







一 概述
当我们使用百度进行关键字搜索的时候,只要我们在搜索引擎的搜索框中,输入要搜索的文字的某一部分的时候,搜索引擎就会自动弹出下拉框,并进行关键词相关的提示,一定程度上节省了我们的搜索时间。
这种功能底层实现的数据结构就是字典树:Trie树。
二 字典树(Trie)
Trie树是一种专门处理字符串匹配的树形数据结构,经常用来解决在一组字符串集合中快速查找某个字符的问题。因为字典树相比于散列表,红黑树,或者其他字符串匹配算法有着独特的优点。
在进行字符串查找的过程中,通过直接拿要查找的字符串同需要查找的字符串所在集合进行字符串注意匹配时,那效率就会比较低。此时我们可以先对该字符串集合进行预处理,组织成Trie树的结构,之后每次查找,都是在Trie树中进行匹配查找。
Trie树的本质是利用字符串之间的公共前缀,将重复的前缀合并在一起。其中,根节点不包含任何信息,每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径就表示一个字符串,红色节点并都是叶子节点,如:go和good中的第一个o和d字符都是红色,但是第一个o并不是叶子节点,仅仅是字符串go的尾字符。
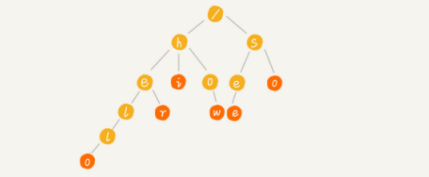
Trie是一个多叉树的数据结构,对于树结构中的二叉树是一种比较常见的树结构,二叉树的左右节点是可以通过两个不同的指针进行存储,但是对于多叉树来说该方式就无法满足要求,我们可以借助散列表的思想,我们通过一个下标与字符一一映射的数组,来存储节点的指针。

如果我们的字符串中只有从a到z的26个小写字母,我们在数组中下标为0的位置,存储指向节点a的指针,下标为1的位置存储指向子节点b的指针,以此类推,下标为25的位置,存储的是指向的子节点z的指针。如果某个字符的子节点不存在则其对应的下标位置存储null。
当我们在Trie树中查找字符串的时候,我们就可以通过字符的ASCII码减去a的ASCII码,迅速找到匹配的子节点的指针。如c的ASCII码减去a的ASCII码结果为2,那子节点c的指针就存储在数组下标为2的位置中。
在一组字符串中频繁地查询某些字符串,用Trie树会非常高效。构建Trie树的过程,需要扫描所有的字符串,所需的时间复杂度为O(n)(n表示所有字符串的长度和)。但是一旦构建成功,后续的查询操作会非常高效。
每次查询时,如果要查询的字符串长度为k,那我们需要比较大约k个节点,就能完成查询操作。跟原本那组字符串的长度和个数没有任何关系。故,构建好Trie树后,在其中查找字符串的时间复杂度为O(k),k表示要查找的字符串的长度。















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









