






hive支持的基本数据类型
| 数据类型 | 长度 | 例子 |
|---|---|---|
| TINYINT | 1byte有符号整数 | 20 |
| SMALLINT | 2byte有符号整数 | 20 |
| INT | 4byte有符号整数 | 20 |
| BIGINT | 8byte有符号整数 | 20 |
| BOOLEAN | 布尔型,true或false | TRUE |
| FLOAT | 单精度(4byte)浮点数 | 3.14159 |
| DOUBLE | 双精度(8byte)浮点数 | 3.14159 |
| STRING | 字符序列,可以指定字符集。可以使用单引号或双引号 | ‘now is the time’,“for all good men” |
| TIEMSTAMP(V0.8.0+) | 整数,浮点数或者字符串 | 1327882394(Unix新纪元秒),1327882394.123456789(Unix新纪元秒并跟随由纳秒数)和’2012-02-03 12:34:56.123456789‘(JDBC所兼容的java.sql.Timestamp时间格式) |
| BINARY(V0.8.0+) | 字节数组 |
hive> use onhive;
FAILED: SemanticException [Error 10072]: Database does not exist: onhive
在hive中使用onhive报错?怎么回事?明明在MySQL中创建了的,还是在好好查下吧
hive> show databases;
OK
database_name
default
果然没有onhive
hive 中的数据库和MySQL的数据库不一样,怎么回事?
在部署hive时,在MySQL中创建了数据库onhive,并在hive中初始化了metastore,现在到MySQL中重新创建onhive数据库来好好查下:
mysql> create database onhive;
Query OK, 1 row affected (0.02 sec)
mysql> use onhive;
Database changed
mysql> select * from DBS;
ERROR 1146 (42S02): Table 'onhive.DBS' doesn't exist
新创建了MySQL数据库,需要重新执行初始化
# schematool -dbType mysql -initSchema
该语句的作用是在mysql的hive数据库下建立一大堆的表格.此时再次查看DBS,已经存在了,但是没有内容
mysql> select * from DBS;
Empty set (0.00 sec)
在hive中执行创建数据库onhive ,然后再次查看DBS,已经有了内容并且是两行
hive> create database onhive;
mysql> select * from DBS;
+-------+-----------------------+---------------------------------------------------+---------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+-----------------------+---------------------------------------------------+---------+------------+------------+
| 1 | Default Hive database | hdfs://bigdata:9000/user/hive/warehouse | default | public | ROLE |
| 2 | NULL | hdfs://bigdata:9000/user/hive/warehouse/onhive.db | onhive | root | USER |
+-------+-----------------------+---------------------------------------------------+---------+------------+------------+
再次在hive中选择onhive,成功
hive> use onhive;
OK
Time taken: 0.16 seconds
2 rows in set (0.00 sec)
Hive 中的三种集合方式Array,Struct,MAP
CREATE TABLE onhive.employees(
name STRING,
sa1ary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' -- 列分隔符
COLLECTION ITEMS TERMINATED BY '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
MAP KEYS TERMINATED BY ':' -- MAP中的key与value的分隔符
LINES TERMINATED BY '\n'; -- 行分隔符
测试数据:
vi test.txt
John Doe,100000.0,Mary Smith_Todd Jones,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,1 Michigan Ave._Chicago_1L_60600
Tom Smith,90000.0,Jan_Hello Ketty,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,Guang dong._China_0.5L_60661
ps:注意,MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
导入数据,local表示本地路径中寻找目标文件,不加local则到HDFS目录寻找
load data local inpath '/opt/module/hive-2.3.6-bin/hive_query/test.txt' into table onhive.employees;
hive> select * from employees;
OK
employees.name employees.sa1ary employees.subordinates employees.deductions employees.address
John Doe 100000.0 ["Mary Smith","Todd Jones"] {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} {"street":"1 Michigan Ave.","city":"Chicago","state":"1L","zip":60600}
Tom Smith 90000.0 ["Jan","Hello Ketty"] {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} {"street":"Guang dong.","city":"China","state":"0.5L","zip":60661}
Time taken: 3.839 seconds, Fetched: 2 row(s)
#Array,Map,Struct的数据取用方式:
hive> select subordinates[0],deductions['Federal Taxes'],address.city from employees;
OK
_c0 _c1 city
Mary Smith 0.2 Chicago
Jan 0.2 China
Time taken: 0.841 seconds, Fetched: 2 row(s)
Hive 中的分隔符
在文本文件中的默认分隔符:
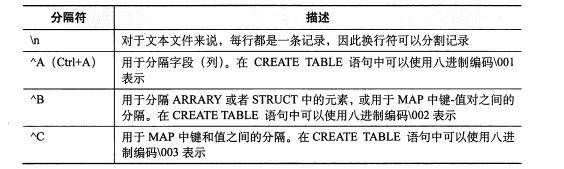
还可以使用其他符号作为分隔符,如:
CREATE TABLE onhive.employees(
name STRING,
sa1ary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' -- 列分隔符
COLLECTION ITEMS TERMINATED BY '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
MAP KEYS TERMINATED BY ':' -- MAP中的key与value的分隔符
LINES TERMINATED BY '\n'; -- 行分隔符
测试数据:
John Doe,100000.0,Mary Smith_Todd Jones,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,1 Michigan Ave._Chicago_1L_60600
Tom Smith,90000.0,Jan_Hello Ketty,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,Guang dong._China_0.5L_60661
ps:注意,MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“_”。
Hive 的读时模式
- 传统的数据库是写时模式,即数据在写入数据库时对模式进行检查,Hive在查询时进行验证,也就是读时模式
- Hive对于错误数据的恢复:行记录中的字段少于表定义的字段,缺失的字段值将返回NULL,如果字段类型不匹配此字段也会返回NULL
Hive中数据库
- Hive中的数据库的概念本质上仅仅是表的一个目录或者命名空间,对于有很多组和用户的大集群来说,这样可以避免表命名冲突,通常会使用数据库来将生成表组织成逻辑组。
- 如果用户没有显示指定数据库,会使用默认的数据库default
#创建数据库
create database financials;
create database if not exists financials;
hive> show databases;
OK
database_name
default
financials
onhive
#模糊查找数据库
hive> show databases like 'f.*';
OK
database_name
financials
#查看数据库的文件目录信息
hive>
> desc database financials;
OK
db_name comment location owner_name owner_type parameters
financials hdfs://bigdata:9000/user/hive/warehouse/financials.db root USER
#默认的文件目录位置:/user/hive/warehouse/financials.db,改变位置可以使用LOCATION命令
hive> create database financials02 location '/my/preferred/directory';
hive> desc database financials02;
OK
db_name comment location owner_name owner_type parameters
financials02 hdfs://bigdata:9000/my/preferred/directory root USER
#为database添加comment
hive> create database financials03 comment 'Holds all financials tables';
hive> desc database financials03;
OK
db_name comment location owner_name owner_type parameters
financials03 Holds all financials tables hdfs://bigdata:9000/user/hive/warehouse/financials03.db root USER
#设置当前数据库到提示符中,可将此配置配置到$HOME/.hiverc中
hive> set hive.cli.print.current.db=true;
#删除数据库
drop database financials;
drop database if exists financials;
drop database if exists financials cascade;
创建表
create table if not exists onhive.employees04(name string comment 'Employee name')
comment 'Description of the table'
location '/user/hive/warehouse/onhive.db/employees04'
tblproperties ('creator'='me', 'create_at'='2012-01-02 10:00:00');
#通过其他表创建表的结构,无需数据
类似Oracle中的create table x as select * from y where 1=2
hive (onhive)> create table if not exists onhive.employees02 like onhive.employees;
#查看表结构
hive (onhive)> desc employees02;
OK
col_name data_type comment
name string
sa1ary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
#使用extended关键字查看表结构
hive (onhive)> desc extended employees02;
OK
col_name data_type comment
name string
sa1ary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
Detailed Table Information Table(tableName:employees02, dbName:onhive, owner:root, createTime:1568657061, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:name, type:string, comment:null), FieldSchema(name:sa1ary, type:float, comment:null), FieldSchema(name:subordinates, type:array<string>, comment:null), FieldSchema(name:deductions, type:map<string,float>, comment:null), FieldSchema(name:address, type:struct<street:string,city:string,state:string,zip:int>, comment:null)], location:hdfs://bigdata:9000/user/hive/warehouse/onhive.db/employees02, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{colelction.delim=_, mapkey.delim=:, serialization.format=,, line.delim=
, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{totalSize=0, numRows=0, rawDataSize=0, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true"}, numFiles=0, transient_lastDdlTime=1568657061}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, rewriteEnabled:false)
Time taken: 0.08 seconds, Fetched: 8 row(s)
#使用formatted关键字查看表结构
hive (onhive)> desc formatted employees02;
OK
col_name data_type comment
# col_name data_type comment
name string
sa1ary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
# Detailed Table Information
Database: onhive
Owner: root
CreateTime: Mon Sep 16 14:04:21 EDT 2019
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://bigdata:9000/user/hive/warehouse/onhive.db/employees02
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1568657061
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim _
field.delim ,
line.delim \n
mapkey.delim :
serialization.format ,
Time taken: 0.09 seconds, Fetched: 38 row(s)
#查看所有表
hive (onhive)> show tables;
OK
tab_name
employees
employees02
employees04
#模糊查找表名
hive (onhive)> show tables 'emp.*';
OK
tab_name
employees
employees02
employees04
外部表
- 通常创建的表被称为管理表,也叫内部表
- 外部表,用关键字EXTENAL定义表性质,LOCATION定义外部数据路径 删除外部表,只会删除表的元数据信息,而不会删掉外部实际的数据
- 区分内部表和外部表:desc extended table_name
- 内部表:tableType:MANAGED_TABLE
- 外部表:tableType:EXTERNAL_TABLE
创建外部表
- #使用已存在表表结构创建外部表,且数据位于 ‘/path/to/data’:
create external table if not exists onhive.employees03
like onhive.employees
location '/path/to/data';
- 单独创建外部表,用以读取/data/stocks目录下以逗号为分隔符的文件
create external table if not exists stocks1(
exchange1 STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_hight FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
row format delimited fields terminated by ','
location '/data/stocks';
分区表、管理表
- 分区表:通常使用分区水平分散压力,将数据从物理上转移到和用户使用最频繁的用户更近的地方。
- Hive分区:一个分区实际上就是表下的一个目录,一个表可以在多个维度上进行分区,分区之间的关系就是目录树的关系(可以进入HWI查看)
- 分区表在创建时,通过PARTITION BY 子句指定分区的顺序,决定了父目录和子目录
创建分区表
外部分区表需添加external关键字
CREATE TABLE onhive.employees03(
name STRING,
sa1ary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
PARTITIONED BY (country STRING,state STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' -- 列分隔符
COLLECTION ITEMS TERMINATED BY '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号)
MAP KEYS TERMINATED BY ':' -- MAP中的key与value的分隔符
LINES TERMINATED BY '\n';
测试数据:
John Doe,100000.0,Mary Smith_Todd Jones,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,1 Michigan Ave._Chicago_1L_60600
Tom Smith,90000.0,Jan_Hello Ketty,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,Guang dong._China_0.5L_60661
分区表装载数据
load data local inpath '/opt/module/hive-2.3.6-bin/hive_query/test.txt' into table employees03 partition(country='US',state='AK');
strict和nostrict模式查询下查询分区表
在strict模式下,对分区表查询必须在WHERE子句中对分区进行过滤,否则禁止提交这个任务
hive (onhive)> set hive.mapred.mode=strict;
hive (onhive)> select e.name,e.salary from employees03 e limit 100;
FAILED: SemanticException Queries against partitioned tables without a partition filter are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.large.query to false and that hive.mapred.mode is not set to 'strict' to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features. No partition predicate for Alias "e" Table "employees03"
hive (onhive)> set hive.mapred.mode=nostrict;
hive (onhive)> select e.name,e.salary from employees03 e limit 100;
OK
e.name e.salary
Time taken: 0.359 seconds
查看表中存在的所有分区
hive (onhive)> show PARTITIONS employees03;
OK
partition
country=US/state=AK
外部分区表
create external table if not exists log_messages(
hms int,
serverity string,
server string,
process_id int,
message string)
partitioned by (year int,month int,day int)
row format delimited fields terminated by '\t';
为外部分区表添加分区
alter table log_messages add if not exists
partition(year=2012,month=1,day=2)
location '/data/log_messages/2012/01/02';
将分区下的数据拷贝到其他目录中
hadoop distcp /xx/xxx xx:/xx/xx
将分区路径指向其他目录,此目录不会将数据从旧的路径下转移走,也不会删除旧的数据。
alter table log_messages partition(year=2011,month=12,day=2)
set location 'xx://xx/2011/01/02';
删除分区数据
hadoop fs -rmr /data/log_messages/2012/01/02
查看外部表分区信息
show partitions log_messages;
desc formatted log_messages;
desc log_messages
#可以查看分区数据存放位置
desc formatted log_messages partition(year=2012,month=1,day=2);
hive (onhive)> desc formatted log_messages partition(year=2012,month=1,day=2);
OK
col_name data_type comment
# col_name data_type comment
hms int
serverity string
server string
process_id int
message string
# Partition Information
# col_name data_type comment
year int
month int
day int
# Detailed Partition Information
Partition Value: [2012, 1, 2]
Database: onhive
Table: log_messages
CreateTime: Tue Sep 17 04:39:43 EDT 2019
LastAccessTime: UNKNOWN
Location: hdfs://bigdata:9000/data/log_messages/2012/01/02
Partition Parameters:
transient_lastDdlTime 1568709583
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
修改列的信息
重命名列,修改位置,类型或注释
alter table log_messages change
--这行是必须的,如果不修改列名则前后的列名相同
column hms hour_minutes_seconds int
comment 'The hours,minutes,and senconds part of the thimestamp';
更改字段位置
alter table log_messages change
column hour_minutes_seconds hour_minutes_seconds int
AFTER serverity;
添加列
alter table log_messages
add columns(
app_name string comment 'Application name'
session_id float comment 'The current session id');
删除或替换列(相当于覆盖性定义表)
alter table log_messages replace columns(
hours_mins_secs int comment 'hour,minute,seconds from timestamp',
severity string comment 'The message of severity',
message string comment 'The message of message');
修改表的属性
alter table log_messages set tblproperties(
'notes'='The process id is no longer captured;this column is always NULL');
表重命名
ALTER TABLE log_messages RENAME TO log_messages_bak














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









