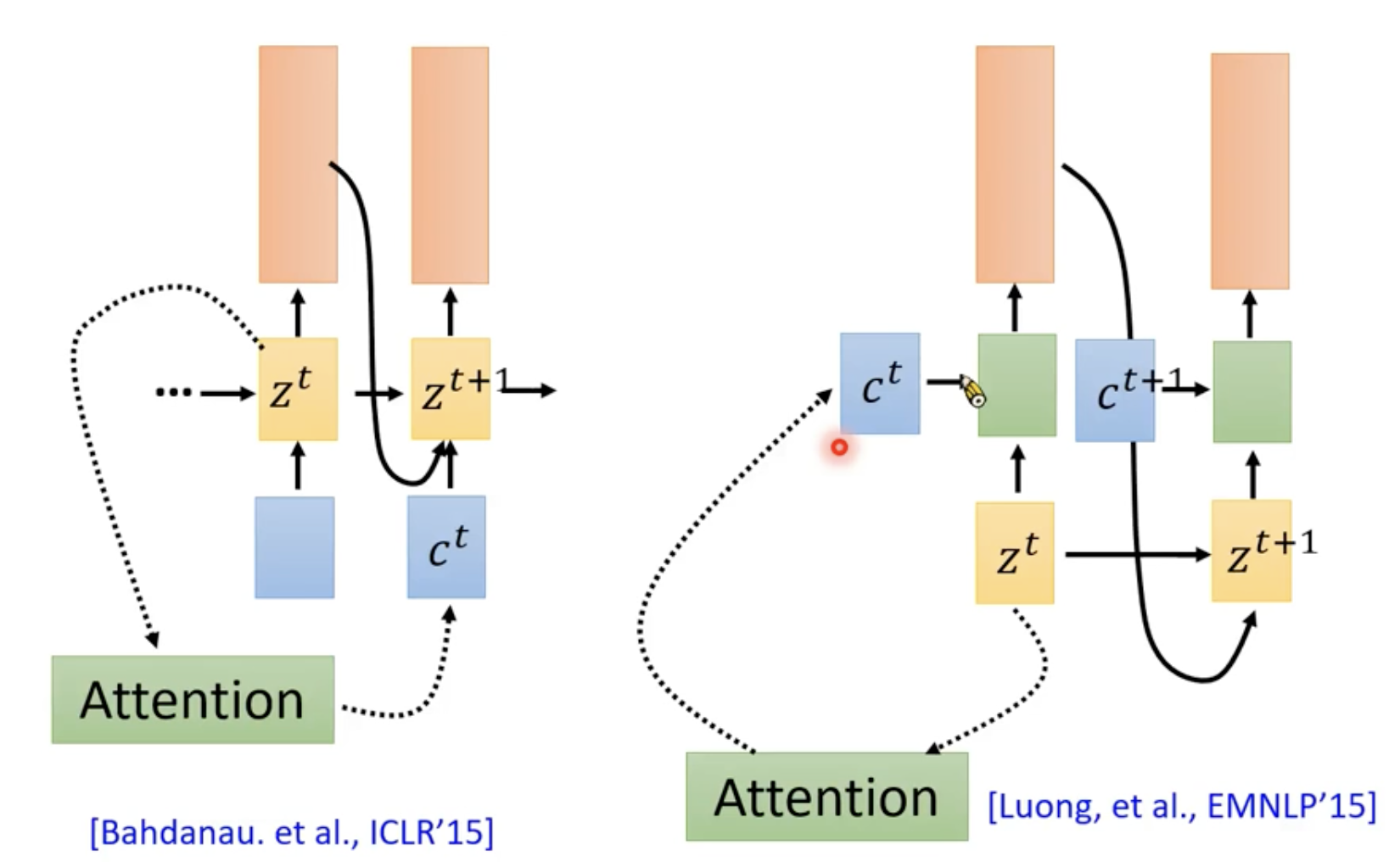
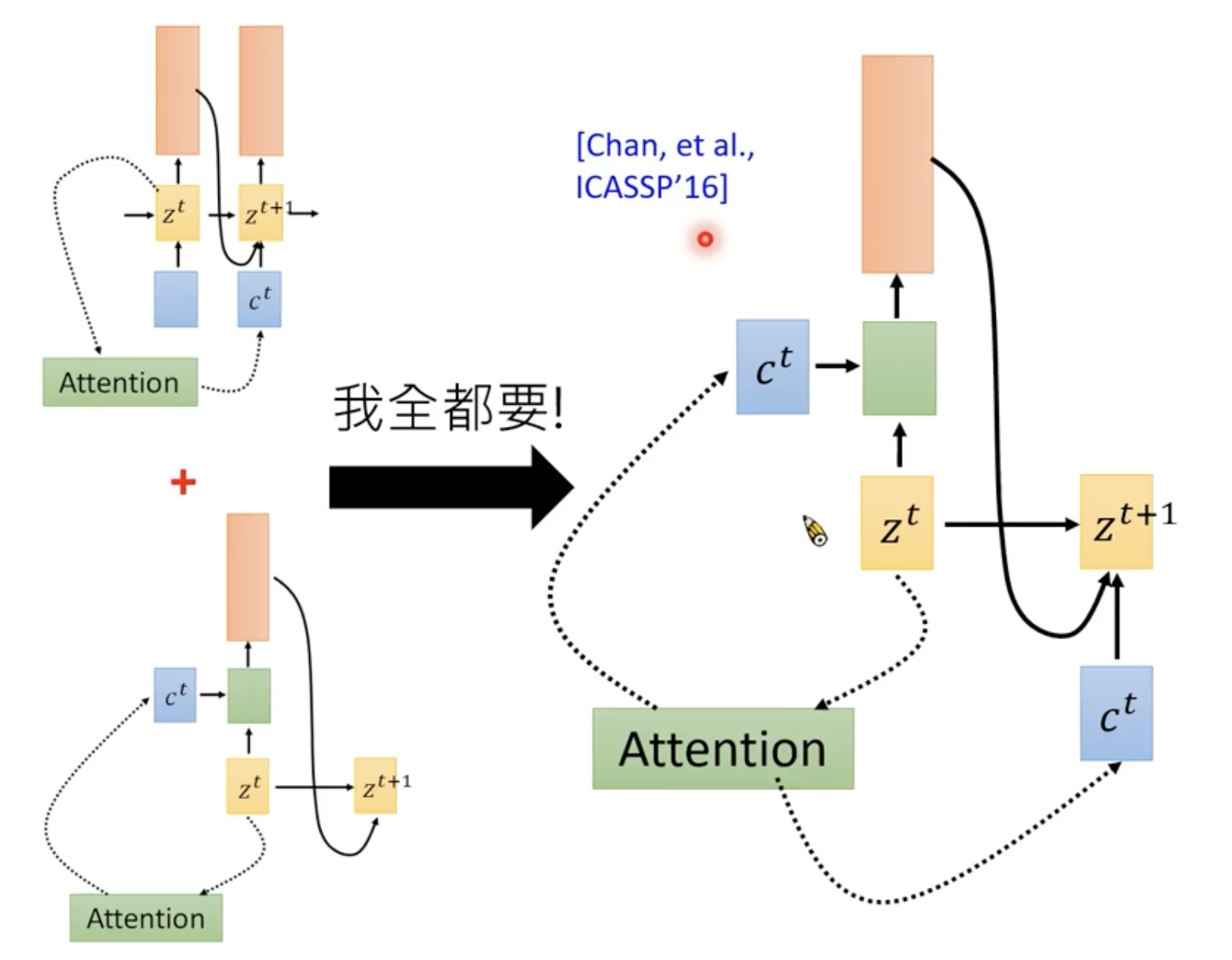
第一个拿attention做语音的论文,是两个都用了
课中李宏毅老师:其实对语音的Seq2Seq形式来说,不同于翻译,翻译的输入输出可能并不是对应的,而且某个token的翻译可能是有其前后文决定的,但是对于语音来说,由于它生成token是一个接一个的,所以在语音中用attention有一种杀鸡用牛刀的感觉。
但是我认为,语言的同音字挺多的,其实也需要部分的上下文来觉得这个字是什么,并且,这样我认可可以更好得排除噪音的干扰。
但是神奇的是作者的想法和李老师一样
Location- aware Attention
语音中的attention不能随便乱调,attention要考虑前一个
现在要找 z 1 z^1 z1和 h 2 h^2 h2的attention,不能直接算
应该是把前一个过程中的 h 2 h^2 h2的前后相关的attention都拿出来,放到一个process history(Transform)中,在一同得到目前的attention

Limitation of LAS
- LAS outputs the first token after listening the whole input.
- Users expect on-line speech recognition

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









