






目录
一、学习视频b站
【2022年唐宇迪新全【OpenCV入门到实战】课程分享!原来学习OpenCV可以这么简单,超级通俗易懂!(附配套学习资料)-人工智能\图像处理\计算机视觉】 https://www.bilibili.com/video/BV1CZ4y1f7a2/?p=63&share_source=copy_web&vd_source=670a778bb5c4b23b3c6468afac06c621
二、项目介绍
该项目利用opencv图像处理和keras神经网络实现一段停车场视频的车位识别,训练完后可以识别每个车位是否为空车位以及车位数量。
三、代码按程序步骤学习
1.主程序
if __name__ == '__main__':
#使用列表推导式来读取指定目录下的所有.jpg格式的图片文件,对两张图片分别进行变换
test_images = [plt.imread(path) for path in glob.glob('test_images/*.jpg')]
#car1是训练完网络模型得到的模型结果,第二阶段判断车位是否被占
weights_path = 'car1.h5'
video_name = 'parking_video.mp4'
class_dictionary = {}
#模型预测返回结果,空车位/被占据车位
class_dictionary[0] = 'empty'
class_dictionary[1] = 'occupied'
#所用用到函数封装到parking的类当中
park = Parking()
park.show_images(test_images)
#处理图像,返回处理结果的字典
final_spot_dict = img_process(test_images, park)
model = keras_model(weights_path)
img_test(test_images, final_spot_dict, model, class_dictionary)
video_test(video_name, final_spot_dict, model, class_dictionary)前几行是一些要用到的数据以及定义,test_images放了两张视频的截图用于训练。
接下来按代码顺序分析。
parking是在另一个py文件封装好的类,后面在用到该类的函数时,逐段分析学习。
2.show_images函数
def show_images(self, images, cmap=None):
cols = 2#每行展示两个图像
rows = (len(images) + 1) // cols#计算需要多少行展示图像,//是整除法确保结果整数
plt.figure(figsize=(15, 12))#创建新图形对象,宽15高12
for i, image in enumerate(images):
# 为每个图像创建子图,1行两列,i+1是当前图像子图编号
plt.subplot(rows, cols, i + 1)
# 如果是灰度图就将camp映射为gray,否则使用调用时提供的camp
cmap = 'gray' if len(image.shape) == 2 else cmap
plt.imshow(image, cmap=cmap)
plt.xticks([])#隐藏x轴y轴刻度
plt.yticks([])
# 自动调整子图参数,使之填充整个图像区域
plt.tight_layout(pad=0, h_pad=0, w_pad=0)#自动调整子图参数,使之填充整个图像区域
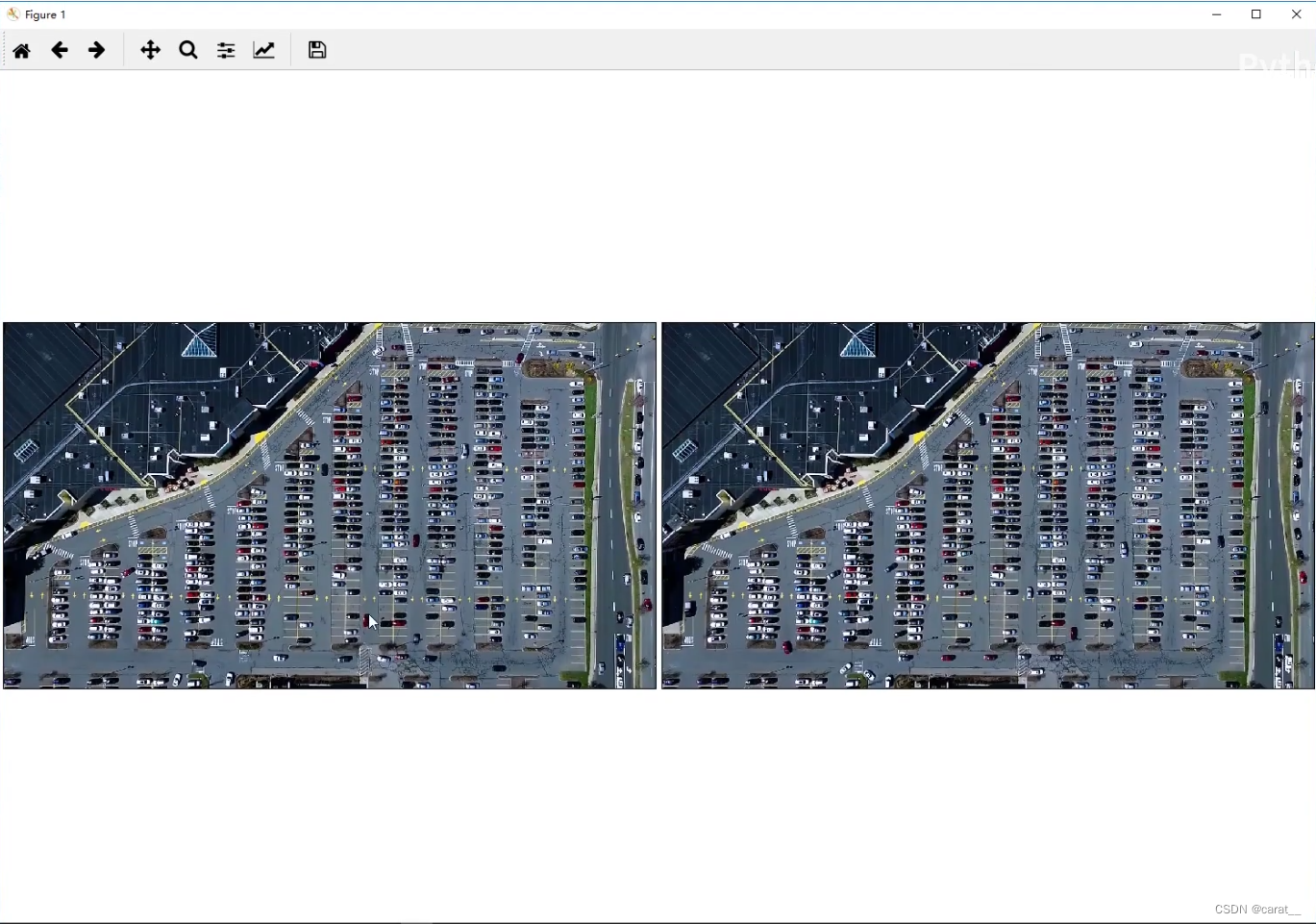
plt.show()这个函数是用来在一个图形窗口中以网格形式展示多个图像的,可以处理彩色图像和灰度图像,并允许用户自定义颜色映射。如果图像是灰度的,它会自动应用灰度颜色映射。
执行后效果:
3.img_process函数
def img_process(test_images, park):
#使用 map 函数和 park 对象的 select_rgb_white_yellow 方法来选择图像中的白色和黄色部分,并将结果转换为列表
white_yellow_images = list(map(park.select_rgb_white_yellow, test_images))
park.show_images(white_yellow_images)
gray_images = list(map(park.convert_gray_scale, white_yellow_images))
park.show_images(gray_images)
edge_images = list(map(lambda image: park.detect_edges(image), gray_images))
park.show_images(edge_images)
roi_images = list(map(park.select_region, edge_images))
park.show_images(roi_images)
list_of_lines = list(map(park.hough_lines, roi_images))
line_images = []
for image, lines in zip(test_images, list_of_lines):
line_images.append(park.draw_lines(image, lines))
park.show_images(line_images)
rect_images = []
rect_coords = []
for image, lines in zip(test_images, list_of_lines):
new_image, rects = park.identify_blocks(image, lines)
rect_images.append(new_image)
rect_coords.append(rects)
park.show_images(rect_images)
delineated = []
spot_pos = []
for image, rects in zip(test_images, rect_coords):
new_image, spot_dict = park.draw_parking(image, rects)
delineated.append(new_image)
spot_pos.append(spot_dict)
park.show_images(delineated)
final_spot_dict = spot_pos[1]
print(len(final_spot_dict))
with open('spot_dict.pickle', 'wb') as handle:
pickle.dump(final_spot_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
park.save_images_for_cnn(test_images[0], final_spot_dict)
return final_spot_dict
这段代码定义在主程序文件中,但是用到park类中的函数,主要执行图片预处理操作
3.1 select_rgb_white_yellow函数
def select_rgb_white_yellow(self, image):
#这些值被转换为无符号8位整数(np.uint8),用于指定颜色过滤的下限。
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# lower_red和高于upper_red的部分分别变成0,lower_red~upper_red之间的值变成255,相当于过滤背景
white_mask = cv2.inRange(image, lower, upper)
#码将突出显示图像中的白色区域
self.cv_show('white_mask', white_mask)
#这将保留图像中被掩码标记为白色的部分,同时将其余部分过滤掉。
masked = cv2.bitwise_and(image, image, mask=white_mask)
self.cv_show('masked', masked)
return masked我认为这段函数通俗来讲是保留图像中的浅色区域,具体来说,就是保留接近白色或黄色的区域。
执行后效果:


3.1.1cv_show
def cv_show(self, name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()一段简单的展示图片的函数
3.2 convert_gray_scale
def convert_gray_scale(self, image):
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)简单的彩色转灰度图像函数
执行后效果:

3.3 detect_edges
def detect_edges(self, image, low_threshold=50, high_threshold=200):
return cv2.Canny(image, low_threshold, high_threshold)边缘检测函数
执行后效果:

3.4 select_region
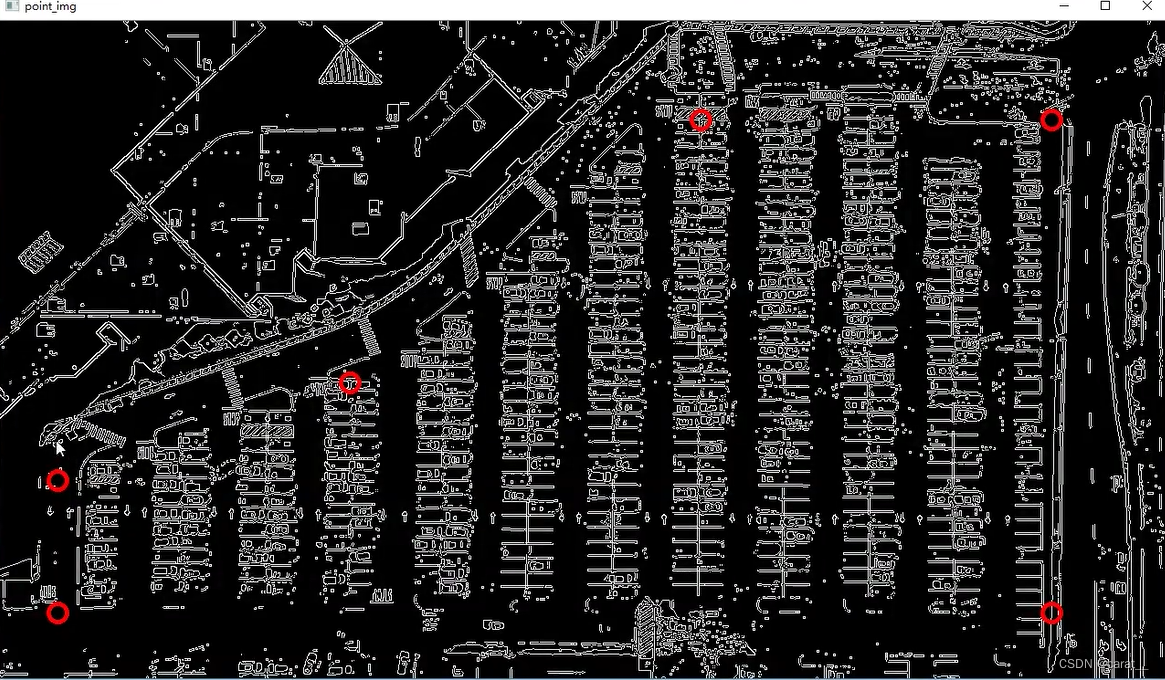
def select_region(self, image):
"""
手动选择区域
"""
# first, define the polygon by vertices
#拿到图像长和宽
rows, cols = image.shape[:2]
pt_1 = [cols * 0.05, rows * 0.90]
pt_2 = [cols * 0.05, rows * 0.70]
pt_3 = [cols * 0.30, rows * 0.55]
pt_4 = [cols * 0.6, rows * 0.15]
pt_5 = [cols * 0.90, rows * 0.15]
pt_6 = [cols * 0.90, rows * 0.90]
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
#演示画图
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2RGB)
for point in vertices[0]:
#传进来时元组,指定了(point[0], point[1])(x,y)坐标,什么颜色画,画的大小
cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4)
self.cv_show('point_img', point_img)
#过滤操作
return self.filter_region(image, vertices)通过这六个点选中想要的区域
3.4.1 filter_region
def filter_region(self, image, vertices):
"""
剔除掉不需要的地方
"""
mask = np.zeros_like(image)
#检查 mask 的维度,以确定它是否为二维数组。如果是二维数组,那么继续执行过滤操作。
if len(mask.shape) == 2:
#用顶点把mask填充起来
cv2.fillPoly(mask, vertices, 255)
self.cv_show('mask', mask)
#保留mask白色部分,相当于过滤掉背景
return cv2.bitwise_and(image, mask)执行后操作:


3.5 hough_lines
def hough_lines(self, image):
# 输入的图像需要是边缘检测后的结果
# minLineLengh(线的最短长度,比这个短的都被忽略)和MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线)
# rho距离精度,theta角度精度,threshod超过设定阈值才被检测出线段
return cv2.HoughLinesP(image, rho=0.1, theta=np.pi / 10, threshold=15, minLineLength=9, maxLineGap=4)检测停车场的直线
3.6 draw_lines
def draw_lines(self, image, lines, color=[255, 0, 0], thickness=2, make_copy=True):
# 过滤霍夫变换检测到直线
if make_copy:
image = np.copy(image)
#对线进行过滤
cleaned = []
for line in lines:
for x1, y1, x2, y2 in line:
#过滤掉斜线、长度不对的线
if abs(y2 - y1) <= 1 and abs(x2 - x1) >= 25 and abs(x2 - x1) <= 55:
cleaned.append((x1, y1, x2, y2))
cv2.line(image, (x1, y1), (x2, y2), color, thickness)
print(" No lines detected: ", len(cleaned))
return image
先过滤后画线展示图片。
cv2.line 是 OpenCV 库中用于在图像上绘制直线的函数。它的语法如下:
cv2.line(img, pt1, pt2, color, thickness=1, lineType=cv2.LINE_8, shift=0)
执行后结果:

可以看出效果不是特别好,有些被车挡住的线没有画出来,可以增加预处理操作。
3.7 identify_blocks
def identify_blocks(self, image, lines, make_copy=True):
if make_copy:
new_image = np.copy(image)
# Step 1: 过滤部分直线
cleaned = []
for line in lines:
for x1, y1, x2, y2 in line:
if abs(y2 - y1) <= 1 and abs(x2 - x1) >= 25 and abs(x2 - x1) <= 55:
cleaned.append((x1, y1, x2, y2))
# Step 2: 对直线按照x1进行排序
import operator
#itemgetter(0, 1)基于每个元素的第一个和第二个索引处的值进行的
list1 = sorted(cleaned, key=operator.itemgetter(0, 1))
# Step 3: 找到多个列,相当于每列是一排车
clusters = {}
dIndex = 0
#指定的列间距
clus_dist = 10
for i in range(len(list1) - 1):
#第一条和第二条线比较
distance = abs(list1[i + 1][0] - list1[i][0])
if distance <= clus_dist:
if not dIndex in clusters.keys(): clusters[dIndex] = []
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i + 1])
else:
dIndex += 1
# Step 4: 得到坐标
rects = {}
i = 0
for key in clusters:
all_list = clusters[key]
#将 all_list 转换为一个集合,以去除重复元素,然后将集合转换回列表赋值给 cleaned。
cleaned = list(set(all_list))
if len(cleaned) > 5:
#对 cleaned 列表进行排序,排序的依据是每个元组的第二个元素y1。
cleaned = sorted(cleaned, key=lambda tup: tup[1])
#第一条线
avg_y1 = cleaned[0][1]
#最后一条线
avg_y2 = cleaned[-1][1]
avg_x1 = 0
avg_x2 = 0
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
#x算平均值
avg_x1 = avg_x1 / len(cleaned)
avg_x2 = avg_x2 / len(cleaned)
#使用计算出的平均值更新 rects 列表中的第 i 个元素,形成一个包含四个元素的元组。
rects[i] = (avg_x1, avg_y1, avg_x2, avg_y2)
i += 1
print("Num Parking Lanes: ", len(rects))
# Step 5: 把列矩形画出来
#用于在每个矩形的边界上添加额外的像素。防止矩形太小
buff = 7
for key in rects:
#左上角坐标
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
#右下角
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return new_image, rects
执行后结果:

由于1图画的不好,下一步指定位置时都按照2图的矩形框指定位置。
3.8 draw_parking
def draw_parking(self, image, rects, make_copy=True, color=[255, 0, 0], thickness=2, save=True):
if make_copy:
new_image = np.copy(image)
#固定车位宽度15.5
gap = 15.5
spot_dict = {} # 字典:一个车位对应一个位置
tot_spots = 0
# 微调数值
adj_y1 = {0: 20, 1: -10, 2: 0, 3: -11, 4: 28, 5: 5, 6: -15, 7: -15, 8: -10, 9: -30, 10: 9, 11: -32}
adj_y2 = {0: 30, 1: 50, 2: 15, 3: 10, 4: -15, 5: 15, 6: 15, 7: -20, 8: 15, 9: 15, 10: 0, 11: 30}
adj_x1 = {0: -8, 1: -15, 2: -15, 3: -15, 4: -15, 5: -15, 6: -15, 7: -15, 8: -10, 9: -10, 10: -10, 11: 0}
adj_x2 = {0: 0, 1: 15, 2: 15, 3: 15, 4: 15, 5: 15, 6: 15, 7: 15, 8: 10, 9: 10, 10: 10, 11: 0}
for key in rects:
tup = rects[key]
#进行微调
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1] + adj_y1[key])
y2 = int(tup[3] + adj_y2[key])
cv2.rectangle(new_image, (x1, y1), (x2, y2), (0, 255, 0), 2)
#这一列一共能停多少辆车,切多少刀
num_splits = int(abs(y2 - y1) // gap)
for i in range(0, num_splits + 1):
y = int(y1 + i * gap)
#横线
cv2.line(new_image, (x1, y), (x2, y), color, thickness)
if key > 0 and key < len(rects) - 1:
# 竖直线,考虑第一个和最后一个是单排不画竖直线
x = int((x1 + x2) / 2)
cv2.line(new_image, (x, y1), (x, y2), color, thickness)
# 计算车位数量
if key == 0 or key == (len(rects) - 1):
tot_spots += num_splits + 1
else:
#双排的要乘二
tot_spots += 2 * (num_splits + 1)
# 字典对应好
if key == 0 or key == (len(rects) - 1):
for i in range(0, num_splits + 1):
#算一下当前是第几个,就是key值
cur_len = len(spot_dict)
y = int(y1 + i * gap)
#车位坐标
spot_dict[(x1, y, x2, y + gap)] = cur_len + 1
else:
for i in range(0, num_splits + 1):
cur_len = len(spot_dict)
y = int(y1 + i * gap)
x = int((x1 + x2) / 2)
spot_dict[(x1, y, x, y + gap)] = cur_len + 1
spot_dict[(x, y, x2, y + gap)] = cur_len + 2
print("total parking spaces: ", tot_spots, cur_len)
if save:
filename = 'with_parking.jpg'
cv2.imwrite(filename, new_image)
return new_image, spot_dict把每个车位划分出来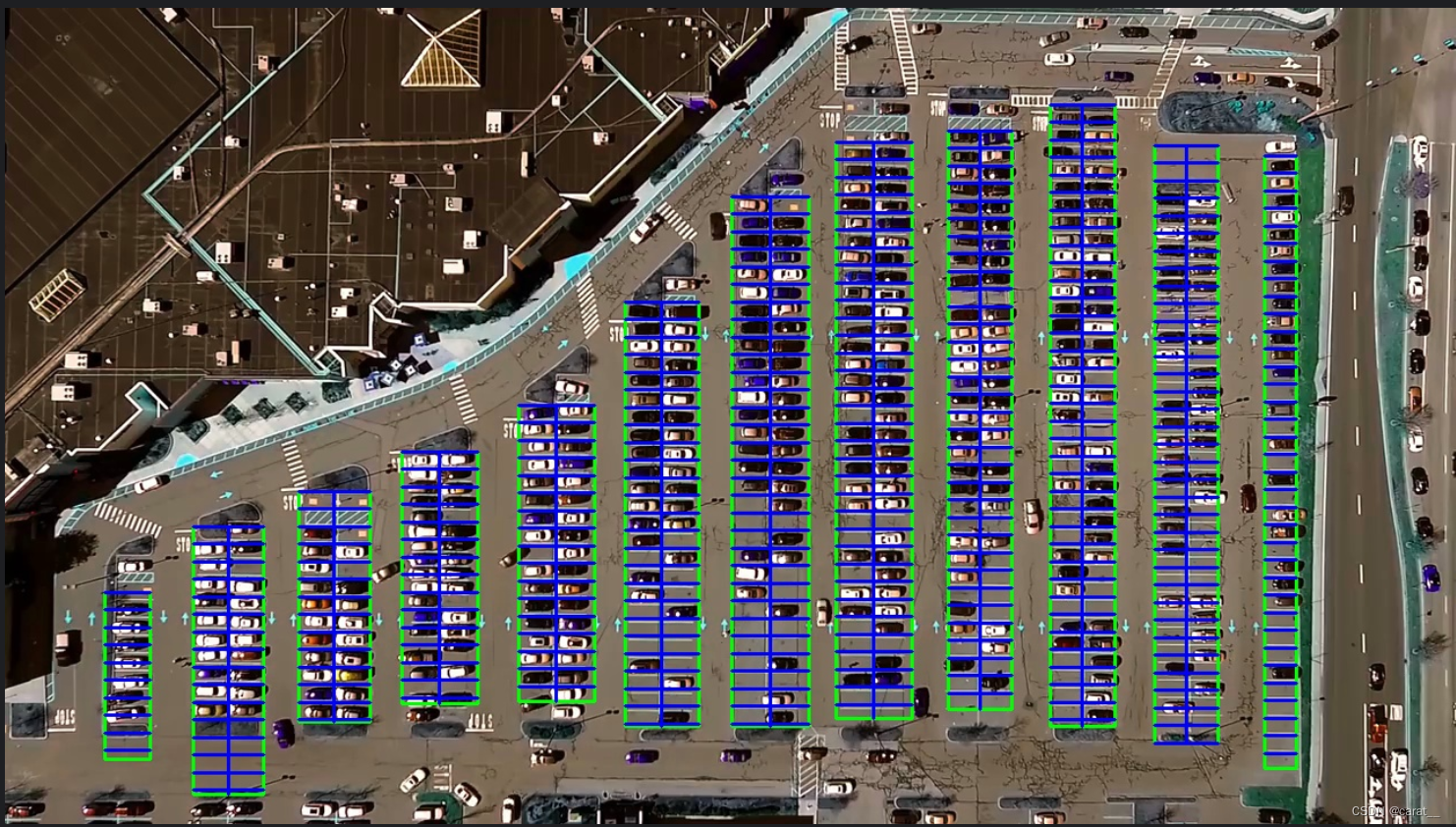
3.9 主函数的pickle.dump
#把结果保存一下
# 'wb' 表示以二进制写入模式(w 写入,b 二进制)打开文件
with open('spot_dict.pickle', 'wb') as handle:
pickle.dump(final_spot_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)调用 pickle 模块的 dump 函数来序列化 final_spot_dict 对象。将 final_spot_dict 字典对象保存到磁盘上的 .pickle 文件中,以便以后可以重新加载它。
3.10 save_images_for_cnn
def save_images_for_cnn(self, image, spot_dict, folder_name='cnn_data'):
#对于每个停车位
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
# 把该停车位从图片中裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0, 0), fx=2.0, fy=2.0)
spot_id = spot_dict[spot]
#保存
filename = 'spot' + str(spot_id) + '.jpg'
print(spot_img.shape, filename, (x1, x2, y1, y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)把每个车位从图片中裁剪出来为了接下来神经网络训练识别

4. keras_model模型训练
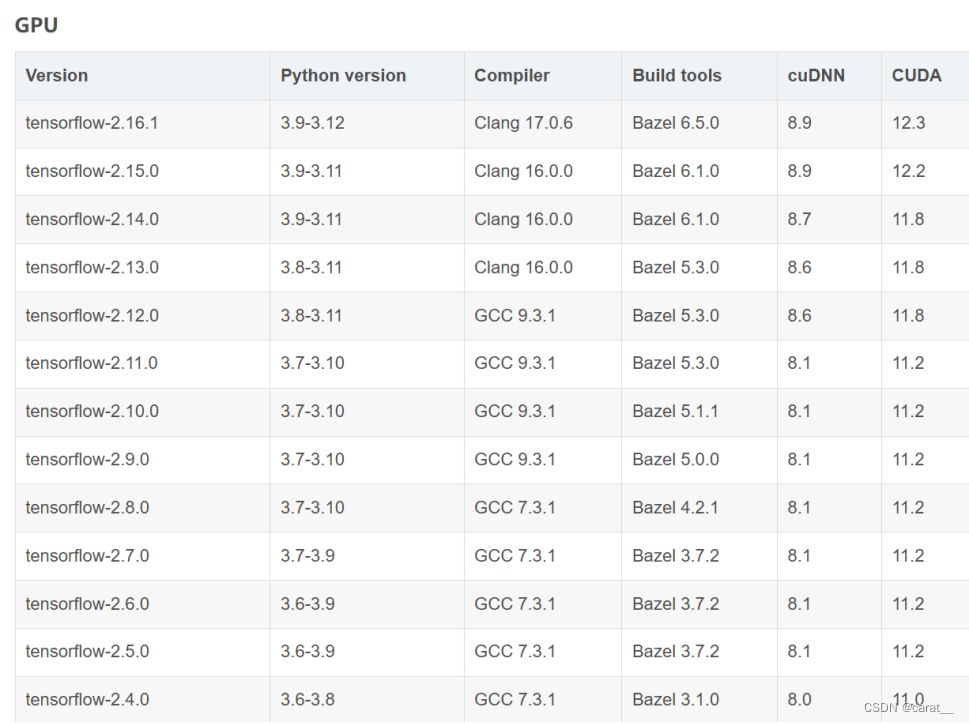
这里为了使用keras网络模型,配置部分首先需要安装tensorflow作为后端,安装tensorflow最好安装GPU版本运行更快,在安装GPU版本之前,电脑要下载安装好CUDA和cunn,具体可以去找教程,作为新手我在环境配置方面也耗费了一些时间,希望以后可以越来越熟练。知识部分关于深度学习keras网络可以提前学习一下可以更好理解这部分。
说一下我安装tensorflow走的弯路:一个是python、cuda、cudnn、tensorflow这四个版本要匹配,匹配图见下图;一个是tensorflow2.11的GPU版本2.11及以后不适合在windows安装了,我发现这个之后只能把python、cuda、cudnn全部降低版本重装。
需要新建一个train的py文件,代码如下:
import numpy
import os
from keras import applications
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.models import Sequential, Model
from keras.layers import Dropout, Flatten, Dense, GlobalAveragePooling2D
from keras import backend as k
from keras.callbacks import ModelCheckpoint, LearningRateScheduler, TensorBoard, EarlyStopping
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
import h5py
import tf_slim as slim
files_train = 0
files_validation = 0
cwd = os.getcwd()
folder = 'train_data/train'
for sub_folder in os.listdir(folder):
path, dirs, files = next(os.walk(os.path.join(folder,sub_folder)))
files_train += len(files)
folder = 'train_data/test'
for sub_folder in os.listdir(folder):
path, dirs, files = next(os.walk(os.path.join(folder,sub_folder)))
files_validation += len(files)
print(files_train,files_validation)
img_width, img_height = 48, 48
train_data_dir = "train_data/train"
validation_data_dir = "train_data/test"
nb_train_samples = files_train
nb_validation_samples = files_validation
batch_size = 32
epochs = 15
num_classes = 2
model = applications.VGG16(weights='imagenet', include_top=False, input_shape = (img_width, img_height, 3))
for layer in model.layers[:10]:
layer.trainable = False
x = model.output
x = Flatten()(x)
predictions = Dense(num_classes, activation="softmax")(x)
model_final = Model(input = model.input, output = predictions)
model_final.compile(loss = "categorical_crossentropy",
optimizer = optimizers.SGD(lr=0.0001, momentum=0.9),
metrics=["accuracy"])
train_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.1,
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=5)
test_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.1,
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=5)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size = (img_height, img_width),
batch_size = batch_size,
class_mode = "categorical")
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size = (img_height, img_width),
class_mode = "categorical")
checkpoint = ModelCheckpoint("car1.h5", monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
early = EarlyStopping(monitor='val_acc', min_delta=0, patience=10, verbose=1, mode='auto')
history_object = model_final.fit_generator(
train_generator,
samples_per_epoch = nb_train_samples,
epochs = epochs,
validation_data = validation_generator,
nb_val_samples = nb_validation_samples,
callbacks = [checkpoint, early])大概流程:

5.主函数的keras_model
用keras提供的函数,把car1.h5读取进来
6. 图片测试
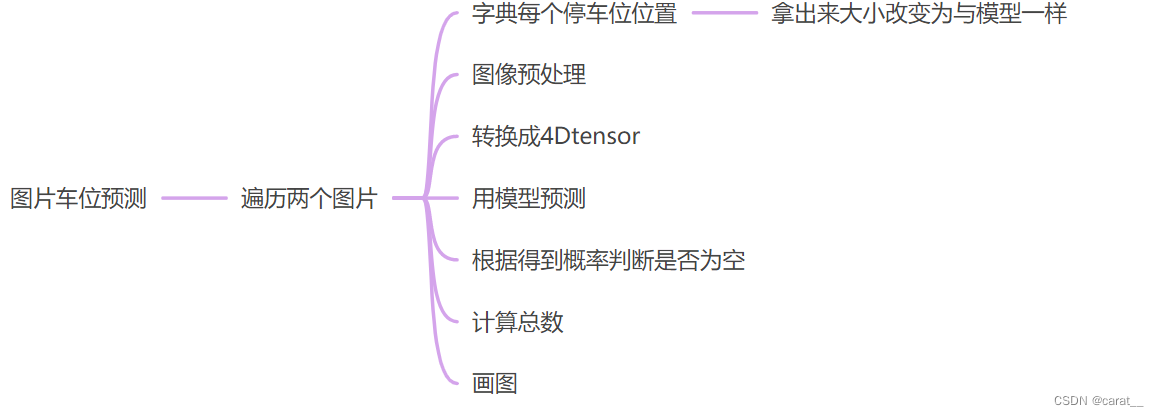
def img_test(test_images, final_spot_dict, model, class_dictionary):
for i in range(len(test_images)):
predicted_images = park.predict_on_image(test_images[i], final_spot_dict, model, class_dictionary)
6.1 图片预测predict_on_image
def predict_on_image(self, image, spot_dict, model, class_dictionary, make_copy=True, color=[0, 255, 0], alpha=0.5):
if make_copy:
new_image = np.copy(image)
overlay = np.copy(image)
self.cv_show('new_image', new_image)
cnt_empty = 0
all_spots = 0
for spot in spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
save = False
if save:
filename = 'with_marking.jpg'
cv2.imwrite(filename, new_image)
self.cv_show('new_image', new_image)
return new_image6.1.1 make_prediction
def make_prediction(self, image, model, class_dictionary):
# 预处理
img = image / 255.
# 转换成4D tensor
image = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(image)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
return label
整体流程大概是:
7. 视频测试
def video_test(video_name, final_spot_dict, model, class_dictionary):
name = video_name
cap = cv2.VideoCapture(name)
park.predict_on_video(name, final_spot_dict, model, class_dictionary, ret=True)7.1 predict_on_video
def predict_on_video(self, video_name, final_spot_dict, model, class_dictionary, ret=True):
cap = cv2.VideoCapture(video_name)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = np.copy(image)
overlay = np.copy(image)
cnt_empty = 0
all_spots = 0
color = [0, 255, 0]
alpha = 0.5
for spot in final_spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
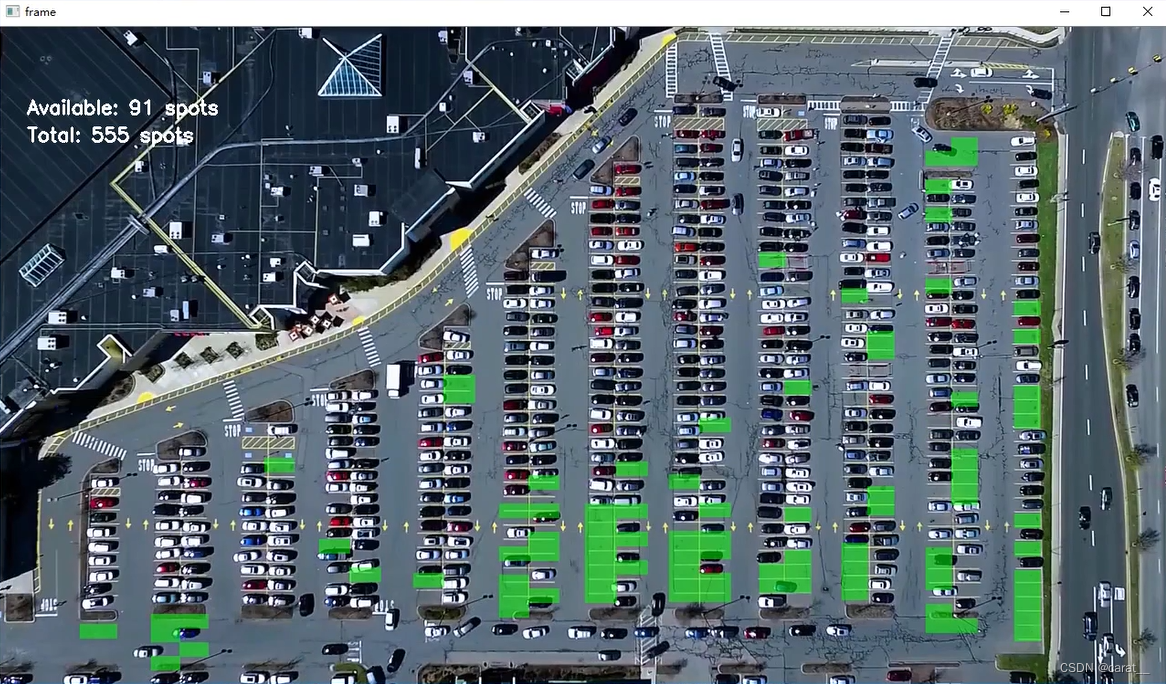
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()视频预测就是把视频一帧一帧提出来之后,每张图片按照图片预测方式去做
结果如下:















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









