







前一章用SQL表达式(SQL Express)语法操作数据库时,仍然侧重于从Core API的角度来看 SQL表达式语言,主要目的是通过封装的SQL表达式来实现跨不同数据库目的。
本章主要介绍ORM API 基础知识、实现ORM CRUD 基础操作。我尽可能使用简洁的语言,配合实例代码,帮助你尽快上手。下一章将深入学习ORM API的主要方法、使用方式,以及较复杂需求的编程实现。
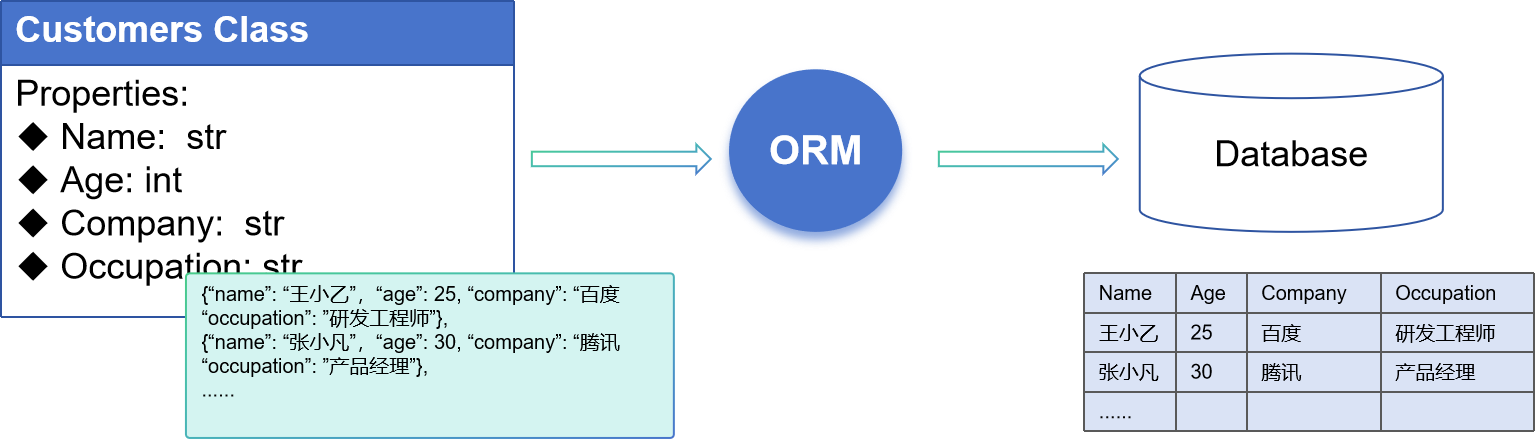
1、ORM 原理
在第1章介绍过ORM原理时。 Python类对象通过ORM与数据库Table进行映射,通过Python类对象的方式来操作数据库。开发人员无须再使用各类数据库的接口API,以及SQL语法。
注: ORM的理想很丰满,现实却是这样的:用好ORM还是需要扎实的SQL基础才能用好。
ORM如何实现从Python对象到数据库的映射呢?
- 这种映射结构可分为如下几层
- Python Table类: 将 Database 的表结构 => 表示为 Python Metadata, 数据库字段 => 表示为Python Table类的属性(Column对象)
- Python Table类的1个实例对象(object),相当于数据库的1行记录,对象列表表示多行记录。
- 数据库操作的ORM实现
- 插入1行数据,就相当于: 新建1个Python类实例对象,通过ORM插入数据库
- 通过ORM查询数据库,返回值为Python对象列表
2、ORM基础编程步骤
2.1 ORM API的使用步骤:
预备知识:
metadata:
上一章已详细介绍过,用于保存表结构, 通常1个应用定义1个全局metadata对象, 集中保存表结构。
declarative Table 声明式Table类
将数据库的表、字段,定义成Python类与属性的结构,这种结构称为声明式映射(Declarative Mapping)。Sqlalchemy2以后。table 类必须继承自 DeclarativeBase。
ORM API的使用流程:
(1)定义1个DeclarativeBase子类,做为Python table类的父类
(2)定义映射table类,映射到1个数据库表
(3)通过engine在数据库中实际创建表。 由Base.metadata向engine 发关create table DDL的事件.
(4) 创建Session对象,连接到engine,用于管理后续数据库操作。
(5) ORM对数据的增删改查操作,与Core API 有明显不同。 ORM的添加、修改、删除操作是通过Session来操作映射Table类的对象来完成。ORM查询使用的 select()方法也对 SQL表达式做了进一步封装,输入是以映射Table对象,而非metadata 的table类。
说明:此处提到的 table 类,是为了描述方便,此类用于映射数据库表,不是上一节提到的sqlalchemy.Table 内置类。
2.2 声明式映射语法定义Table类与Column类
SqlAlchemy 提供了两种ORM映射方式定义映射类: 经典式Imperative Mapping, 声明式Declarative Mapping。尔后第3节会详细介绍。
1) 申明式定义table 类
继承自DeclarativeBase, column 字段定义遵照mapping 语法
定义1个Base做为Table类的基类
from sqlalchemy.orm import DeclarativeBase
class Base(DeclarativeBase):
pass
注:Base对象包含metadfata. registry 属性
Base.metadata
Base.registry
设置数据库表名
__tablename__ = "user_account" , 设置为db table 名
定义column属性,
name: Mapped[str] = mapped_column(String(30))
等号左边使用type notation注明Python类型,右边用mapped_column()给出最匹配的Database字段类型
这是SqlAlchemy2.0推荐的方式,别嫌麻烦,这样做可以大大减少数据库迁移时出错的概率,
下面是1个用声明式映射方式定义的Person 类。
from sqlalchemy.orm import DeclarativeBase, Session
from sqlalchemy.orm import Mapped, mapped_column
from sqlalchemy import String, Integer
class Base(DeclarativeBase):
pass
class Person(Base):
__tablename__ = 'person'
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
age: Mapped[int] = mapped_column(Integer)
def __init__(self, name: str, age: int):
self.name = name
self.age = age
def __repr__(self):
return f"Person({self.name}, {self.age})"
说明:
上述模型类,除将用属性映射到数据库字段外,与普通类定义一样,也提供了对象初始化方法__init__(),以及__repr__()魔法方法。 还可以添加其它的方法,如属性的校验方法等。
2)通过engine对象在数据库中创建表
创建数据库连接引擎对象
engine = create_engine(
"mysql+mysqlconnector://root:12345678@localhost:3306/testdb")
# 请用你的mysql用户名及密码替换root:12345678
将DDL语句映射到数据库表,如果数据库表不存在,则创建该表
Base.metadata.create_all(engine)
2.3 向数据库插入数据
我们现在可以在数据库中插入数据了。通过创建类的实例来实现这一点. 还要使用一个名为Session的对象将它们传递到数据库,该对象利用Engine与数据库进行交互。使用Se木本油料Session.add(obj)添加1个对象(数据记录行),或使用Session.add_all()方法一次添加多个对象,而Session.commit()方法将用于保存对数据库的变更。
session = Session(engine)
# 创建Person实例对象
p1 = Person("刘备", 40)
p2 = Person("关羽", 38)
p3 = Person("张飞", 35)
# 将Person实例对象添加到session
session.add(p1)
session.add(p2)
session.add(p3)
session.commit() # 提交事务到数据库
建议通过上下文管理器使用Session,即使用Python with语句。
2.4简单SELECT查询
对于数据库中的某些行,以下是发出SELECT语句以加载某些对象的最简单形式。要创建SELECT语句,
1)使用SELECT() 函数创建一个新的SELECT对象.
2) 使用Session调用该对象。执行ORM查询时,最常用方法是Session.scalars()方法,它将返回一个ScalarResult对象,该对象将遍历我们选择的ORM对象. (另1个执行方法 Session.execute() 在后面章节也会介绍)
stmt = select(Person).where(Person.name == "刘备")
results = session.scalars(stmt)
print(results.all())
Output:
[Person(刘备, 40)]
返回值 results对象为ScalarResult类实例, all()以对象列表方式返回查询结果, 每个元素是1个映射table类对象 ,每个对象的各个属性,相对应于数据库表的字段值。
ScalarResult对象还提供了first(), fetchone(), fetchmany(), fetchall()等方法,习惯于DBAPI编程的同样都很熟悉。
ScalarResult对象也是可迭代的,用for 循环遍历读取结果
stmt = select(Person).where(Person.name.in_(["刘备", "关羽"]))
results = session.scalars(stmt)
for p in results:
print(p)
Output:
Person(刘备, 40)
Person(关羽, 38)
查询全部数据
results = session.scalars(select(Person).order_by(Person.age))
多条件查询
Where()方法不支持 and, or逻辑运算符,但支持where()方法的链式调用来实现多条件查询。
stmt = select(Person).where(Person.age > 35).where(Person.age < 50)
results = session.scalars(stmt)
print(results.all())
2.4 更新数据
更新数据时,先以对象的方式读取到1条数据后,更新该对象的属性,然后通过session提交事件,即自动将更新数据库相应记录。
例如。我们先在Person表中插入1条name=”张辽”的数据
p4 = Person("张辽", 36)
session.add(p4)
session.commit() # 提交事务到数据库
然后获取该记录对象,将name属性改为”赵云”,提交更新。
stmt = select(Person).where(Person.name == "张辽")
person = session.scalars(stmt).first()
person.name = "赵云"
person.age = 32
session.commit()
results = session.scalars(select(Person).order_by(Person.age))
print(results.all())
Output
[Person(赵云, 32), Person(张飞, 35), Person(关羽, 38), Person(刘备, 40)]
2.5 删除数据
删除数据,也就是用session.delete()方法向engine传递1个对象。如果该对象不存在,则会抛出异常,如果该对象存在,则删除。
p5 = Person("曹操", 50)
try:
session.delete(p5)
except Exception as e:
print("数据库中不存在该记录")
p6 = session.scalars(select(Person).where(Person.name == "赵云")).first()
session.delete(p6)
session.commit()
results = session.scalars(select(Person).order_by(Person.age))
print(results.all())
Output:
数据库中不存在该记录
[Person(张飞, 35), Person(关羽, 38), Person(刘备, 40)]
3、字段映射的实现原理
由于SqlAlchemy ORM API 需要支持各种数据库,但不同数据库支持的数据类型存在差异,定义Table类的关键一点是,如何将column属性的python类型映射到数据库字段数据类型,SqlAlchemy提供了两种不同的Mapping风格:
- imperative mapping, 这是老版本采用的映射方式,称classical mapping, 经典式映射方式。网上大部分关于SqlAlchemy ORM示例使用此种风格。
- declarative mapping,声明式映射,官网建议Declarative mapping 方式。
3.1 Imperative Mapping 映射方式
Imperative Mapping 映射必须显式地调用 registry.map_imperatively() 来完成类属性与数据库字段的映射。
from sqlalchemy import Table, Column, Integer, String, ForeignKey
from sqlalchemy.orm import registry
mapper_registry = registry()
user_table = Table(
"user",
mapper_registry.metadata,
Column("id", Integer, primary_key=True),
Column("name", String(50)),
Column("fullname", String(50)),
Column("nickname", String(12)),
)
class User:
pass
mapper_registry.map_imperatively(User, user_table)
定义表间关系时,需要要设置properties 参数。
mapper_registry.map_imperatively(
User,
user,
properties={
"addresses": relationship(Address, backref="user", order_by=address.c.id)
},
)
3.2 Declarative 申明式映射方式
此方式必须以 DeclarativeBase为基类。 如果有同1数据库有多个表,这些映射类必须使用同1个基类。
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "user"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(50))
fullname: Mapped[Optional[str]]
nickname: Mapped[Optional[str]] = mapped_column(String(30))
3.3 字段映射语句定义详解
字段映射语句,左侧为python类型注解,所用的Mapped()方法是基于Python标准库typing的扩展; 右侧的mapped_column()方用于定义数据库字段属性,这个方法从左侧的Mapped类型注解中获取数据类型、以及是否允许为空(nullability)
如:
data: Mapped[str] = mapped_column() # 右侧mapped_column()如无参数,可省略
表示 data为str类型,不能为null.
from typing import Optional
additional_info: Mapped[Optional[str]]
允许为空,要用Optional()方法来注解
尽量两则的null设置保持一致,但sqlalchemy 接受两侧不一致,如
# will be String() NOT NULL, but can be None in Python
data: Mapped[Optional[str]] = mapped_column(nullable=False)
3.4 自定义字段映射关系
mapped_column() 方法,默认使用内置的字段映射关系。也可以自定义映射关系,会自动保存至Base类的registry属性,
如下例, 定义了将int 映射为database的 BIGINT类型,str映射为database的可变长文本类型。
import datetime
from sqlalchemy import BIGINT, Integer, NVARCHAR, String, TIMESTAMP
from sqlalchemy.orm import DeclarativeBase
from sqlalchemy.orm import Mapped, mapped_column, registry
class Base(DeclarativeBase):
type_annotation_map = {
int: BIGINT, # 将python int类型映射至数据库 BIGINT
datetime.datetime: TIMESTAMP(timezone=True),
str: String().with_variant(NVARCHAR, "mssql"), # str ->mysql的可变字符串
}
class SomeClass(Base):
__tablename__ = "some_table"
id: Mapped[int] = mapped_column(primary_key=True)
date: Mapped[datetime.datetime]
status: Mapped[str]
相当于
CREATE TABLE some_table (
id BIGINT NOT NULL IDENTITY,
date TIMESTAMP NOT NULL,
status NVARCHAR(max) NOT NULL,
PRIMARY KEY (id)
)
使用类型别名来映射
from typing_extensions import Annotated
str_30 = Annotated[str, 30]
num_12_4 = Annotated[float, 12]
class Base(DeclarativeBase):
registry = registry(
type_annotation_map={
str_30: String(30),
num_12_4: Numeric(12, 4),
}
)
甚至可以将 mapped_column()做为参数传入Annotated()方法中。
timestamp = Annotated[
datetime.datetime,
mapped_column(nullable=False),
]
# 使用
class SomeClass(Base):
# ...
created_at: Mapped[Optional[timestamp]]
3.5 使用Enum 类型映射至数据库可选项字段
如下例 ,定义1个status 类, 用于映射至status字段
class Status(enum.Enum):
PENDING = "pending"
RECEIVED = "received"
COMPLETED = "completed"
class SomeClass(Base):
__tablename__ = "some_table"
id: Mapped[int] = mapped_column(primary_key=True)
status: Mapped[Status]
如果可选项是文本,也可以使用typing.literal类
from typing import Literal
Status = Literal["pending", "received", "completed"]
class SomeClass(Base):
__tablename__ = "some_table"
id: Mapped[int] = mapped_column(primary_key=True)
status: Mapped[Status]
4. 本章小结
ORM API编程的基本流程为:
1)用声明式映射方式,定义Python Table类,其父类必须是DeclarativeBase
2)Table类的属性映射到数据库字段,左边用 maped()注明Python类型,右边用mapped_column()申明对应的数据库字段类型。
3)用Base.metadata.emit()方法将DDL语句发送到数据库创建表。
4)创建Session对象,做为ORM 至 Database的管理器。
5)通过实例对象完成数据库的添加、修改、删除操作
6)通过select()查询数据, 并且提供了where(), order_by()等支持条件查询,排序等。
7) ORM 声明式定义 Model的关键是熟悉字段映射语句。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









