







HBase工作原理学习
1 HBase简介
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建大规模结构化的存储集群。HBase的目标是存储并处理大型数据,具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
与MapReduce的离线批处理计算框架不同,HBase是一个可以随机访问的存储和检索数据平台,弥补了HDFS不能随机访问数据的缺陷,适合实时性要求不是非常高的业务场景。HBase存储的都是Byte数组,它不介意数据类型,允许动态、灵活的数据模型。
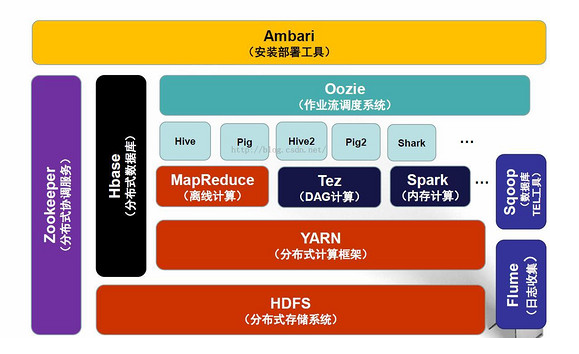
上图描述了Hadoop 2.0生态系统中的各层结构。其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBase提供了高性能的批处理能力,Zookeeper为HBase提供了稳定服务和failover机制,Pig和Hive为HBase提供了进行数据统计处理的高层语言支持,Sqoop则为HBase提供了便捷的RDBMS数据导入功能,使业务数据从传统数据库向HBase迁移变的非常方便。
2 HBase体系结构
2.1 设计思路
HBase是一个分布式的数据库,使用Zookeeper管理集群,使用HDFS作为底层存储。在架构层面上由HMaster(Zookeeper选举产生的Leader)和多个HRegionServer组成,基本架构如下图所示:
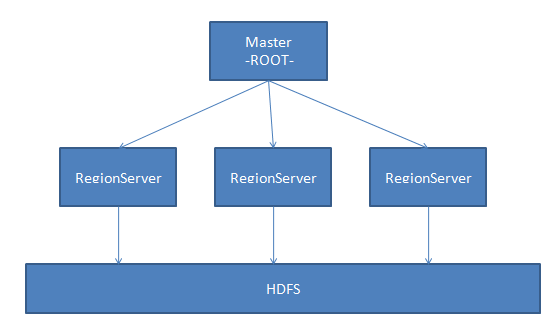
在HBase的概念中,HRegionServer对应集群中的一个节点,一个HRegionServer负责管理多个HRegion,而一个HRegion代表一张表的一部分数据。在HBase中,一张表可能会需要很多个HRegion来存储数据,每个HRegion中的数据并不是杂乱无章的。HBase在管理HRegion的时候会给每个HRegion定义一个Rowkey的范围,落在特定范围内的数据将交给特定的Region,从而将负载分摊到多个节点,这样就充分利用了分布式的优点和特性。另外,HBase会自动调节Region所处的位置,如果一个HRegionServer过热,即大量的请求落在这个HRegionServer管理的HRegion上,HBase就会把HRegion移动到相对空闲的其它节点,依次保证集群环境被充分利用。
2.2 基本架构
HBase由HMaster和HRegionServer组成,同样遵从主从服务器架构。HBase将逻辑上的表划分成多个数据块即HRegion,存储在HRegionServer中。HMaster负责管理所有的HRegionServ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









