







在学习java标准输出的时候,观察到System.err和System.out的功能非常相似。
先去查找了一下java API,文档中给出的解释如下:
out:
“标准”输出流。此流已打开并准备接受输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。对于简单独立的 Java 应用程序,编写一行输出数据的典型方式是:System.out.println(data);
err:
“标准”错误输出流。此流已打开并准备接受输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。按照惯例,此输出流用于显示错误消息,或者显示那些即使用户输出流(变量 out 的值)已经重定向到通常不被连续监视的某一文件或其他目标,也应该立刻引起用户注意的其他信息。
字面上理解二者的区别即是out用于正常的用户指定的输出,而err专门用于显示错误消失;
用以下简单代码测试二者的区别:
public class PrintErrorAndDebug {
public static void main(String args[]) {
System.out.println("main*()方法开始运行了");
System.err.println("测试有什么区别");
System.out.println("第一条");
System.err.println("测试顺序使用");
System.out.println("第二条");
System.out.println("第三条");
System.out.println("第四条");
System.out.println("第五条");
}
}
结果一:

结果二:

可以看到,有out.println输出的字符串相对顺序没有改变(黑色字体显示),但是err.println输出的字符串位置随机出现。同时注意到,err.println输出的字符串之间的相对位置也没有改变,例如代码改为如下:
public class PrintErrorAndDebug {
public static void main(String args[]) {
System.err.println("main*()方法开始运行了");
System.err.println("测试有什么区别");
System.out.println("第一条");
System.err.println("测试顺序使用");
System.err.println("第二条");
System.err.println("第三条");
System.err.println("第四条");
System.err.println("第五条");
}
}
两次运行结果如下:
结果一:
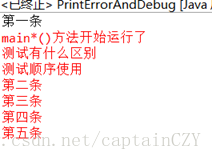
结果二:

小结:System.err和System.out的区别
区别1:API解释的二者用途不同,out为标准输出,err为标准错误输出;
区别2:在eclipse里运行,只管差别就是二者显示的颜色有所区别;
区别3:查阅相关资料,System.out.println可能会被缓冲,而System.err.println不会,由于err不需要缓冲即可输出,直接造成了我们视觉上看到的其位置的不确定性;
对这一块理解还是不太深入,如果有新的发现会继续补充。















 3561
3561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









