








一、为什么文档处理是RAG的胜负手?
在RAG(Retrieval-Augmented Generation)系统中,文档处理的质量直接决定了模型输出的上限。就像炼金术需要提纯原料,未经恰当处理的文档会导致:
- 检索结果偏离用户意图
- 生成内容出现事实性错误
- 响应速度指数级下降
二、文档处理的七重境界
第1层:文本标准化(Text Normalization)
- 消除编码差异( → UTF-8)
- 统一标点规范(中文全角→半角)
- 处理换行符和空格异常
- 处理特殊字符
- 统一大小写
第2层:语义分块(Semantic Chunking)
传统方法:
- 固定长度分块(512 tokens)
- 按段落分割
进阶方案:使用JBoltAI 框架实现语义分块
JBoltText.splitUrlBySemantic("文件URL")
.setStream(true).onSuccess((event, res) -> {
String chunck = res.getChuncks().get(0);
System.out.println("----- 语义块:" + chunck);
}).publish().await();
第3层:元数据增强(Metadata Enrichment)
{
"chunk_id": "doc123#chunk5",
"source": "2025JBoltAI发展规划.pdf",
"section": "第四章 SpringBoot版功能规划",
"timestamp": "2023-07-15T09:30:00Z",
"confidence_score": 0.92,
"tags":"JBoltAI,SpringBoot,可视化编排,DeepSeek深度思考支持"
}
关键元数据类型:
- 文档来源信息
- 时间敏感度标记
- 领域分类标签
部分信息可以通过AI进行提取
第4层:向量化(Embedding)
使用JBoltAI 框架 + Ollama + BGE Embedding大模型实现文本向量化:
JBoltEmbedding.embedding(EmbeddingModel.getCustomModel("ollama-bge-large","测试文本")
.onSuccess((event, result) -> {
System.out.println("向量化结果:" + result.get(0));
}).onFail((event, error) -> {
System.out.println(error.getMsg());
}).publish().await();
第5层:VDB索引优化(Index Optimization)
使用JBoltAI 框架 在Milvus VDB数据库中构建混合检索集合并指定索引
JBoltVDB.use().createCollection("test", Arrays.asList(
VDBField.ofNormal("tags", VDBFieldType.STRING),
VDBField.ofNormal("section", VDBFieldType.STRING),
VDBField.ofHnswVector()
,VDBField.ofDoc(true)
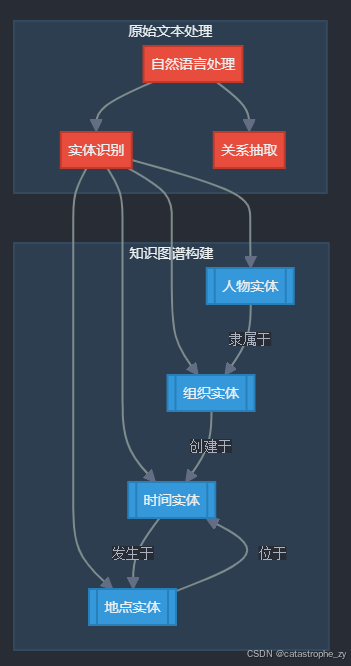
第6层:知识图谱融合(Knowledge Graph Integration)
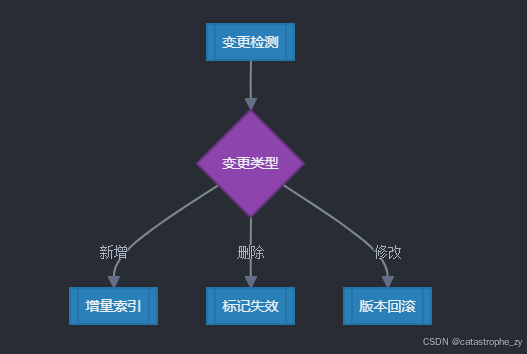
第7层:动态更新(Dynamic Refresh)
三、常见踩坑指南
- 分块失当:技术文档中代码片段被切割、或上下文语义割裂
- 时态混淆:将2020年的疫情数据用于当前问答
- 维度灾难:768维向量强行压缩到64维、或使用超大维度Embedding模型,导致vdb存储爆炸
- 冷启动困境:新文档未被充分索引就投入使用
四、处理效果评估金字塔
精准率
↗ ↖
召回率 响应速度
↗ ↖
覆盖度 可解释性
结语:文档处理的终极奥义
优秀的RAG文档处理就像制作寿司:
- 原料新鲜(数据质量)
- 刀工精准(分块策略)
- 调味恰当(元数据)
- 摆盘艺术(索引结构)
当你的文档处理流程能通过"三秒测试"——任意抽取一个文档片段,3秒内能说清它的上下文关系和业务价值,你的RAG系统就真正炼成了知识引擎。
欢迎大家使用JBoltAI 框架来搭建自己的RAG系统,JBoltAI 是Java 企业级 AI 数智化应用极速开发框架,旨在帮助Java系统快速接入大模型能力并开发具有AI能力的功能模块。提供包含多大模型适配接入(国内外)、RAG、思维链、Agent工具箱等数十项支撑能力。JBoltAI具备国内领先的用AI如何改造系统的AIGS解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











