







1 适用场景
1.1 HBase简介
HBase是一个开源的NoSQL分布式数据库,对稀疏表提供更高的存储空间使用率和读写效率。
采用存储计算分离架构:
- 存储层基于HDFS存储数据,提供容错机制和高可靠性;
- 计算层提供灵活快速的水平扩展、负载均衡和故障恢复能力。
提供强一致语义,在CAP理论中属于CP系统。
注:一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
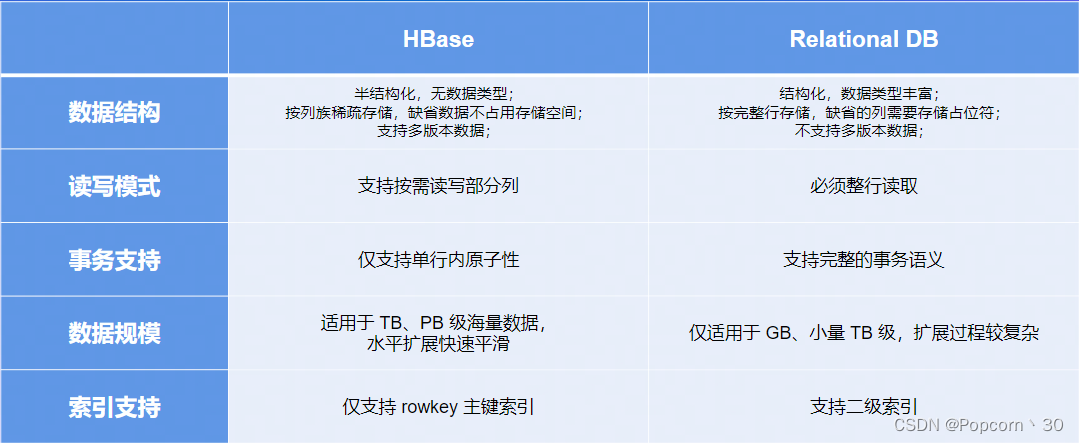
HBase与关系型数据库对比:
1.2 HBase数据模型
逻辑结构:
HBase以列族(column family)为单位存储数据,以行键(rowkey)索引数据。
个人感觉有点像DataFrame结构,它适合稀疏数据,缺省列不占用存储空间;通过(rowkey, column family, column qualifier, version)唯一指定一个具体的值;允许批量读取多行的部分列族/列数据。
- 列族需要在使用前预先创建,列名(column qualifier)不需要预先声明,因此支持半结构化数据模型。
- 支持保留多个版本的数据,(行键+列族+列名+版本号)定位一个具体的值。

物理结构:
物理数据结构最小单元是KeyValue结构:
- 每个版本的数据都携带全部行列信息。
- 同一行,同一列族的数据物理上连续有序存储。
- 同列族内的KeyValue按rowkey字典序升序,column qualifier升序,version降序排列。
- 不同列族的数据存储在相互独立的物理文件,列族间不保证数据全局有序。
- 同列族下不同物理文件间不保证数据全局有序。
- 仅单个物理文件内有序。

1.3 使用场景
- “近在线”的海量分布式KV/宽表存储,数据量级可达到PB级以上
- 写密集型、高吞吐应用,可接受一定程度的时延抖动
- 字典序主键索引、批量顺序扫描多行数据的场景
- Hadoop大数据生态友好兼容
- 半结构化数据模型,行列稀疏的数据分布,动态增减列名
- 敏捷平滑的水平扩展能力,快速响应数据体量、流量变化
典型应用:电商订单数据、搜索推荐引擎、广告数据流、用户交互数据、时序数据引擎、图存储引擎、大数据生态
HBase数据模型的优缺点:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









