






在学习cs231n课程,边看课程讲义边做笔记,记录在这里
1. 线性分类
K-NN分类器的缺点:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
- 对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
概述:
这种方法主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
2. 线性分类器(评分函数)
在CIFAR-10中,我们有一个N=50000的训练集,每个图像有D=32x32x3=3072个像素,而K=10,这是因为图片被分为10个不同的类别(狗,猫,汽车等)
一个线性映射: f(xi, W, b) = Wxi + b
每个图像数据都被拉长为一个长度为D的列向量,大小为[D x 1]。
该函数的参数(parameters):
矩阵W:大小为[K x D]
列向量b:大小为[K x 1]
还是以CIFAR-10为例,xi包含了第i个图像的所有像素信息,这些信息被拉成为一个[3072 x 1]的列向量,W大小为[10x3072],b的大小为[10x1]。因此,3072个数字(原始像素数值)输入函数,函数输出10个数字(不同分类得到的分值)。参数W被称为权重(weights)。b被称为偏差向量(bias vector),这是因为它影响输出数值,但是并不和原始数据产生关联。
这种方法的几个优点和注意点:
- 训练数据是用来学习到参数W和b的,一旦训练完成,训练数据就可以丢弃,留下学习到的参数即可。
- 只需要做一个矩阵乘法和一个矩阵加法就能对一个测试数据分类,这比k-NN中将测试图像和所有训练数据做比较的方法快多了。
但是这种方法的分类能力有点弱,因此要将偏差和权重合并。
刚刚的公式变为:
f(xi, W) = Wxi

以CIFAR-10为例,那么的大小就变成[3073x1],而不是[3072x1]了,多出了包含常量1的1个维度)。W大小就是[10x3073]了。中多出来的这一列对应的就是偏差值。
3. 损失函数 (代价函数Cost Function或目标函数Objective)
衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
多类支持向量机损失 Multiclass Support Vector Machine Loss (SVM):
针对第i个数据的多类SVM的损失函数定义如下:
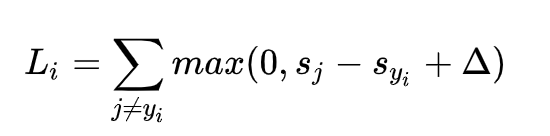
简而言之,SVM的损失函数想要正确分类类别的分数比不正确类别分数yi高,而且至少要高∆。如果不满足这点,就开始计算损失值。
对于线性评分函数,改写一下:
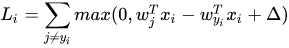
上面公式里包含的一个函数max (0, -),叫做折叶损失(hinge loss)。
我们对于预测训练集数据分类标签的情况总有一些不满意的,而损失函数就能将这些不满意的程度量化

- 如果分类分数进入了红色的区域,甚至更高,那么就开始计算损失。
- 如果没有这些情况,损失值为0。
正则化(Regularization):
过拟合现象(训练集表现很好,测试集表现较差),需要用正则化降低模型复杂度。
最常用的正则化惩罚是L2范式,L2范式通过对所有参数进行逐元素的平方惩罚来抑制大数值的权重:
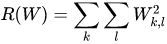
因此完整的多类SVM损失函数由两个部分组成:数据损失(data loss),即所有样例的的平均损失Li,以及正则化损失(regularization loss),其中,N是训练集的数据量。
举个例子:
假设输入向量 x=[1, 1, 1, 1],两个权重向量 w1=[1, 0, 0, 0],w2=[0.25, 0.25, 0.25, 0.25]。那么,两个权重向量
都得到同样的内积,但是的L2惩罚是1.0,而的L2惩罚是0.25。因此,根据L2惩罚来看,w2更好,因为它的正则化损失更小。从直观上来看,这是因为w2的权重值更小且更分散。既然L2惩罚倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。这一效果将会提升分类器的泛化能力,并避免过拟合。
Softmax分类器:
将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)
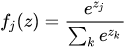
SVM和Softmax的区别图:

通过前面的推导就可以发现:
- SVM更加local objective,因为它只关心正确分类比不正确分类得到了比∆更大的值,损失值就是0。对数字具体多少并不关心。分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没什么不同。
- 对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。
与KNN不同的是,参数方法的优势在于一旦通过训练学习到了参数,就可以将训练数据丢弃了。
笔记参考来源:https://zhuanlan.zhihu.com/p/21930884















 1260
1260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









