







hash的应用场景:
- 网络爬虫程序,怎么让它不去爬相同的 url 页面?
- 垃圾邮件过滤算法如何设计?
- 缓存穿透问题如何解决?
典型要点和应用:hash函数以及冲突原理
散列表
布隆过滤器
hyperloglog
分布式一致性hash
基本概念:
散列表:根据 key 计算 key 在表中的位置的数据结构;是 key 和其所在存储地址的映射关系;
hash函数:映射函数 Hash(key)=addr ;hash 函数可能会把两个或两个以上的不同 key 映射到同一地址,这
种情况称之为冲突(或者 hash 碰撞);
选择hash:计算速度快、强随机分布(等概率、均匀地分布在整个地址空间)
冲突处理:链表法:常用方法,但缺点的易产生冲突链过长,一般超过256时转化为红黑树,将时间复杂度从O(n)降至O()
开发寻址法:有线性探测(常用)、平方探测、再散列和伪随机序列法
布隆过滤器:
是一种概率型数据结构,它的特点是高效地插入和查询,能确定某个字符串一定不存在
或者可能存在;不存储具体数据,所以占用空间小,查询结果存在误差,但是误差可控,同时不支持删除操作;其原因是因为一个元素加入位图时,通过k 个 hash 函数将这个元素映射到位图的 k 个点,并把它们置为 1;因此检索时,通过k个hash函数检测位图,如果有某一位图的值为0,则该key一定不存在;如果全为1,也只能是可能存在,因为其他key值的组合映射也可能将该key的映射bit位图置为1。如下图所示
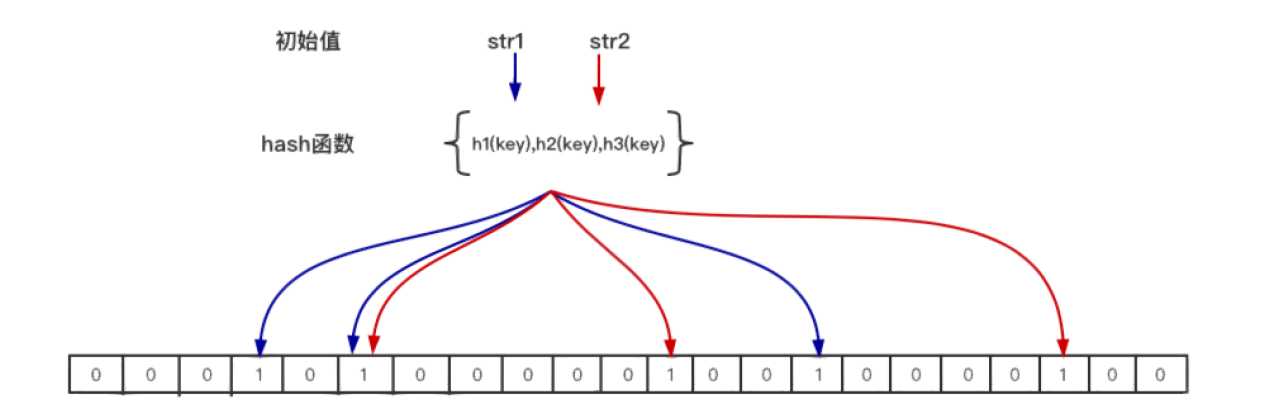
总结:布隆过滤器通常用于判断某个 key 一定不存在的场景,同时允许判断存在时有误差的情况;
常见处理场景:① 缓存穿透的解决;② 热 key 限流;
使用步骤:在实际使用布隆过滤器时,首先需要确定 n 和 p,通过上面的运算得出 m 和 k;通常可以在下面这个网站上选出合适的值;https://hur.st/bloomfilter
分布式一致性 hash
分布式一致性 hash 算法将哈希空间组织成一个虚拟的圆环,圆环的大小是 ;
算法: hash(ip)% ,最终会得到一个 [0,
-1 ]之间的一个无符号整型,这个整数代表
服务器的编号;多个服务器都通过这种方式在 hash 环上映射一个点来标识该服务器的位置;当用
户操作某个 key,通过同样的算法生成一个值,沿环顺时针定位某个服务器,那么该 key 就在该服
务器中;图片来自互联网,见下图:
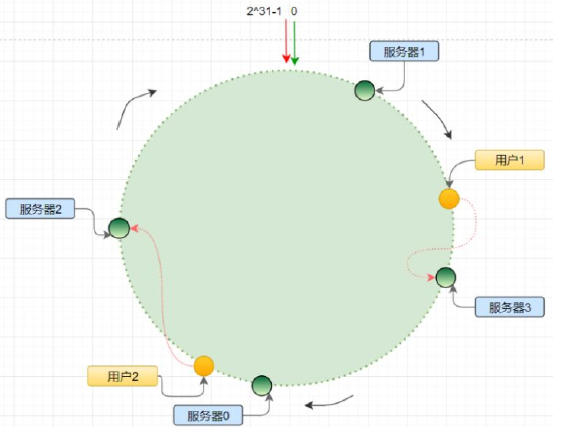
应用场景:分布式缓存;将数据均衡地分散在不同的服务器当中,用来分摊缓存服务器的压力;
解决缓存服务器数量变化尽量不影响缓存失效;
hash偏移:
hash 算法得到的结果是随机的,不能保证服务器节点均匀分布在哈希环上;分布不均匀造成请求
访问不均匀,服务器承受的压力不均匀;图片来自互联网,见下图

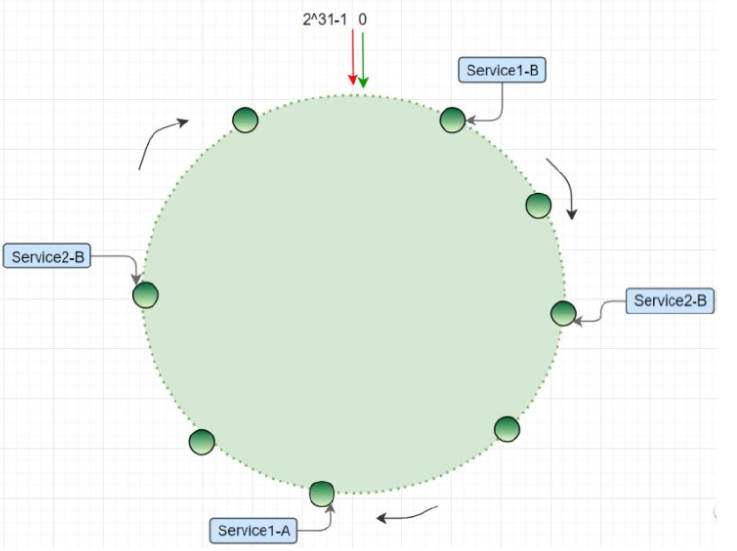
虚拟节点:
为了解决哈希偏移的问题,增加了虚拟节点的概念;理论上,哈希环上节点数越多,数据分布越均衡;为每个服务节点计算多个哈希节点(虚拟节点)通常做法是:hash("IP:PORT:seqno")%;图片来自互联网,见下图
本专栏知识点是通过<零声教育>的线上课学习,进行梳理总结写下文章,对c/c++linux课程感兴趣的读者,可以点击链接,详细查看课程的服务:















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









