






文本分析与挖掘上机报告
一、实验目的
1. 使用多层感知机对文本数据进行分类,对比不同预处理和参 数对分类结果的影响。
2. 熟悉多层感知机的分类过程
二、实验内容
把 20newsgroups(全部 20 个类)按 4:1 分成训练和测试集。再从训练集里面分出 10%作为验证集。
1.基于词袋表示为输入的多层感知机分类
a. 采用实验 3 中的预处理对训练集和测试集进行预处理并得到词袋表示。
b. 创建具有单层隐藏层(256 个节点)的多层感知机,设置激活函
数为 ReLu,初始学习率为 0.001,轮数 epoch 为 50,用训练集对模型进行训练,画出学习曲线(训练、验证损失以及准确率)。观察曲线,讨论模型的学习情况(欠拟合、过拟合)
c. 得到测试集准确率,并对比实验 3 中基于朴素贝叶斯算法的结果。
d. 尝试改变实验设置(增加隐藏层节点个数、增加层数、初始学习率、优化器、增加 epoch 数目等)来提升测试集准确率并讨论结果。
2.基于词嵌入为输入的多层感知机分类
得到训练集和测试集中每个词的 100 维词嵌入向量,可以调用gensim 或直接从 http://nlp.stanford.edu/data/glove.6B.zip 下载。
b.基于词向量得到的文档表示(直接对包含的词的向量平均或其他
方法)作为输入,重复上面 1(b-d)的内容,对比后进行讨论。
三、实验结果
把 20newsgroups(全部 20 个类)按 4:1 分成训练和测试集。再从训练集里面分出 10%作为验证集。
1.基于词袋表示为输入的多层感知机分类
a. 采用实验 3 中的预处理对训练集和测试集进行预处理并得到词袋表示。
b. 创建具有单层隐藏层(256 个节点)的多层感知机,设置激活函数为 ReLu,初始学习率为 0.001,轮数 epoch 为 50,用训练集对模型进行训练,画出学习曲线(训练、验证损失以及准确率)。观察曲线,讨论模型的学习情况(欠拟合、过拟合)
c. 得到测试集准确率,并对比实验 3 中基于朴素贝叶斯算法的结果。
d. 尝试改变实验设置(增加隐藏层节点个数、增加层数、初始学习率、优化器、增加 epoch 数目等)来提升测试集准确率并讨论结果。
a.b.d
选择TF-IDF的词袋文档分类(30维):
由于数据量过大,取TF-IDF向量时会运行出错,不使用本实验中要求的比例分配训练集和测试集,
本实验中训练集随机选择1000,测试集随机选择300,验证集选择100

转换为TF-IDF矩阵后,使用PCA对矩阵的维度进行降维:
XX = pca.fit_transform(weight)

降维之后,维度变为30维(维度大了,运行不了)
将训练集,测试集,验证集的TF-IDF矩阵均降至30维
网络模型如下,节点数选择500,256个节点训练出的网络效果较差:
epochs=100
learning_rate=0.001
model=tensorflow.keras.models.Sequential([
keras.layers.Dense(30),
keras.layers.Dense(500,activation='relu'),
keras.layers.Dense(20,activation='softmax')
])
sgd = tensorflow.keras.optimizers.SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=sgd,
metrics=["accuracy"]
)训练结果如下:

训练集的准确度达到了0.23,但是验证集的而准确度只有0.04
acc,val_aac结果绘制如下:
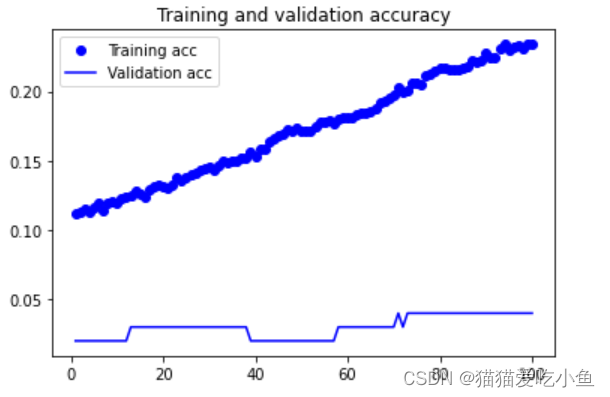
loss,val_loss绘制如下:
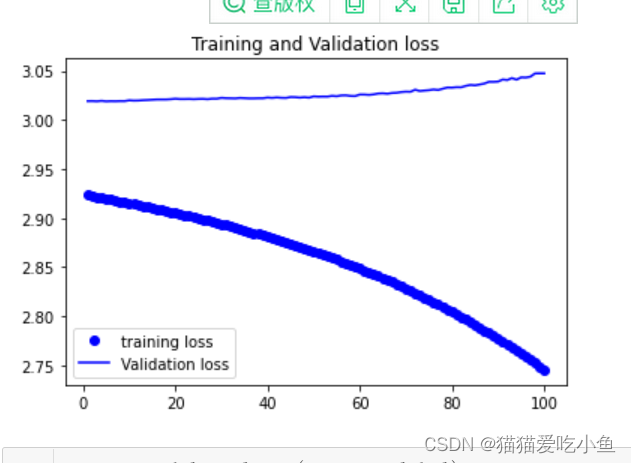
因为训练的样本比较少,但是分的类别有20,维度也比较低,所以本次模型的效果也不好,虽然训练集的准确度一直在提高,但是验证集的准确率没有较大的变化,训练集的损失值也在不断下降,但是验证集的loss值基本没什么变化。
对测试集的效果如下:

准确度比较低,只有0.06
增加训练的epochs为200,降维维度增大到35维,训练集取1000个,测试集取200个,验证集取200个
history=model.fit(XX,train_label,epochs=200,
validation_data=(XX2,val_label))训练后结果如下:

acc,val_acc绘图结果如下:
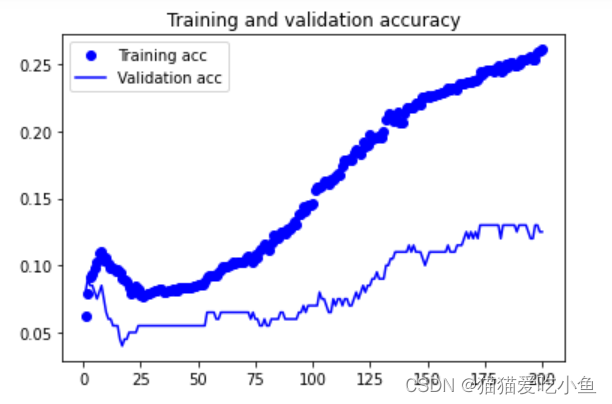
loss,val_loss绘图结果如下:

从实验结果看出虽然训练集的准确度相比较训练100epoch变化不大,但是验证集的准确率提高了很多,提高到了0.12,训练集和测试集的准确率都在提升,loss值也都在下降。
该模型对于测试集的准确率如下:

测试集的准确率达到了0.135,比上一个模型好很多。没有发生欠拟合和过拟合现象。
在此基础上增加中间层网络节点为800个
keras.layers.Dense(800,activation='relu'),结果如下;

训练集的准确率提升了,但是验证集的准确率下降了
对于测试集:

准确度还是0.135没有发生变化,这个模型需要更多的更改。
改变网络模型,增加多层网络结构,增加了两层隐层,节点数和结构如下:
epochs=200
learning_rate=0.001
model=tensorflow.keras.models.Sequential([
keras.layers.Dense(35),
keras.layers.Dense(800,activation='relu'),
keras.layers.Dense(500,activation='relu'),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(20,activation='softmax')
])
sgd = tensorflow.keras.optimizers.SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=sgd,
metrics=["accuracy"]
)
history=model.fit(XX,train_label,epochs=200,
validation_data=(XX2,val_label))训练后结果如下:

acc,val_acc绘图结果如下:
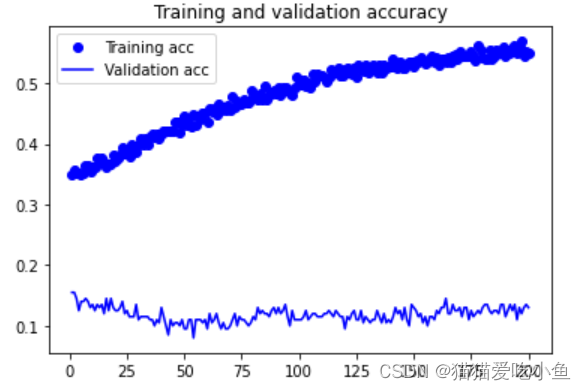
loss,val_loss绘图结果如下:

验证集的loss值在增大,测试集的loss值在减小。
测试集准确度如下:

准确率0.11左右,不是很高。
c.实验3中用朴素贝叶斯分类5个类别的分类效果如下

因为类别只有5类,所以准确度还行,增加到20类后如下;

准确率只有0.38,但是高于网络模型的准确率。
2.基于词嵌入为输入的多层感知机分类
a.得到训练集和测试集中每个词的 100 维词嵌入向量,可以调用gensim 或直接从 http://nlp.stanford.edu/data/glove.6B.zip 下载。
b.基于词向量得到的文档表示(直接对包含的词的向量平均或其他
方法)作为输入,重复上面 1(b-d)的内容,对比后进行讨论。
①词向量模型选用glove-twitter-100
对训练集和测试集的文档都选用平均文档向量
该模型中单词向量维度为100:

训练集的数据量:13197个文本
验证集的数据量:1467个文本
测试集的数据量:3666个文本

经过处理后分词,词性还原处理,去除单词数<=2的新闻文档。
训练集的数据量变为:13179个文本
验证集的数据量变为:1455个文本
测试集的数据量变为:3631个文本
对所有文档取平均向量。
分别为:very_vector,train_vector,test_vector

训练模型参数如下,epochs=100,中间层节点个数为800:
learning_rate=0.001
epochs=100
model=tensorflow.keras.models.Sequential([
tensorflow.keras.layers.Dense(100),
tensorflow.keras.layers.Dense(800,activation='relu'),
tensorflow.keras.layers.Dense(20,activation='softmax')]
)
sgd = tensorflow.keras.optimizers.SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=sgd,
metrics=["accuracy"]
)model.summary()

训练一百次后结果如下:

训练集的准确率为0.1906,验证集的准确率只有0.061
accuracy,val_accuracy绘图结果如下:

loss,val_loss绘图结果如下:

测试集结果如下:

准确率比较低,只有0.0680。
②词向量模型选用glove.6B.100d.txt
glove = open('E:\\glove.6B\\glove.6B.100d.txt','r',encoding='utf-8')先创建分词器,构建单词索引,将字符串转为整数索引组成的列表
sequences = tokenizer.texts_to_sequences(test_data)训练集,验证集,测试集的大小如下:

网络模型如下:
中间节点个数选择400个
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen)) #添加embedding层
model.add(Flatten()) #张量展开
model.add(Dense(400, activation='relu'))
model.add(Dense(20, activation='sigmoid'))
model.layers[0].set_weights([embedding_matrix]) #将预训练的词嵌入加载到embedding层中
model.layers[0].trainable = False
sgd = tensorflow.keras.optimizers.SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=sgd,
metrics=["accuracy"]
)model.summary结果如下所示:

训练40次,效果如下:

训练集的准确度为0.9970,但是验证集的准确率只有0.0985
accuracy,val_accuracy绘图结果如下:

loss,val_loss绘图结果如下:

训练集的准确率趋于1,不在改变,但时验证集的准确率没有什么提升。
验证集的损失值也在提升。
测试集准确率为:

测试集准确率:0.0986,比较低,模型的拟合效果不太好。
四、实验体会:
- 文本的预处理的重要性
由于文本分类处理的是大量非结构化的用自然语言描述的无统一结构的文
本数据,在堆文档进行特征提取前,需要先对这些文本数据进行相应的预处理,
它将直接影响文本分类的效率和准确度以及最终模式的有效性。
- 网络模型训练时间短,但是对于类别多的分类数据,很容易过拟合,训练集的准确度达到了,但是测试集的准确率还是比较低。
- 学习率的作用
一个良好的学习率更新策略,可以抽象为以下两点好处:
1.更快地达到loss的最小值
2.保证收敛的loss值是神经网络的全局最优解
如何选择学习率?
首先设置一个较大的学习率,使网络的损失值快速下降,然后随着迭代次数的增加一点点减少学习率,防止越过全局最优解。
- 激活函数
主要作用:
提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
性质:
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限的时候,模型的训练会更加高效。
五、源代码:
链接:文本分析实验六-多层感知机、gensim、glove源码-Python文档类资源-CSDN下载
《文本分析实验六+要求1(a,b,d).ipynp》
《文本分析实验六+要求1(多层网络)a+b+d.ipynp》
《文本分析实验六+要求1(单层网络)a+b+d.ipynp》
《文本分析实验六+要求1+c(朴素贝叶斯).ipynp》
《文本分析实验六+要求2(Twitter-100).ipynp》
《文本分析实验六+要求2(glove.6b.100d).ipynp》















 2405
2405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









