







欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/131565908
AWPortrait 1.1 网址:https://www.liblibai.com/modelinfo/721fa2d298b262d7c08f0337ebfe58f8
介绍:AWPortrait1.1的创作过程其实是思考真实人像和AI生成影像视觉上的区别是什么的过程,希望AWPortrait能够在AI模拟人像摄影的真实度探索上再进一步;AI只是创作工具,只有每个人无可取代的想象力,才能开启属于我们独特的虚拟摄影之旅。
使用说明:
- 在t2i直出时,模拟影棚人像摄影的效果是最好的,如:Pure white background, Studio light, Studio
- 人像景别可选,如:Close-up , Upper body,全身full body 直出需要配合ADetailer插件控制脸部
- 可使用Prompts控制模特彩妆,如:Make up Portrait, pink eyeshadows, red lips等
- 表情可选,如: emotional face, smile, happy等
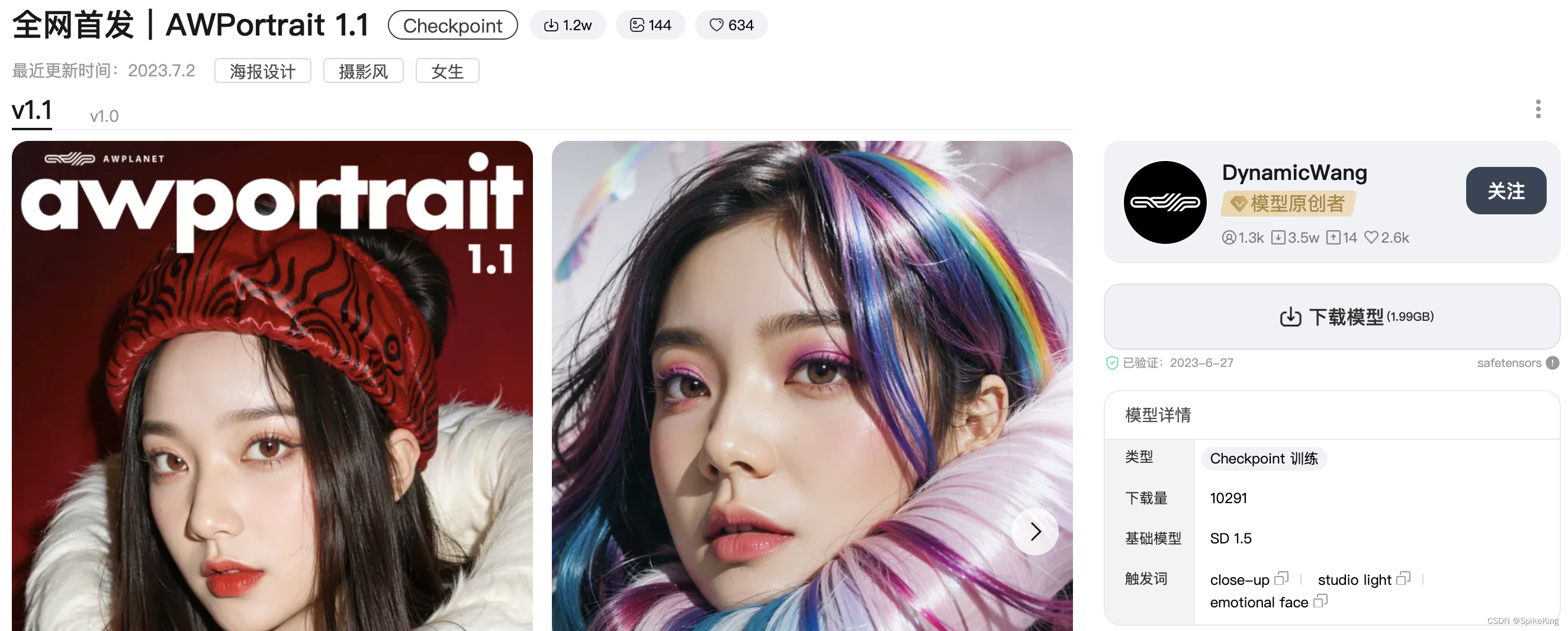
模型下载约 2G。
Prompts 参数配置:
masterpiece, best quality, 1girl, rainbow and purple swirling vortexes colourful cloudy and smoke and colorful background, (snowing) (( swirling vortexes colourful hair)), wear white fur coat, ((long Hair)), ((front)), emotional face, close up, studio light, studio, (((makeup portrait, pink eye shadow))), ((with many purple rainbow swirling vortexes colourful snow and feather on face))
Negative prompt: ng_deepnegative_v1_75t, (badhandv4:1.2), (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, ((monochrome)), ((grayscale)) watermark, moles, large breast, big breast, sunshine, bright,background blur,
Steps: 30, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 2629405120, Face restoration: CodeFormer, Size: 512x768, Model hash: 86aa256dd5, Model: AWPortrait_v1.1, Denoising strength: 0.3, Hires upscale: 2, Hires upscaler: 8x_NMKD-Superscale_150000_G, Version: v1.4.0
具体解释:
质量:masterpiece, best quality,
人物:1girl
背景:rainbow and purple swirling vortexes colourful cloudy and smoke and colorful background (彩虹和紫色旋转漩涡多彩多云和烟雾和彩色背景)
头发:(snowing) (( swirling vortexes colourful hair)) (下雪 旋转漩涡七彩头发)
穿搭:wear white fur coat (穿白色毛皮大衣)
镜头:((front)), emotional face, close up
场景:studio light, studio,
妆容:(((makeup portrait, pink eye shadow)))
特色:((with many purple rainbow swirling vortexes colourful snow and feather on face))
效果:




















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











