









一、PDF字体相关概念
1.PDF字体对象
PDF中的字体对象是对数码字体的描述,他可以描述字体的特征(非嵌入),也可以是嵌入式的字体。可以嵌入的字体文件基于广泛使用的标准数字字体格式:Type 1(及其压缩的变体CFF),也可以是TrueType(从PDF 1.6开始)和OpenType。
2.标准Type1
字体包含14中字体,被称为Base14,这些字体或有相同度量的合适的替代字体,必须能用在所有PDF阅读器上,而且不必嵌入PDF,并且只有在系统安装该字体才能正常显示。
3.嵌入字体
又可分为嵌入子集与全部嵌入,嵌入子集对于非后续再编辑、阅读、打印可满足其需求,只嵌入使用的字符,文件大小相对较小,而且不会因为系统未安装此字体造成其无法显示或打印。全部嵌入则对于后续再编辑时,需要修改其对应字体的文字内容,全部嵌入字体会导致pdf文件增大。
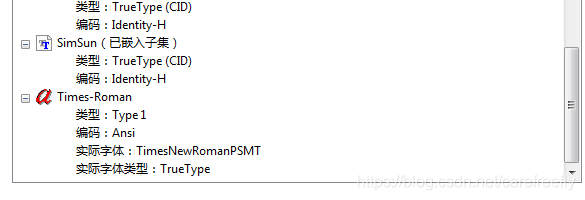
如下图,Puritan2 为Type1字体完全嵌入,STKaiti 为大型字体嵌入子集,STSong-Light Type1字体非嵌入,该信息为在PDF阅读器中显示对应的字体属性。

4.字体编码
文本字符串中,字符用以编码映射字形于当前字体的字符代码(整数)显示,预定义的编码有多种,包括WinAnsi、MacRoman,以及大量东亚语言编码,而且字体可以有自己的编码。
PDF中的编码机制是Type 1字体,对于大型字体或者带非标准字形的字体,使用特殊编码Identity-H(用于水平书写)和Identity-V(用于垂直书写)。如果关于字符的语义信息被预定义,这类字体有必要提供ToUnicode表。
5.字符编码(字符集)
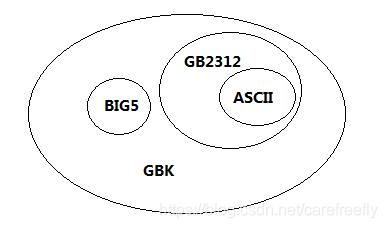
GB2312
信息交换用汉字编码字符集(不支持生僻字的字符集,这是其本身限制的问题)。GB2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符(包括6763个汉字和682个其它符号)。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
这6763个汉字在Unicode中不是连续的,分布在CJK统一汉字字符区(0x4E00-0x9FA5)的20902个汉字中。
GBK
汉字编码字符集,向下与GB2312兼容(支持生僻字的字符集)。
1995年的汉字扩展规范GBK1.0收录了21886个符号,包括21003个汉字和883个其它符号。
这21003汉字包括CJK统一汉字区的20902个汉字。余下的101个汉字包括:增补汉字和部首80个,包括28个部首和52个汉字。GBK编码是从FE50-FE7E,FE80-FEA0。
GB 18030
全称是GB18030-2000,GB 18030字符集标准解决汉字、日文假名、朝鲜语和中国少数民族文字组成的大字符集计算机编码问题。该标准的字符总编码空间超过150万个编码位,收录了27484个汉字,覆盖中文、日文、朝鲜语和中国少数民族文字。满足中国大陆、香港、台湾、日本和韩国等东亚地区信息交换多文种、大字量、多用途、统一编码格式的要求。并且与Unicode 3.0版本兼容,填补Unicode扩展字符字汇“统一汉字扩展A”的内容。并且与以前的国家字符编码标准(GB2312,GB13000.1)兼容。
Unicode
如上ANSI编码条例中所述,世界上存在着多种编码方式,在ANSi编码下,同一个编码值,在不同的编码体系里代表着不同的字。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。在ANSI编码体系下,要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。为什么电子邮件和网页都经常会出现乱码,就是因为信息的提供者可能是日文的ANSI编码体系和信息的读取者可能是中文的编码体系,他们对同一个二进制编码值进行显示,采用了不同的编码,导致乱码。这个问题促使了unicode码的诞生。
如果有一种编码,将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。这就是Unicode编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,“汉”这个字的Unicode编码是U+6C49。
Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。
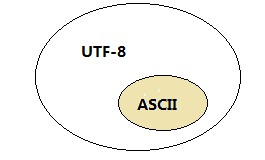
UTF-8
为了提高Unicode的编码效率,于是就出现了UTF-8编码,又称万国码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。
6.字符编码关系
7.常用字体字符统计
常用字有7000个左右,汉字的数量并没有准确数字,大约将近十万个,目前最权威的北京国安资讯设备公司汉字字库共收入汉字91251个。
而目前的单一字体无法全部覆盖,目前常用的字体收录字数:
- 中易宋体 (SimSun) 收字 28762 个;
- 华文细黑收字 37256 个;
- OS X 自带的华文黑体 (黑体-简) 中,细体收字达 52268 个;
- 思源黑体收录的字符数则占满了 OpenType 的上限 65536 个;
8.常用字体字符统计
二、动态数据PDF生成环节
一般情况下动态PDF生成环节主要包括数据录入环节,数据落库环节,数据传输环节,PDF生成环节。
录入环节:主要是在客户端输入法录入,与输入法和本地系统字库相关。
数据库落库环节:与数据库的字符集相关,字符集范围越大则能容纳的字符类型就越多。
接口传输环节:避免传输过程中,点对点的字符集不一致,大致字符集合转换编码缺失。
PDF生成:生成环节则涉及到PDF中的字体显示项对应的字体映射处理。
三、PDF生僻字处理方式
PDF的一个很大的优势就是字体的格式、信息、多媒体等等可以全部镶嵌在文档中,不同的操作系统打开不会因为操作系统和分辨率不同而导致样式的变化。因此PDF文件不像HTML那样,会随着系统相关参数变化进行自适应,例如HTML会根据字体在系统的安装情况,按优先级进行自动选择。
随之而来的问题就是在使用动态数据进行合成PDF时,数据中的动态文字不包含在对应的字体中,合成后的PDF无法展示该文字(不同于HTML可以指定多个字体),出现乱码或空白的情况。
综合PDF的特性以及PDF对字体的处理方式,可以通过两种方式来处理生僻字的显示。
1.使用覆盖大多数文字的字体
处理方式:对某一段出现生僻字的文字进行设置指定字库较全的字体。
优点:处理方式简单。
缺点:依赖某种字体。字体样式选择性被局限,如果生僻字出现的位置较多,那么只能使用一种字体在文档中。
目前谷歌和adobe的思源字体也正是为了解决字库不全而设立的开源字体,随着时间的推移会逐渐完善其字体数量,并能够覆盖所有的生僻字。
2.组合覆盖大多数字符集文字
处理方式:通过配置对于无法显示生僻字指定相应的字体,通过算法过滤文本,并对该文字指定能够正确显示的字体。
优点:有针对性的处理生僻字的字体显示,不局限某一个字体,对其他字体的选择没有限制。
缺点:需要不断调整配置来适应生僻字的显示,对于文本的处理会消耗一些系统资源和性能。
四、开源框架中对字体的设置
以IText5为例
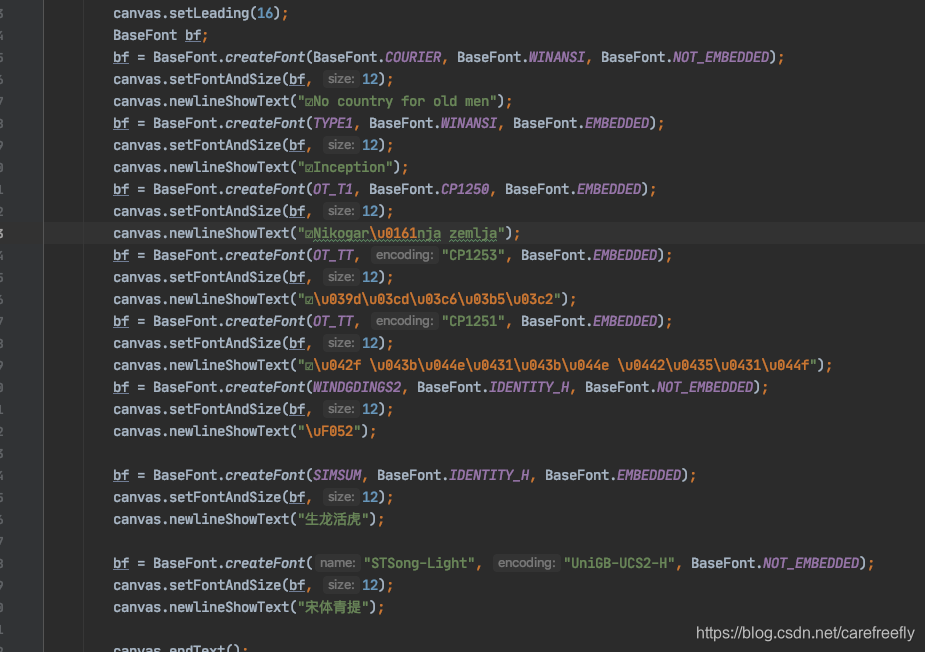
在Itext中的设置字体绑定属性,在PDF中的表现形式
| 字体类型 | 字体绑定类型 | 实际PDF字体形态 |
| 标准字体(STSong-Light) | NOT_EMBEDDED | 不显示嵌入说明 |
| 标准字体(STSong-Light) | EMBEDDED | 不显示嵌入说明 |
| 非标准字体(Puritan2) | NOT_EMBEDDED | 不显示嵌入说明 |
| 非标准字体(Puritan2) | EMBEDDED | (已嵌入) |
| 大型字体(Wingdings2) | NOT_EMBEDDED | (已嵌入子集) |
| 大型字体(Wingdings2) | EMBEDDED | (已嵌入子集) |

对于生产打印机来说,已嵌入,已嵌入子集是比较安全的字体属性,对嵌入属性的标准Type1字体需要依赖打印机中的字体是否符合adobe标准,否则有可能会出现字体无法打印的情况。
五、生僻字测试
系统安装生僻字字体花园明朝HanaMinB,生僻字 "䶮𠇔·𮧵㵘",“䶮㵘”部分字体支持,”𮧵“目前系统字体只有HanaMinB支持。
网页富文本大部分可正常显示。
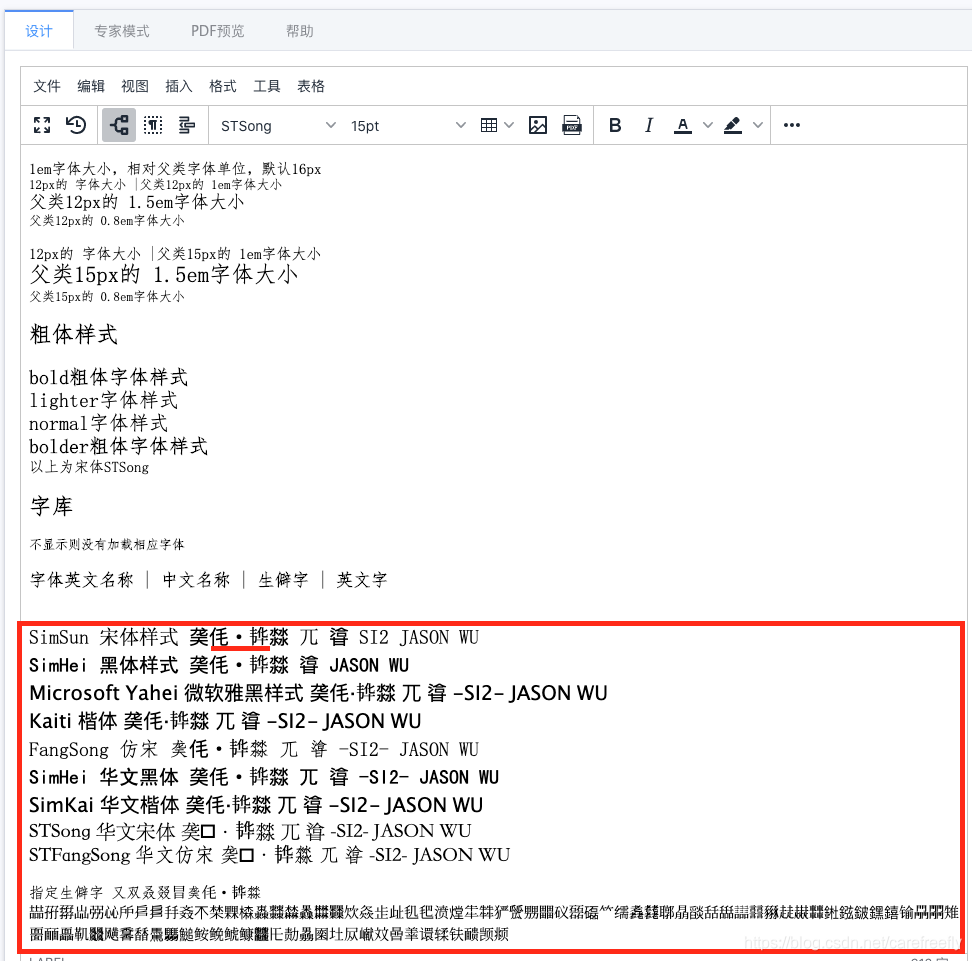
通过对”𠇔𮧵“处理,动态指定其字体效果
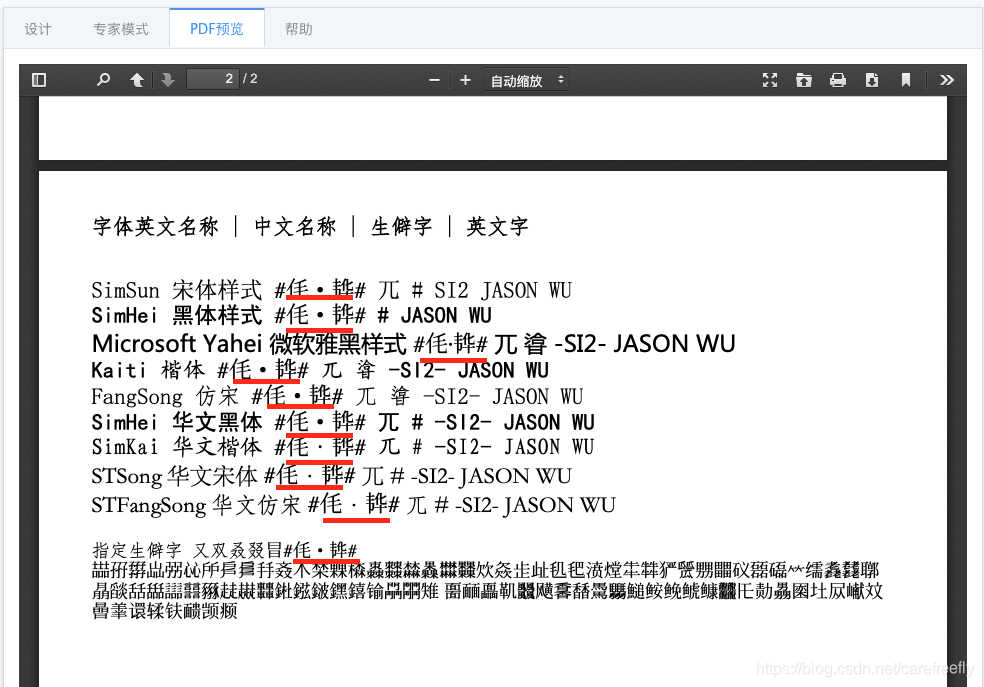
屏蔽系统中的花园明朝HanaMinB,页面无法正常显示”𮧵“,以及下方的生僻字。
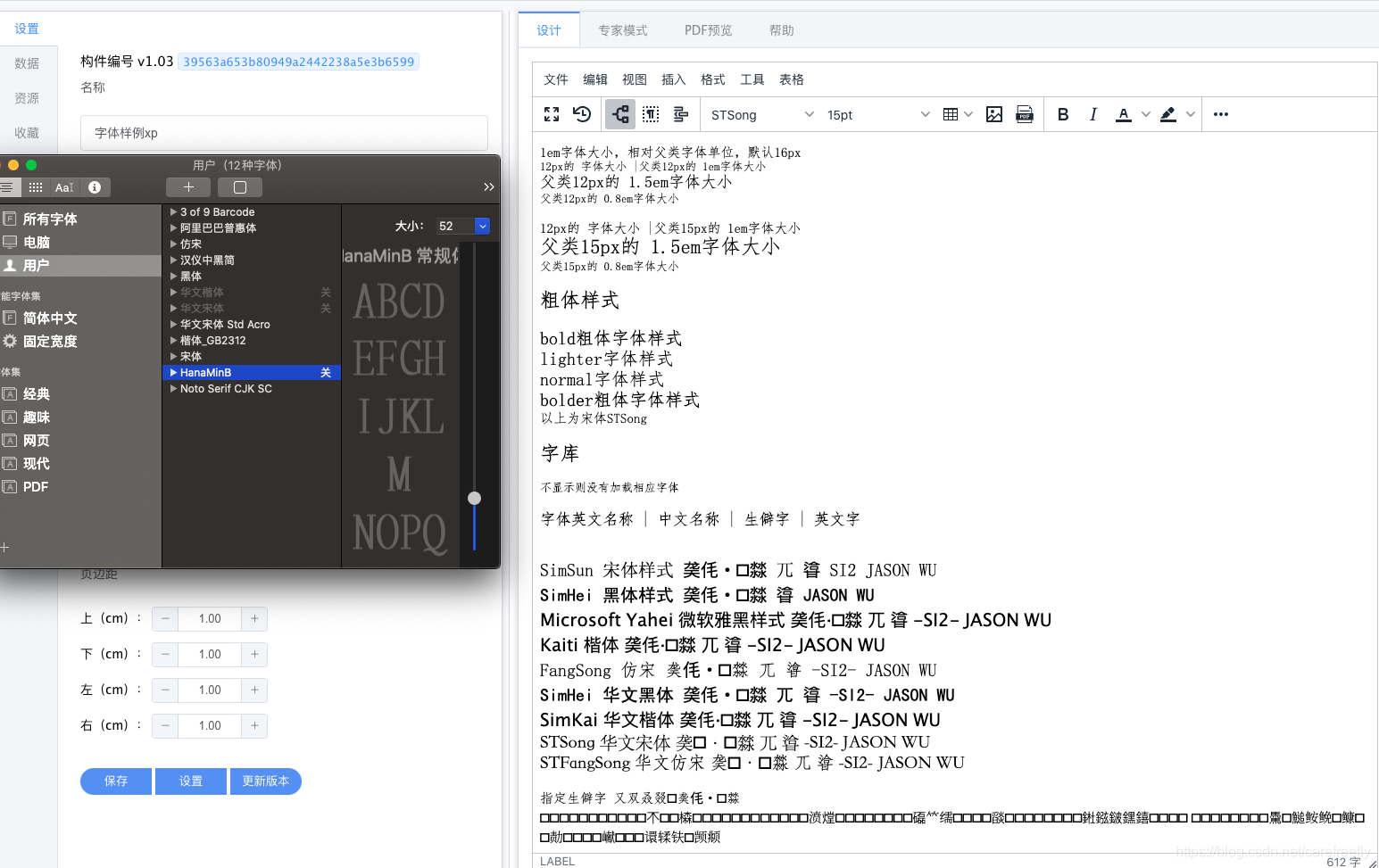
PDF中对相应的生僻字进行动态指定处理后,”𮧵“以及下方生僻字依然可正常显示。
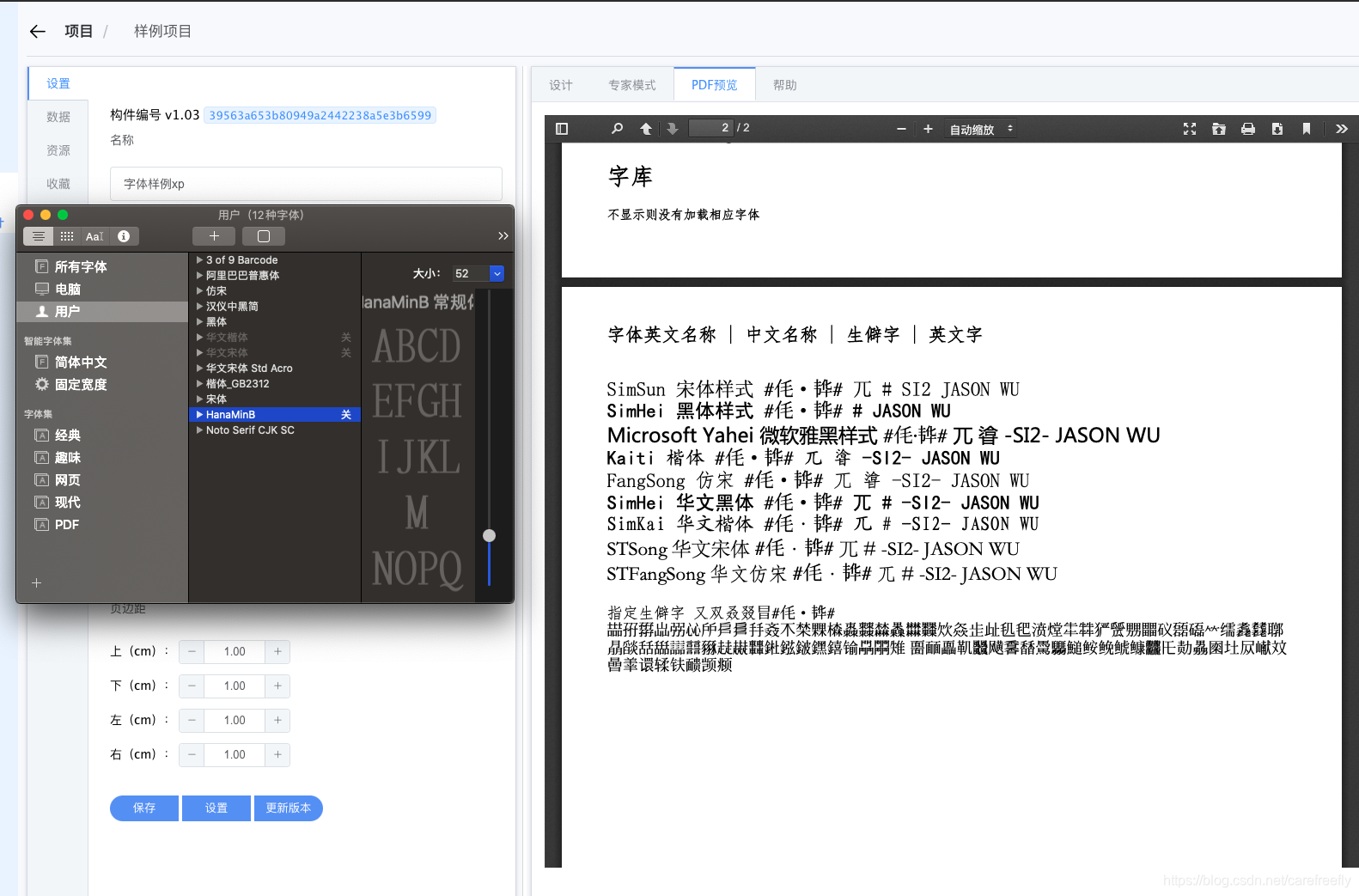
最新版本的openhtmltopdf已支持指定多个字体,动态匹配对应的字库。
整合html模板+数据的生成工具项目:
 https://gitee.com/Rayin/rayin
https://gitee.com/Rayin/rayin
















 3794
3794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









