






1任务描述
数据的准备工作,包括认识数据来源,分析数据集,了解数据集的特征、数量等属性,以及对数据集进行可视化。
2 iris数据集介绍
iris数据集是常用的分类实验数据集,由Fisher,1936收集整理。iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。鸾尾花具有花萼与花瓣,根据鸾尾花的花萼长度、花萼宽度、花瓣长度、花瓣宽度4项特征可将鸢尾花分为3种类别,分别为山鸢尾花(iris setosa)、变色鸢尾花(iris versicolor)和维吉尼亚鸢尾花(iris virginica)。如图1所示。

图1 鸾尾花4个特征及3种类别
iris数据集包含在sklearn库当中,具体在…\anaconda3 \Lib\site-packages\sklearn\datasets\data。打开iris.csv,数据格式如图2所示。
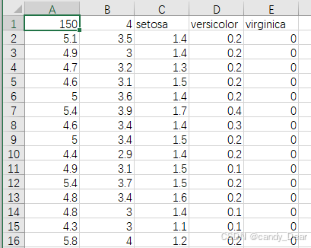
图2 iris数据集部分展示
iris数据集共150条记录,山鸢尾花、变色鸢尾花和维吉尼亚鸢尾花各50个数据,每条记录有花萼长度、花萼宽度、花瓣长度、花瓣宽度4项特征,通过这4个特征分类鸢尾花卉属于哪一品种。
图2所列数据含义:
第一行数据的含义为:
150 : 数据集中数据的总条数
4 : 特征值的类别数.即花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)。
setosa、versicolor、virginica:三种鸢尾花名,分别为山鸢尾花、变色鸢尾花和维吉尼亚鸢尾花。
从第二行及以下数据的含义为:
第1列为花萼长度值(sepal length)
第2列为花萼宽度值(sepal width)
第3列为花瓣长度值(petal length)
第4列为花瓣宽度值(petal width)
第5列对应是种类有,也称为标签(三种鸢尾花(山鸢尾花、变色鸢尾花和维吉尼亚鸢尾花)分别用O, 1,2表示)
3在sklearn库中导入iris数据集
1.iris数据集包含在sklearn库当中,只需要使用import导入即可,导入数据集代码如下:
from sklearn import datasets
iris = datasets.load_iris()
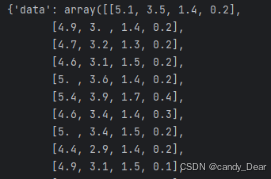
print(iris)代码运行结果部分截图:
2.datasets.load_iris().data和datasets.load_iris().target可以分别返回iris数据集所有输入特征和所有标签。具体代码如下:
from sklearn import datasets
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
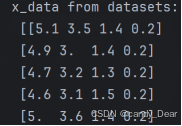
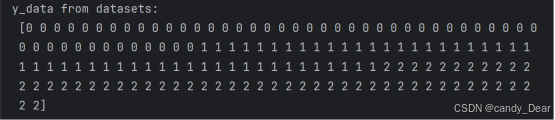
print('x_data from datasets: \n', x_data)
print('y_data from datasets: \n', y_data)运行结果部分截图:
3.为了更直观地看清iris数据集的信息,为数据集加上索引,代码如下:
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
print('x_data from datasets: \n', x_data)
print('y_data from datasets: \n', y_data)
x_data = DataFrame(x_data,columns=[ '花萼长度','花萼宽度','花瓣长度','花瓣宽度'])
pd.set_option( 'display.unicode.east_asian_width', True)
x_data['类别']= y_data
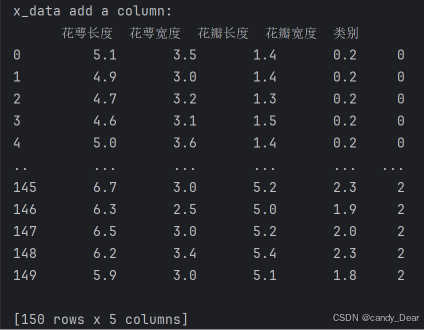
print( 'x_data add a column: \n', x_data)代码解析如下:
代码行8:为表格增加行索引(左侧)和列标签(上方)
代码行9:为设置列名对齐。
代码行10:新加一列,列标签为‘类别’,数据为y_data
运行结果截图如下:
4 数据可视化
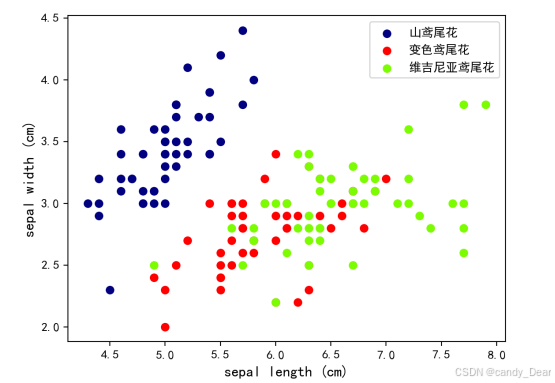
通过数据可视化,可以查看数据集内部特征之间的关系,观察到特征间分布关系。本次任务中鸾尾花数据集的可视化将通过散点图展现,散点图 (scatter plot)将二维样本数据以点的形式展现在直角坐标系上。
由于鸢尾花数据集的特征有四项,所以可以选择将四项特征每两项组合绘制。下列示例以花萼长度(sepal length)为x轴,花萼宽度(sepal width)为y轴绘制的散点图。
代码如下:
import matplotlib.pyplot as plt
import matplotlib as mp
from sklearn import datasets
mp.rcParams ['font.sans-serif'] =[u'SimHei ' ]
mp.rcParams [ 'axes.unicode_minus' ] = False
iris = datasets.load_iris()
x=iris.data[0:150,0:2]
y=iris.target[0: 150]
samples_0 = x[y==0,:]
samples_1 = x[y==1,:]
samples_2 = x[y==2,:]
plt.scatter(samples_0[:,0], samples_0[:,1 ],marker='o',color='navy',label='山鸢尾花')
plt.scatter(samples_1[:,0], samples_1[:,1 ],marker='o',color='r',label='变色鸢尾花')
plt.scatter(samples_2[:,0], samples_2[:,1 ],marke='o' ,color='lawngneen',label='维吉尼亚鸢尾花')
plt.xlabel( 'sepal length (cm) ' , fontsize=12)
plt.ylabel( 'sepal width (cm)',fontsize=12)
plt.legend()
plt.show()代码解析如下:
代码行1-3:导入画图绘图库matplotlib和sklearn。
代码行4-5:在图中显示中文。
代码行6:加载数据集
代码行7:取150个样本的前两列特征,花萼长度和宽度
代码行8:将标签取出。
代码行12-14:绘制散点图,samples_0[:,0]和samples_0[:,1]分别表示横坐标和纵坐标,marker表示点的形状,color表示线条颜色,lable表示标记图形内容的标签文本。
代码行15-16:用于设置x坐标轴、y坐标轴,fontsize表示字体大小。
运行结果如下:

















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









