







一、pytorch保存模型的方法
1.只保存参数
torch.save(model.state_dict(),path)
2.保存整个模型
torch.save(model,path)
二、对应的加载模型的方法
1.只保存参数
model.load_state_dict(torch.load(path))
该方法在加载的时候需要事先定义好跟原模型一致的模型,并在该模型的实例对象上进行加载
2.保存整个模型
model = torch.load(path)
三、使用torch.nn.DataParallel需要注意的问题
在调试https://github.com/yhenon/pytorch-retinanet,默认会使用torch.nn.DataParallel进行多GPU训练
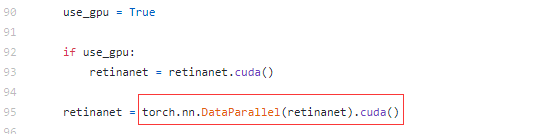
并且最开始还很奇怪为什么在保存模型时出现下面的形式,这里为什么会多出.module

于是,顺手改成了上文所述的torch.save(retinanet.state_dict(),……)的形式,结果在加载模型时就出现了下图的问题:


可以看出,加载模型的key值中都多了module.,这就需要前后对应好,才能正确加载模型。
如出现类似问题,解决也可参考:https://www.jianshu.com/p/e96a013ab5fd



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









