








在阅读PDF时,尤其是年代久远的PDF,容易出现类似如下情况,数字和英文成了全角字符,莫名空格和换行,非常抓狂。
2001年9月17日,世 贸 组 织 中 国 工 作 组 第18次 会 议 通 过 了 中 国 入 世 议
定 书 及 附 件 和 中 国 工 作 组 报 告 书,标 志 着 我 国 加 入 世 贸 组 织 的 谈 判 全 部 结 束;
2001年11月10日,在 卡 塔 尔 首 都 多 哈 举 行 的 世 界 贸 易 组 织(WTO)第 四 届
部 长 级 会 议 审 议 并 通 过 了 中 国 加 入 世 界 贸 易 组 织 的 决 定。同 年12月11日,中 国
正 式 加 入 WTO, 成 为其第143个成员.
尝试使用一个 python 脚本+ mac 的自动操作,实现使用一个快捷键把上面的文本处理成正常形式。
只是实现了一个最简单,最根本的需求,主要目的是使用 automator 实现自动化,以后慢慢改。
代码仓库:ChengziCao/TextCleaner (github.com)
import jieba
import pyperclip
class TextCleaner:
def __init__(self, str):
self.text = str
def text_strip(self):
"""
移除异常空格、换行
"""
if TextCleaner.is_contain_chinese(text):
# 如果是中文,则去除行内空格、行尾换行
self.text = self.text.replace(' ', '').replace('\n', '')
else:
# 如果是英文,则只去除行尾换行。
self.text = self.text.replace('\n', '')
return self
def punctuation_convert(self):
"""
将英文标点符号替换成中文标点
"""
e_pun = u',.!?()<>"\':;'
c_pun = u',。!?()《》“‘:;'
table = {ord(f): ord(t) for f, t in zip(e_pun, c_pun)}
self.text = self.text.translate(table)
return self
def remove_chaos(self):
"""
去除乱码
"""
gbk_text_list = []
for c in self.text:
if not TextCleaner.if_contain_chaos(c):
gbk_text_list.append(c)
self.text = "".join(gbk_text_list)
return self
def full_to_half(self):
"""
全角转半角
"""
fullString = str(self.text)
halfString = ""
for schar in fullString:
char_code = ord(schar)
if char_code == 12288:
char_code = 32
elif (char_code >= 65281 and char_code <= 65374):
char_code -= 65248
halfString += chr(char_code)
self.text = halfString
return self
def add_en_cn_space(self):
"""
对英文单词、数字添加空格
"""
list1 = list(map(lambda n: ' ' + n + ' ' if (n.encode().isalnum()) else n, jieba.cut(self.text)))
self.text = "".join(list1).strip()
return self
@staticmethod
def if_contain_chaos(text_):
"""
判断字符是否为GBK字符,如果不是则认为是乱码。因为人眼能识别的乱码在计算机看来并没有想象中那么简单,
“涓囧厓锛屾厛锽勬崘鐚”本身也是正常的字符,故将生僻字认为是乱码,这是一个折中的办法。
"""
try:
text_.encode("gb2312")
except UnicodeEncodeError:
return True
return False
@staticmethod
def is_contain_chinese(check_str):
"""
判断字符串中是否包含中文
"""
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
if __name__ == '__main__':
# text: str = """2001年9月17日,世 贸 组 织 中 国 工 作 组 第18次 会 议 通 过 了 中 国 入 世 议
# 定 书 及 附 件 和 中 国 工 作 组 报 告 书,标 志 着 我 国 加 入 世 贸 组 织 的 谈 判 全 部 结 束;
# 2001年11月10日,在 卡 塔 尔 首 都 多 哈 举 行 的 世 界 贸 易 组 织(WTO)第 四 届
# 部 长 级 会 议 审 议 并 通 过 了 中 国 加 入 世 界 贸 易 组 织 的 决 定。同 年12月11日,中 国
# 正 式 加 入 WTO, 成 为其第143个成员."""
text: str = pyperclip.paste()
cleaner = TextCleaner(text)
cleaner.remove_chaos().text_strip().full_to_half().punctuation_convert().add_en_cn_space()
pyperclip.copy(cleaner.text)
# print(cleaner.text)
然后打开 mac 的 automator 应用,打开之后选择“新建文稿”,起个名字(不要乱起,后面还会用到),然后选“快速操作”
然后找到“运行shell脚本”双击,工作流程选择“没有输入”,之后就可以像在终端里一样执行python脚本了。
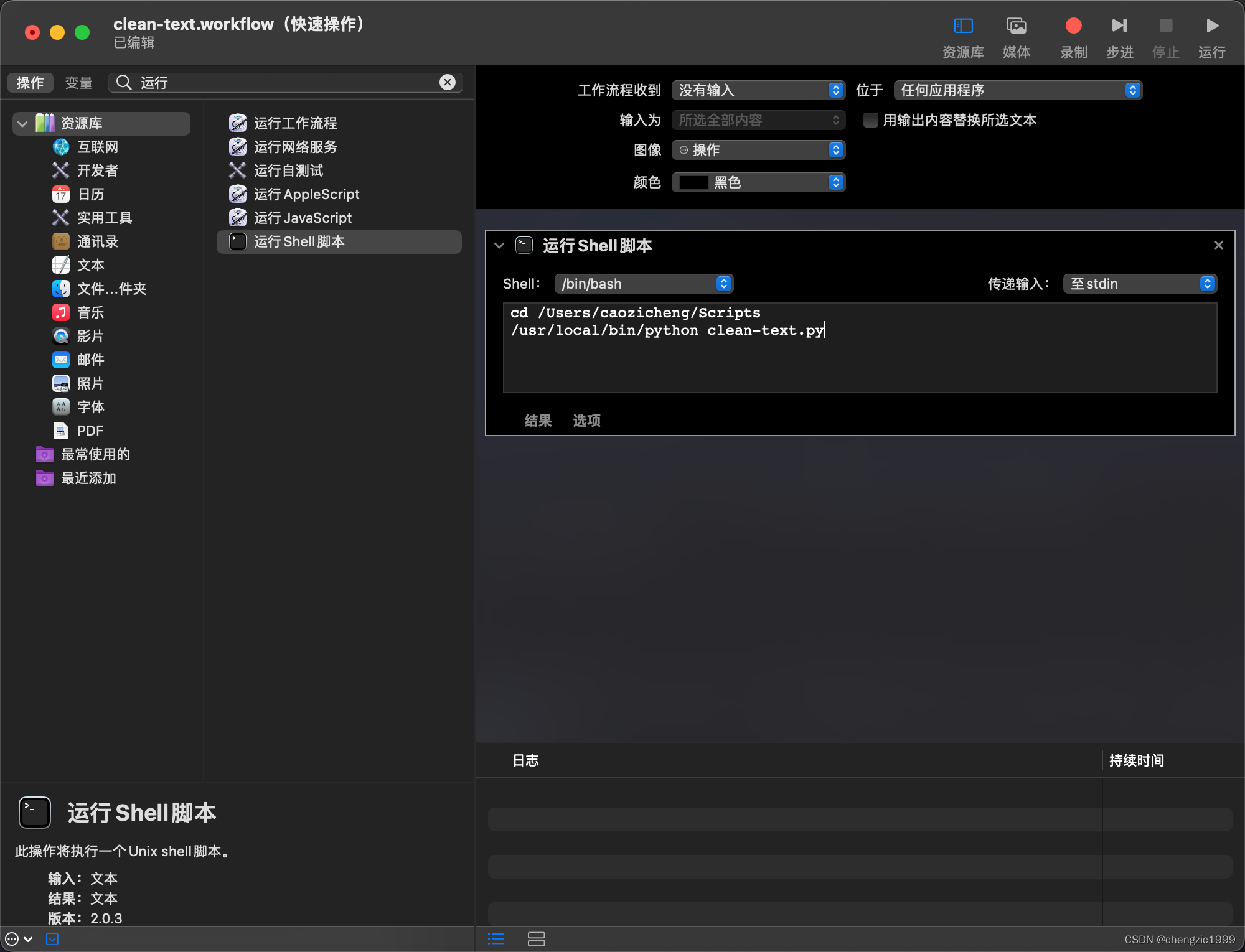
因为我把环境变量写到 ~/.zshrc 里了,只有启动终端时才会加载,所以我写的是python的全路径,正常应该不需要写完整路径。
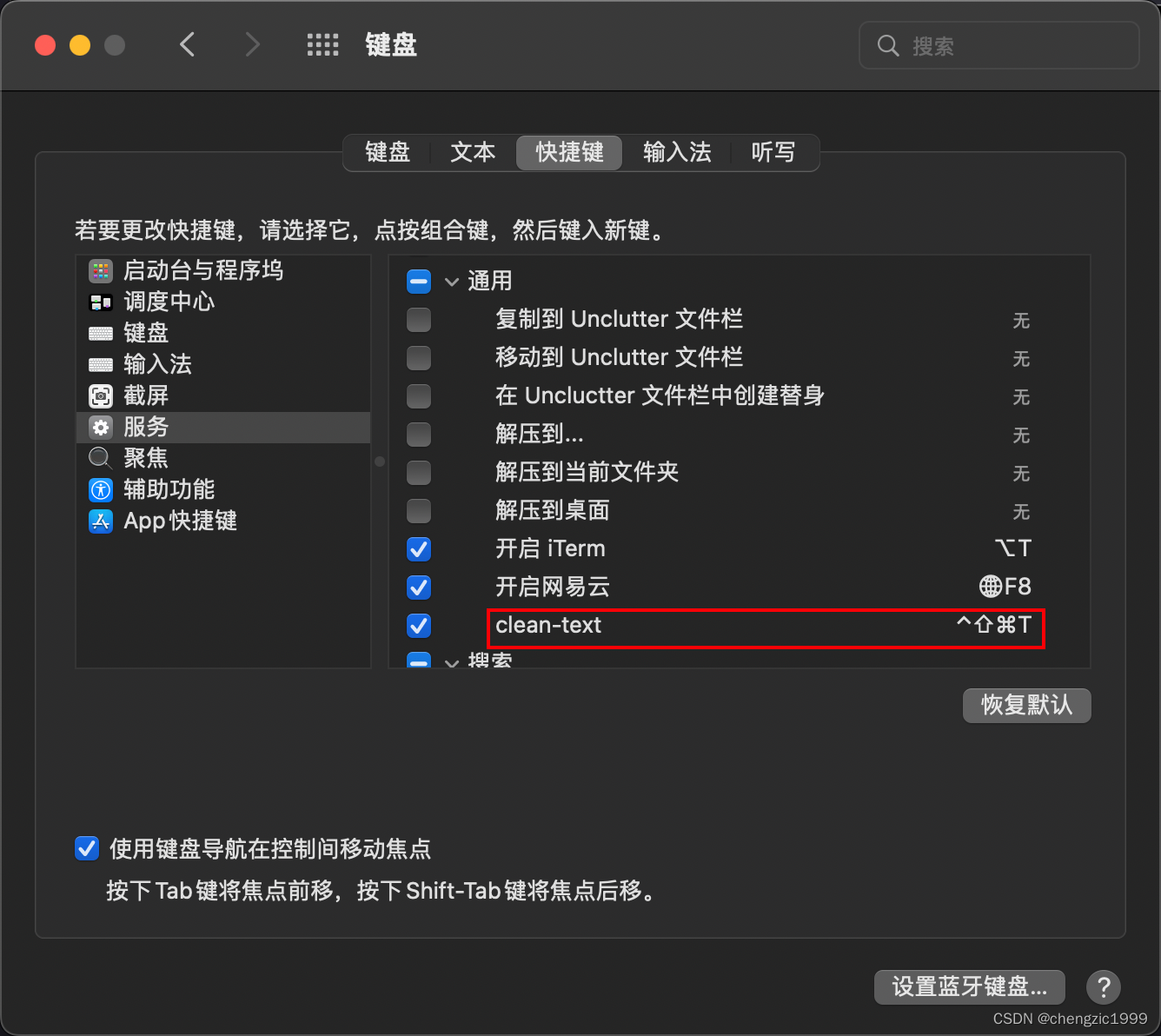
之后打开系统偏好设置–>键盘–>快捷键,在服务一项中找到通用,刚才新建的快速操作就在这一栏里,指定上自己希望的快捷键。
然后,只需要复制文本,按下快捷键,文本就被处理完成,大功告成啦!















 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









