







 网络认为Hive中with as可缓存数据、减少表扫描和优化速度,本文通过实验进行分析。编写简单语句,结果显示reflect函数执行两次,执行计划产生两个map,证明with as不能减少表扫描。还将语句在Oracle执行对比,sys_guid()函数仅执行一次。
网络认为Hive中with as可缓存数据、减少表扫描和优化速度,本文通过实验进行分析。编写简单语句,结果显示reflect函数执行两次,执行计划产生两个map,证明with as不能减少表扫描。还将语句在Oracle执行对比,sys_guid()函数仅执行一次。
网络上搜索到的结果,都是说with as可以有缓存数据,减少表扫描,优化速度的作业,其实并不是这样,以下通过实验分析和证明
写一个很简单的语句:
with t as(
select regexp_replace(reflect("java.util.UUID", "randomUUID"), "-", "") AS id --生成一个随机id
,'andy' as name
)
select * from t
union all
select * from t
;执行结果:
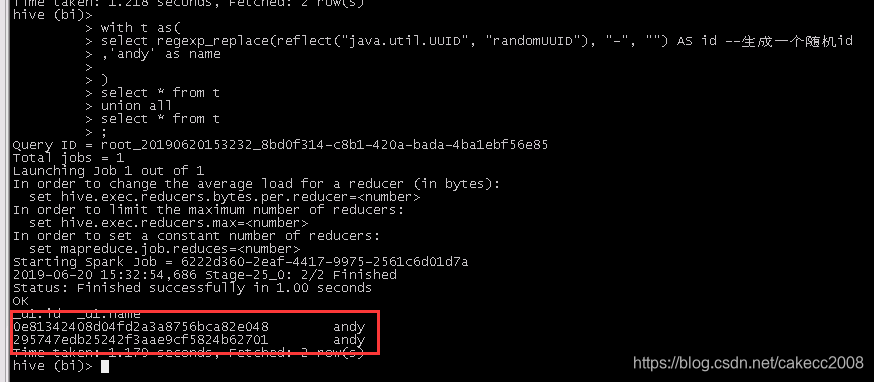
结果中可以看到,产生了两个不一样的id,说明reflect函数被执行了两次,即with as中的子查询被执行了两次。
再来看下执行计划:
hive (bi)>
> explain
> with t as(
> select regexp_replace(reflect("java.util.UUID", "randomUUID"), "-", "") AS id --生成一个随机id
> ,'andy' as name
> )
> select * from t
> union all
> select * from t
> ;
OK
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Spark
DagName: root_20190620153535_78057156-80df-4c9b-8c8e-f896ad4d74ed:53
Vertices:
Map 1
Map Operator Tree:
TableScan
alias: _dummy_table
Row Limit Per Split: 1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
Select Operator
expressions: regexp_replace(reflect('java.util.UUID','randomUUID'), '-', '') (type: string), 'andy' (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
File Output Operator
compressed: true
Statistics: Num rows: 2 Data size: 2 Basic stats: COMPLETE Column stats: COMPLETE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Map 2
Map Operator Tree:
TableScan
alias: _dummy_table
Row Limit Per Split: 1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
Select Operator
expressions: regexp_replace(reflect('java.util.UUID','randomUUID'), '-', '') (type: string), 'andy' (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
File Output Operator
compressed: true
Statistics: Num rows: 2 Data size: 2 Basic stats: COMPLETE Column stats: COMPLETE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.063 seconds, Fetched: 50 row(s)从执行计划中可以看到,产生了两个map。
所以说,with as是不能减少表扫描的。
为了对比,将以上语句稍作修改,然后在oracle中执行。结果如下:
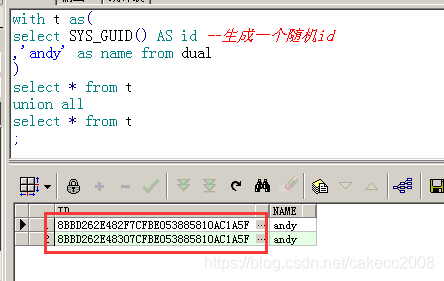
可以看到在oracle中,sys_guid()函数只被执行了一次。


















 7327
7327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











