




目录
(1)背景分析WordCount(单词统计)是最简单也是最能提现MapReduce思想的程序之一,可以称为MapReduce版“HelloWorld"。
在当今这个数据驱动的时代,大数据分析已经成为各行各业不可或缺的一部分。面对海量数据的处理需求,MapReduce编程模型以其独特的分布式计算框架,成为了处理大规模数据集的得力助手。本文将带领读者深入探索MapReduce的核心概念、工作原理、实际应用以及优势,并通过详细的示例代码,让读者轻松掌握这一经典的大数据知识点。
一、MapReduce初印象
2.1 MapReduce分布式计算原理
MapReduce对外提供了5个可编程组件,分别是InputFormat、Mapper、Partitioner、Reducer、OutputFormat。由于这些组件在MapReduce内部都有默认实现,一般情况下不需要自己开发,只需要实现Mapper和Reducer组件即可。
2.2 MapReduce编程模型
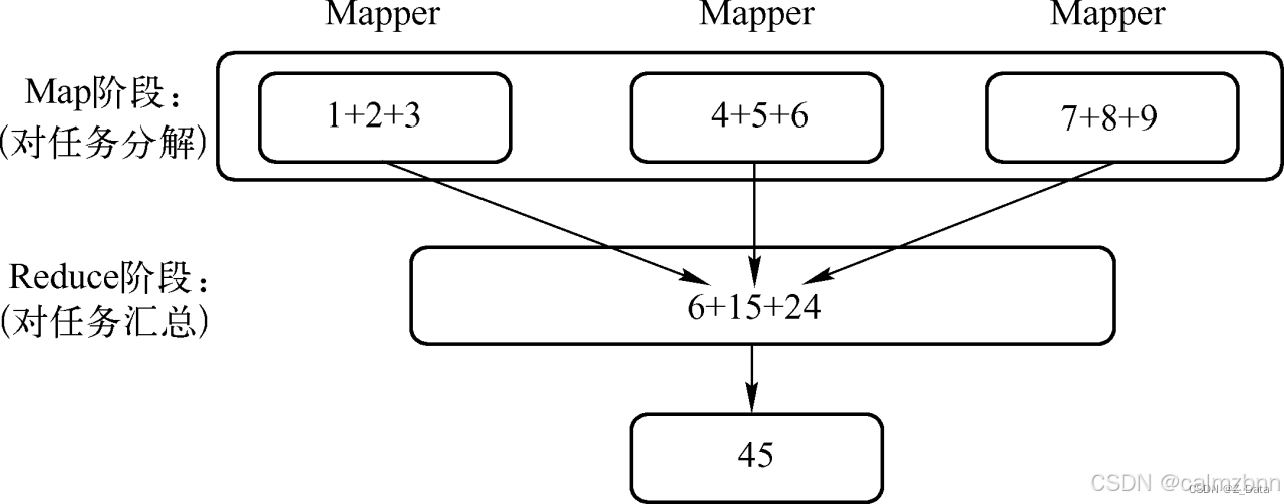
MapReduce编程模型可以分为Map和Reduce阶段。
- Map阶段:这个阶段的主要任务是将输入数据分割成独立的块,并并行处理这些块。每个Map任务都会读取输入数据,将其转换为键值对(key-value pairs),并输出中间结果。
- Reduce阶段:在Map阶段之后,Reduce阶段会对这些中间结果进行聚合处理。Reduce任务会接收具有相同键的所有值,并对这些值进行归约操作(如求和、计数等),最终输出处理结果。
2.3 深入剖析MapReduce编程模型
(1)背景分析
WordCount(单词统计)是最简单也是最能提现MapReduce思想的程序之一,可以称为MapReduce版“HelloWorld"。
为了验证Hadoop集群环境是否安装成功,已经成功运行过WordCount,这里主要从WordCount代码的角度对MapReduce编程模型进行详细分析。WordCount主要完成的功能是统计一系列文本文件中每个单词出现的次数,其实现逻辑如图:
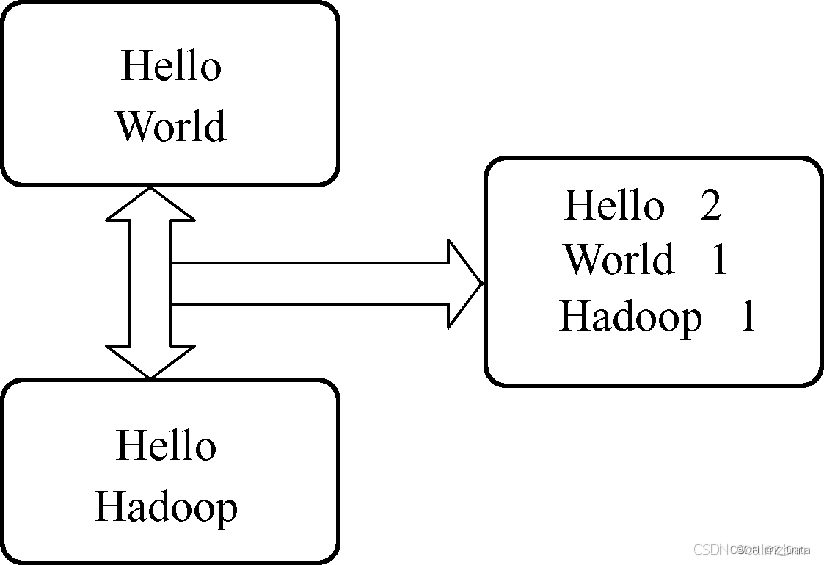
(2)问题思路分析
业务场景
有大量的文件,每个文件里面存储的都是单词。
我们的任务
统计所有文件中每个单词出现的次数。
解决思路
先分别统计出每个文件中各个单词出现的次数,然后再累加不同文件中同一个单词出现次数。
(3)深入剖析MapReduce编程模型
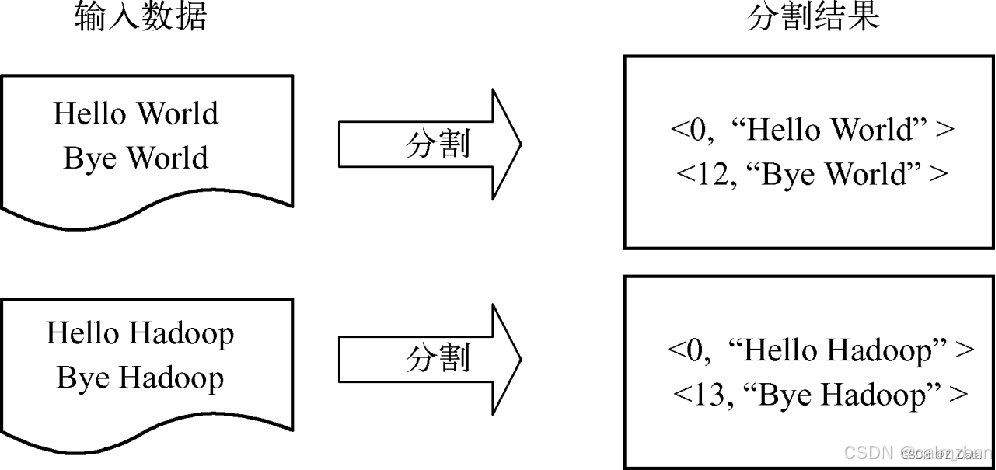
数据分割
首先将数据文件拆分成分片(Split),分片是用来组织数据块(Block)的,它是一个逻辑概念,用来明确一个分片包含多少个数据块,以及这些数据块存储在哪些DataNode节点上,但它并不实际存储源数据。
源数据以数据块的形式存储在文件系统上,分片只是连接数据块和Map 任务的一个桥梁。源数据被分割成若干分片,每个分片作为一个Map任务的输入。在Map函数执行过程中,分片会被分解成一个个<key,value>键值对,map函数会迭代处理每条数据。默认情况下,当输入文件较小时,每个数据文件将被划分为一个分片,并将文件按行转换成<key,value>键值对,这一步由MapReduce框架自动完成。
数据分割过程如图:
数据处理
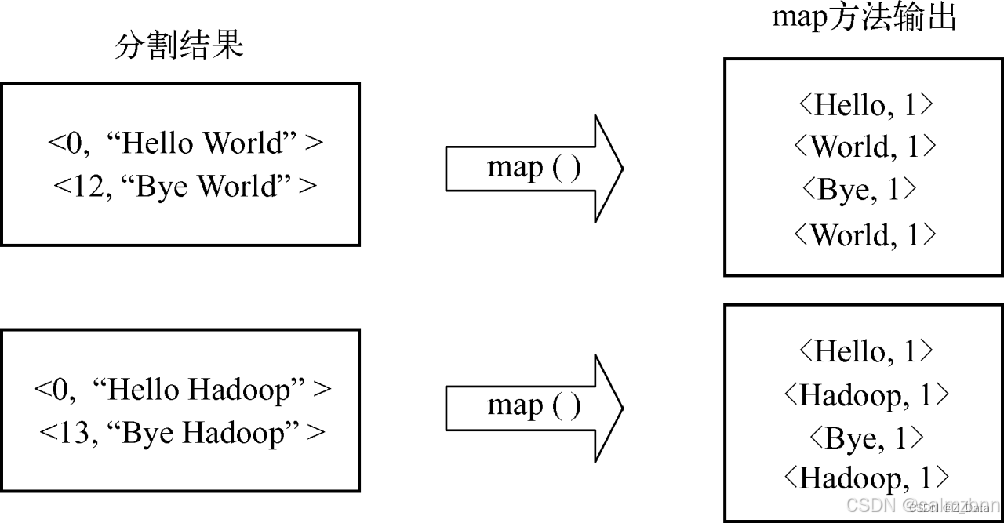
将分割好的<key,value>键值对交给用户自定义的map函数进行迭代处理,然后输出新的<key,value>键值对。
数据处理过程如图:
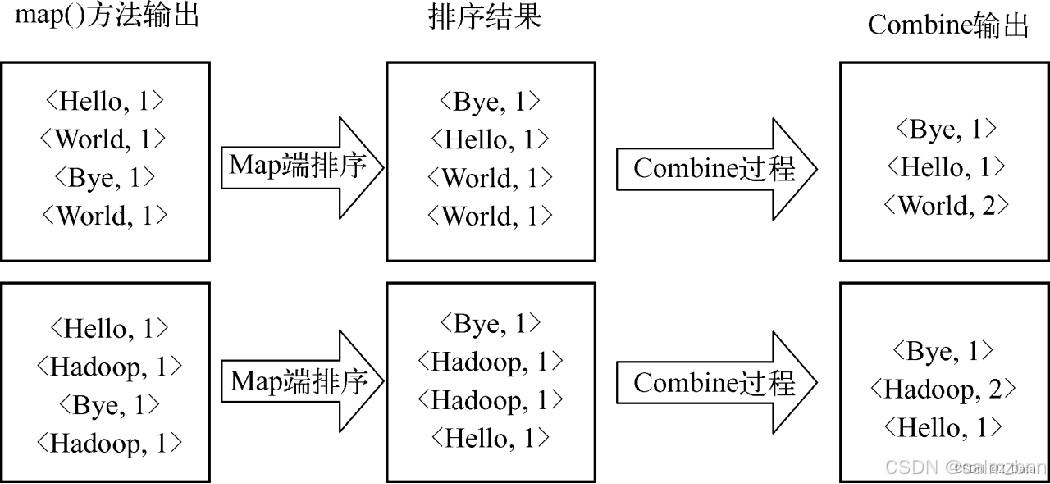
数据局部合并
在Map任务处理后的数据写入磁盘之前,线程首先根据Reduce个数对数据进行分区。在每个分区中,后台线程按key值在内存中排序,如果设置了Combiner,它就在排序后的输出上运行。运行Combiner使得Map输出结果更少,从而减少写到磁盘的数据和传递给Reduce的数据。
数据局部合并过程如图:
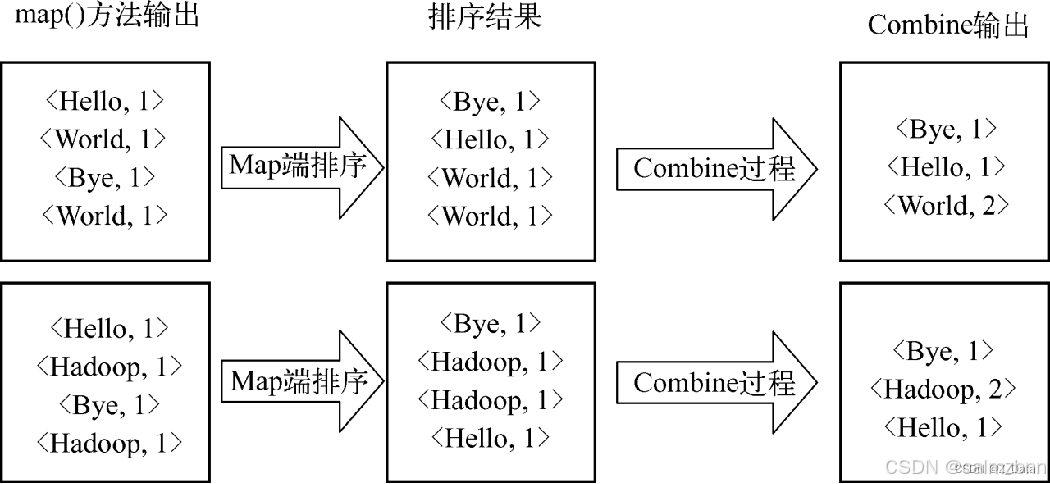
数据聚合
经过复杂的Shuffle过程之后,将Map端的输出数据拉取到Reduce端。Reduce端首先对数据进行合并排序,然后交给reduce函数进行聚合处理。注意,相同key的记录只会交给同一个Reduce进行处理,只有这样才能统计出最终的聚合效果。
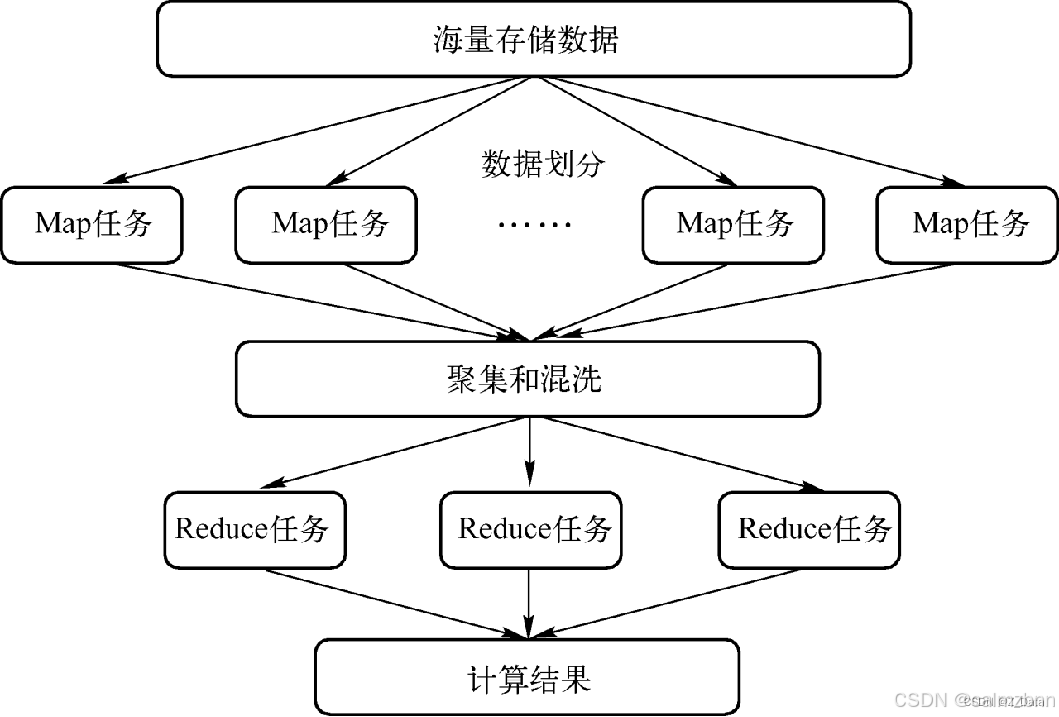
二、MapReduce工作原理详解
MapReduce的工作流程可以细分为以下几个步骤,每个步骤都承载着特定的任务,共同协作完成数据的处理:
- 输入分割:首先,MapReduce框架会将输入数据分割成多个数据块,这些数据块将作为Map任务的输入。
- Map任务执行:对于每个数据块,MapReduce框架都会启动一个Map任务来对其进行处理。Map任务会读取输入数据块,将其转换为键值对,并输出中间结果。
- Shuffle和Sort:在Map任务完成后,MapReduce框架会对中间结果进行按键排序和分组。这个过程被称为Shuffle和Sort。它的目的是确保具有相同键的所有值被发送到同一个Reduce任务。
- Reduce任务执行:对于每个键值对组,MapReduce框架都会启动一个Reduce任务来对其进行处理。Reduce任务会接收这些键值对组,并对它们进行归约操作,最终输出处理结果。
- 输出合并:最后,MapReduce框架会将所有Reduce任务输出的结果合并成一个最终的文件或数据库。
三、MapReduce的优势与应用
MapReduce之所以能够在大数据处理领域占据一席之地,离不开其独特的优势:
- 易于编程:MapReduce将复杂的分布式计算抽象为简单的Map和Reduce函数,降低了编程难度,使得开发者能够更加专注于业务逻辑的实现。
- 高度可扩展性:MapReduce框架能够自动处理数据的分割、任务的调度和结果的合并,支持大规模数据集的并行处理,具有高度的可扩展性。
- 容错性强:MapReduce框架具有自动的故障恢复机制,能够在任务失败时重新分配任务,确保计算的正确性。这种容错性使得MapReduce在处理大规模数据集时更加可靠。
在实际应用中,MapReduce被广泛应用于各种场景,如搜索引擎的索引构建、日志分析、推荐系统、数据分析等。它不仅能够处理海量数据,还能够提供高效、准确的计算结果。
四、MapReduce示例代码解析
为了更好地理解MapReduce的工作原理和实际应用,下面我们将通过一个简单的示例代码来展示如何使用MapReduce进行词频统计。
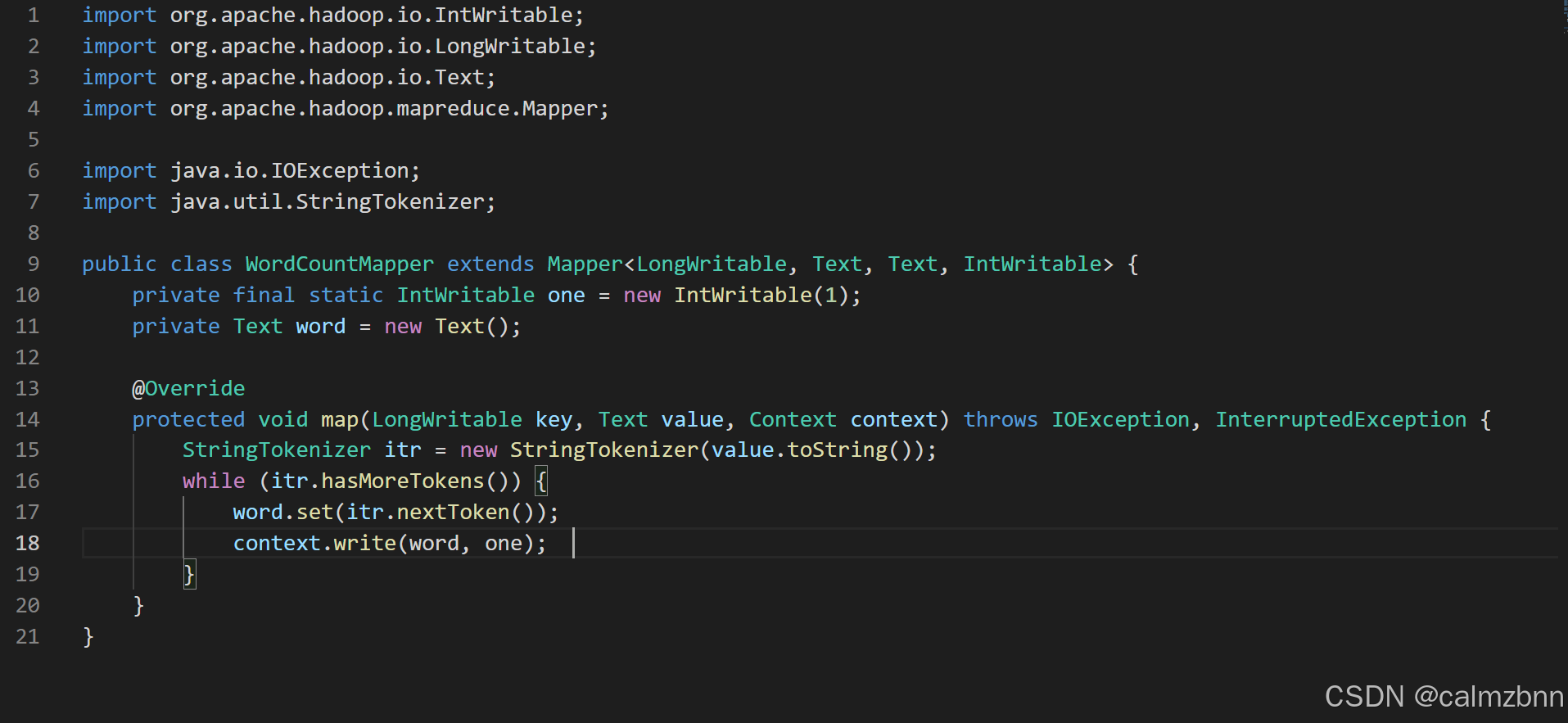
Mapper类代码解析
Reducer类代码解析
在Reducer类中,我们定义了一个reduce方法,它接收一个文本类型的键(表示单词)、一个可迭代的整型值集合(表示该单词在所有Map任务中出现的次数)和一个上下文对象。在reduce方法中,我们遍历values集合,对每个值进行累加,得到该单词的总出现次数,并将结果写入上下文。
Driver类代码解析
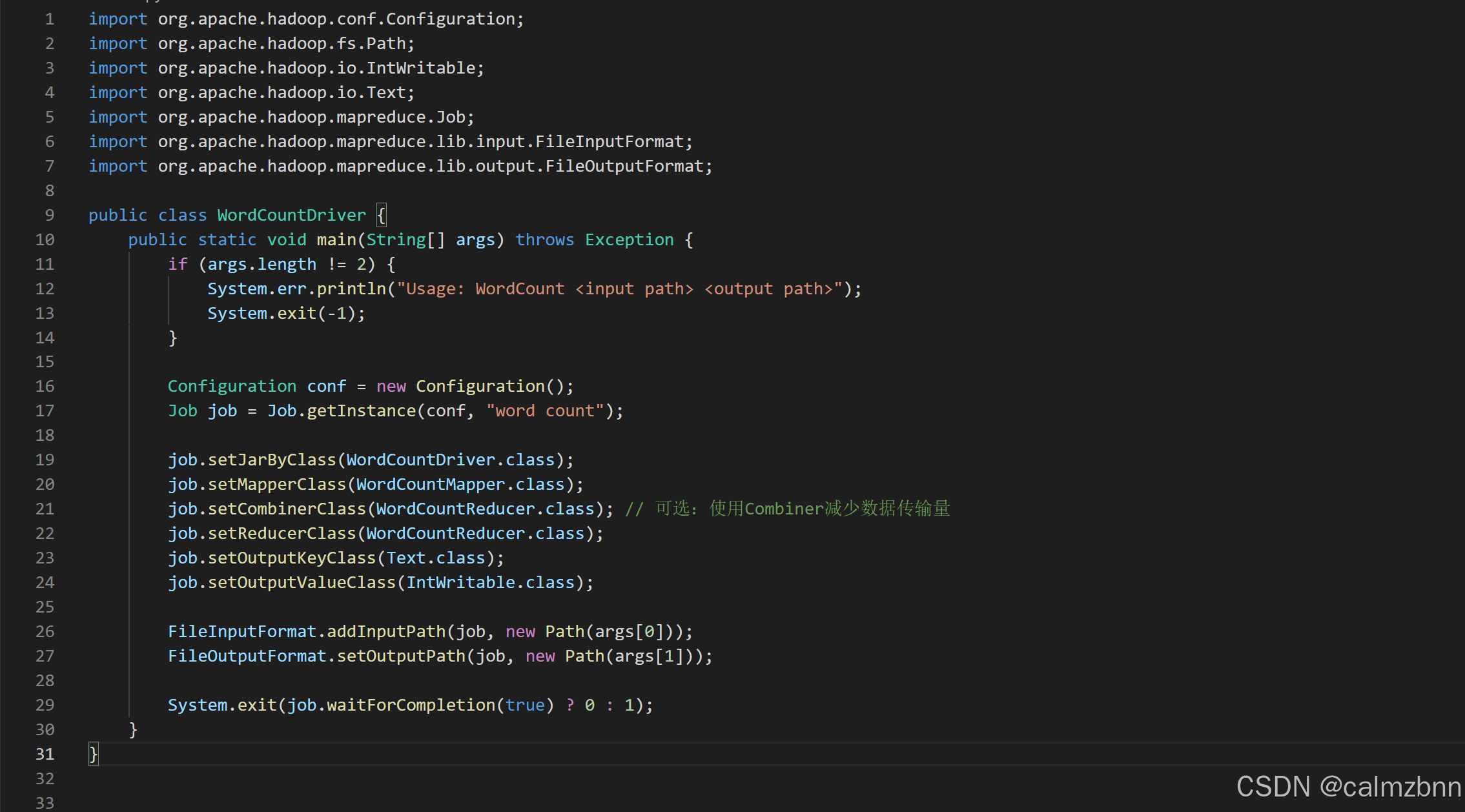
在Driver类中,我们定义了main方法作为程序的入口。在main方法中,我们首先检查输入参数的数量是否正确,然后创建配置对象和作业对象,并设置作业的相关属性。接着,我们设置输入和输出路径,并提交作业到Hadoop集群进行执行。最后,我们等待作业完成,并根据作业的完成情况返回相应的退出码。
五、总结与展望
通过本文的深入探索,相信读者已经对MapReduce编程模型有了更加全面的了解。从MapReduce的核心概念到工作原理,再到实际应用和优势,本文都进行了详细的介绍和解析。同时,通过示例代码的展示和解析,读者也能够更加直观地理解MapReduce的工作原理和实际应用。
在未来的大数据处理领域,MapReduce将继续发挥其重要的作用。随着技术的不断发展,MapReduce也将不断演进和完善,以更好地适应大数据处理的需求。希望读者能够掌握MapReduce编程模型,并在实际项目中灵活运用这一经典的大数据知识点,为企业的数据分析和决策提供有力支持。

















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









