







🍊本文使用了3个经典案例进行MapReduce实战
🍊参考官方源码,代码风格较优雅
🍊解析详细
一、Introduction
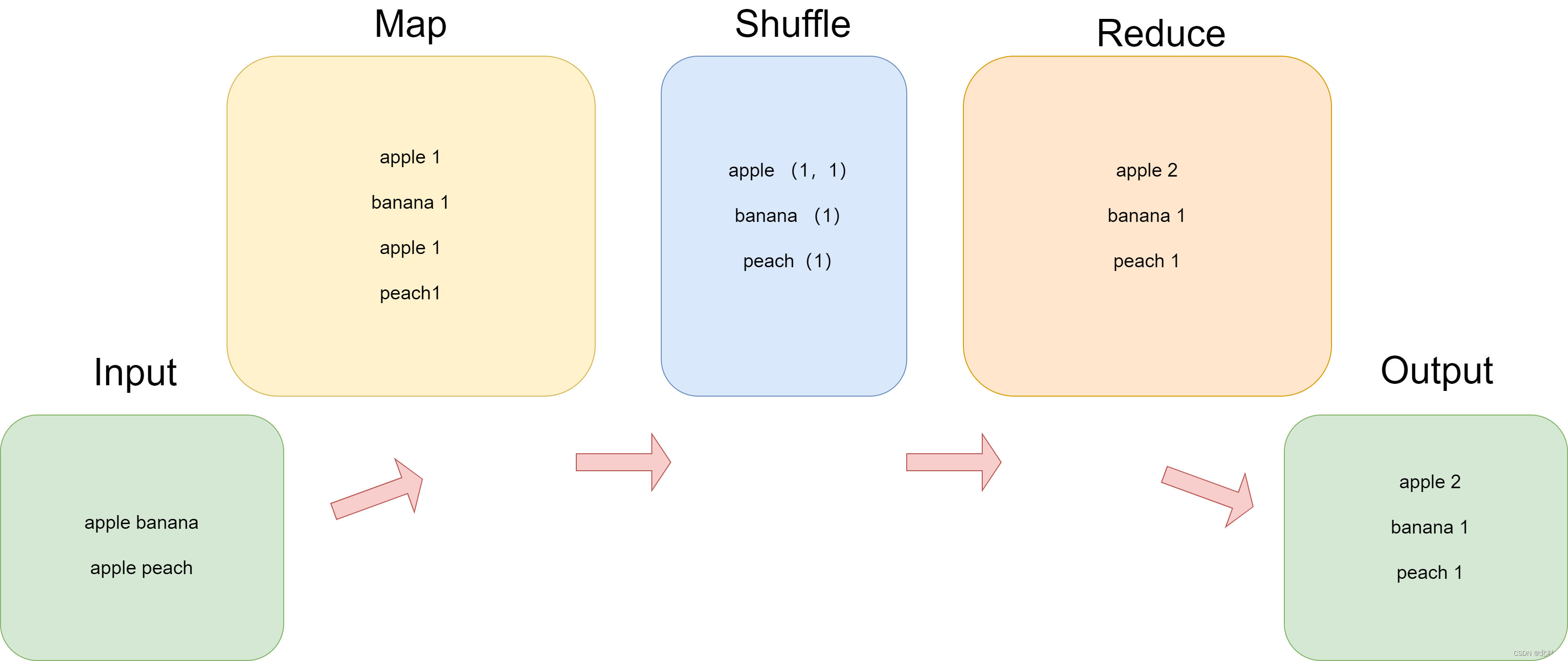
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户写的业务逻辑代码和自身默认代码整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上
其整体架构逻辑如下
| Map | 读取数据,进行简单数据整理 |
| Shuffle | 整合Map的数据 |
| Reduce | 计算处理Shuffle中的数据 |
二、WordCount
2.1 题目
统计文件中每个单词出现的个数。左侧为原始数据,右侧为输出数据。
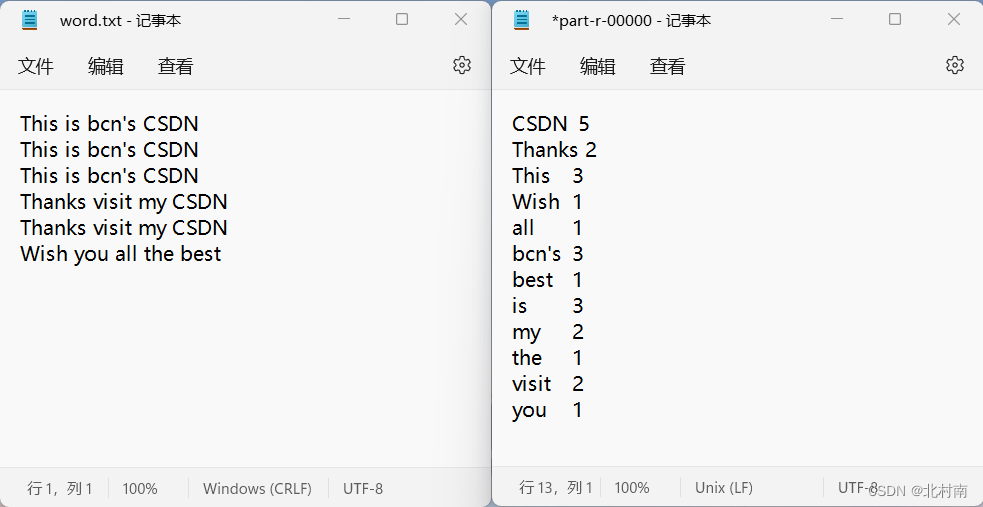
2.2 解析
WordCount统计单词个数是最基础的题目,我们除了要完成题目要求之外,代码尽量更加的优雅,因此我们主要参考的是Hadoop官方提供的WordCount案例
数据的走下如下
2.3 Mapper
Mapper中需要注意的是 Mapper<LongWritable, Text, Text, IntWritable>
<LongWritable,Text>为输入,<Text,IntWritable>为输出,或许很难理解为什么输出是<LongWritable,Text>,其实Text表示每一行的数据,LongWritable为每一行数据第一个数据在整个文件的偏移量,我们打印一下每次的Text和LongWritable

package com.bcn.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 输入数据为<单词偏移量,单词>
* 输出数据为<单词,出现次数>
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// Just craete one Text and IntWritable object to reduce waste of resources
Text outK = new Text();
IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Get one line
String line = value.toString();
System.out.println(line);
System.out.println(key);
// split the word by space
String[] words = line.split(" ");
// output
for (String word : words) {
outK.set(word);
context.write(outK, outV);
}
}
}
2.4 Reducer
我们关注的还是数据的走向 Reducer <Text, IntWritable,Text,IntWritable> ,<ext,IntWritable>为数据输入,与Mapper的输出是一致的
这里可能很多人为疑惑为什么输入的是<Text, IntWritable>,但是我们重写reduce时却使用了<Text key,Iterable<IntWritable> values>,这是因为中间省略掉了我们看不见的Shuffle阶段
package com.bcn.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer <Text, IntWritable,Text,IntWritable> {
int sum;
IntWritable outV=new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {
// Sum up
sum =0;
// The data for example apple,(1,1,1)
for (IntWritable count:values){
sum += count.get();
}
//Output
outV.set(sum);
context.write(key,outV);
}
}
2.4 Dreiver
最后我们设置启动类,也就是Main函数,在其中会配置7套件,这样就可以运行整个MapReduce程序了
package com.bcn.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.Get the config and job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.Connect Driver with jar
job.setJarByClass(WordCountDriver.class);
// 3.Connect with Mapper、Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4.Set the class of Mapper output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5.Set the class of final output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6.Set the input and output path
FileInputFormat.setInputPaths(job, new Path("E:\\Hadoop and Spark\\data\\word.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\Hadoop and Spark\\output\\wordCount"));
// 7.Submit the job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
三、Grade Sort
3.1 题目
对学生成绩表中总分进行排序(从高到低),若总分相同,则按数学成绩排序(从高到低)
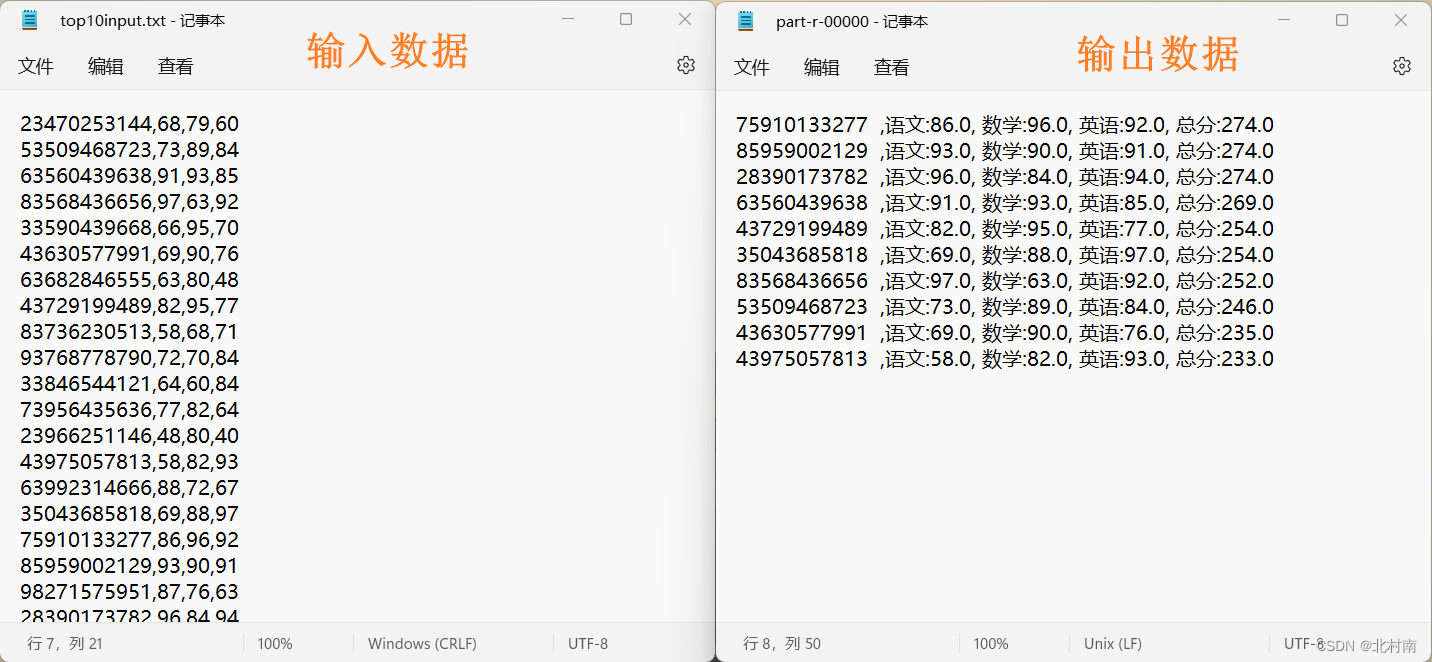
3.2 解析
该题与WordCount相比,特殊处为多了一个排序要求,对于排序问题,我们需要对该数据对象建立一个类对象,并重写readFields()、write()、toString、compareTo(),前三者为模板信息,而compareTo()是需要根据业务编写。
3.3 Entity
关于CompareTo方法,Java中默认是升序的,因此在其前加负号即可成为降序
package com.bcn.mapreduce.gradesort;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements WritableComparable<Student> {
private long id;
private double chinese;
private double math;
private double english;
private double total;
@Override
public void readFields(DataInput dataInput) throws IOException {
this.id=dataInput.readLong();
this.chinese=dataInput.readDouble();
this.math=dataInput.readDouble();
this.chinese=dataInput.readDouble();
this.english=dataInput.readDouble();
this.total=dataInput.readDouble();
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(this.id);
dataOutput.writeDouble(this.chinese);
dataOutput.writeDouble(this.math);
dataOutput.writeDouble(this.chinese);
dataOutput.writeDouble(this.english);
dataOutput.writeDouble(this.total);
}
@Override
public String toString() {
return this.id+" ,语文:"+this.chinese+", 数学:"+this.math+", 英语:"+this.english+", 总分:"+this.total;
}
@Override
public int compareTo(Student o) {
int r1=-Double.compare(this.total, o.total);
if(r1==0){
return -Double.compare(this.math, o.math);
}else {
return r1;
}
}
}
3.4 Mapper
注意Mapper的输出是<Student,Text>,由于放入Reducer中,只需要Student这一个信息即可,因此这里的Text只是随意加上去的
package com.bcn.mapreduce.gradesort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class GradeSortMapper extends Mapper<LongWritable, Text,Student,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Get data
String[] data=value.toString().split(",");
long id= Long.parseLong(data[0]);
double chinese= Double.parseDouble(data[1]);
double math=Double.parseDouble(data[2]);
double english=Double.parseDouble(data[3]);
double total =chinese+math+english;
Student s=new Student(id,chinese,math,english,total);
context.write(s,value);
}
}
3.5 Reducer
package com.bcn.mapreduce.gradesort;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class GradeSortReducer extends Reducer<Student, Text, Text, NullWritable> {
public static int count=0;
public Text text=new Text();
@Override
protected void reduce(Student s, Iterable<Text> values,Context context) throws IOException, InterruptedException {
for(Text t:values){
if (GradeSortReducer.count<10){
count++;
text.set(s.toString());
context.write(text,NullWritable.get());
}
}
}
}
3.6 Driver
package com.bcn.mapreduce.gradesort;
import com.bcn.mapreduce.wordcount.WordCountDriver;
import com.bcn.mapreduce.wordcount.WordCountMapper;
import com.bcn.mapreduce.wordcount.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class GradeSortDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.Get the config and job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.Connect Driver with jar
job.setJarByClass(GradeSortDriver.class);
// 3.Connect with Mapper、Reducer
job.setMapperClass(GradeSortMapper.class);
job.setReducerClass(GradeSortReducer.class);
// 4.Set the class of Mapper output
job.setMapOutputKeyClass(Student.class);
job.setMapOutputValueClass(Text.class);
// 5.Set the class of final output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 6.Set the input and output path
FileInputFormat.setInputPaths(job, new Path("E:\\Hadoop and Spark\\data\\top10input.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\Hadoop and Spark\\output\\top10input"));
// 7.Submit the job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
四、Document Revere
4.1 题目
有大量的文本(文档、网页),需要建立搜索索引。输入数据为三个文档
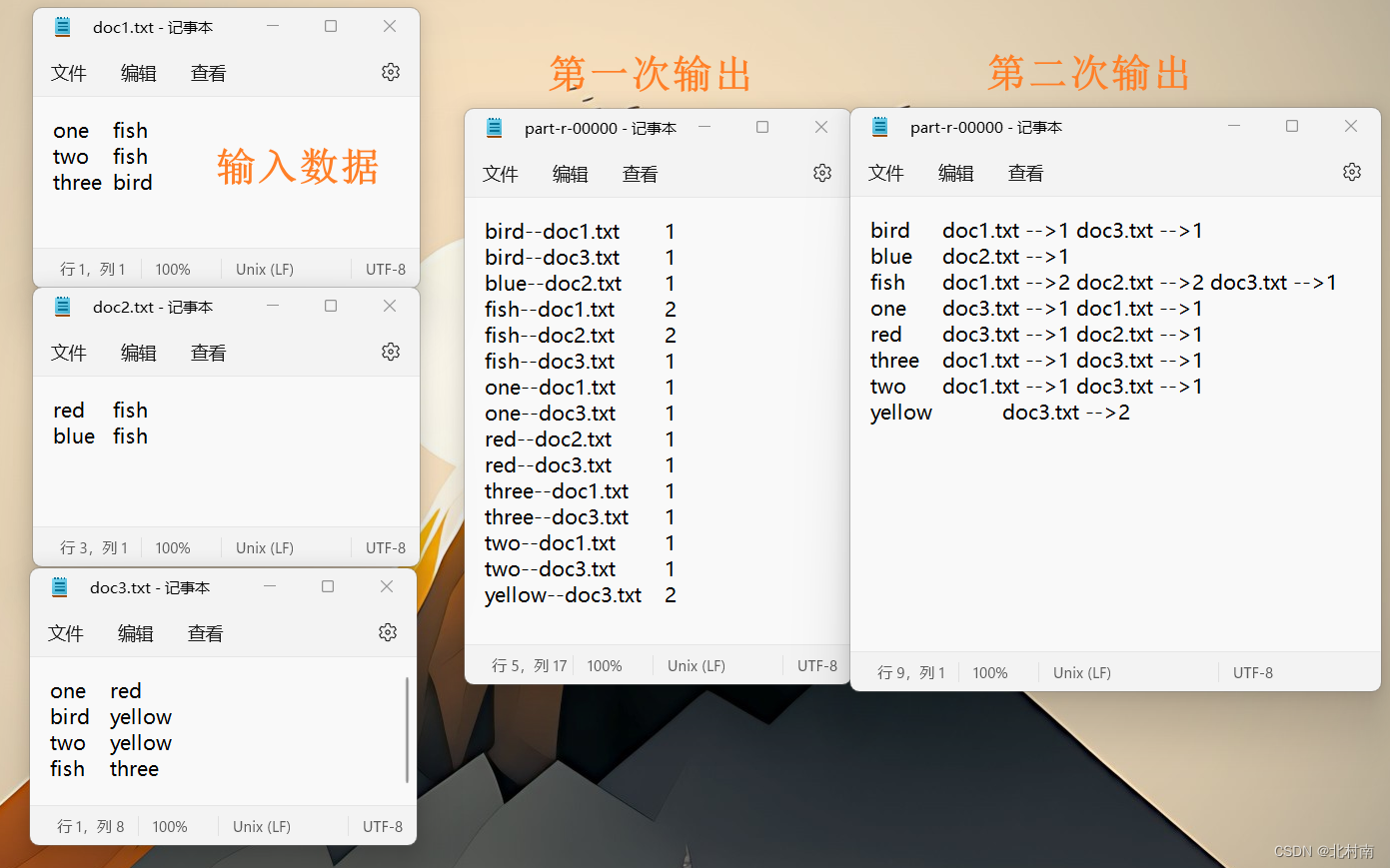
4.2 解析
与WordCount不同点在于除了要统计每个单词的个数之外,还需要记录每个单词所在的文档。而一个MapReduce可以有多个Map阶段和一个Reduce阶段,遇到这样复杂的业务可以使用两个MapReduce程序串行(使用Partitioner合并成一个也可以,这里使用两个串行比较简单暴力):第一阶段统计单词个数,第二阶段计算每个单词出现在哪个文档中
4.3 Mapper
Mapper1
package com.bcn.mapreduce.document;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
import java.util.StringTokenizer;
public class Document1Mapper extends Mapper<Object, Text, Text, Text> {
private FileSplit filesplit;
private Text word = new Text();
private Text temp = new Text("1");
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
filesplit = (FileSplit) context.getInputSplit();
String fileName = filesplit.getPath().getName();
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken() + "--" + fileName);
context.write(word, temp);
}
}
}
Mapper2
package com.bcn.mapreduce.document;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
import java.util.StringTokenizer;
public class Document2Mapper extends Mapper<LongWritable, Text, Text, Text> {
private Text Word = new Text();
private Text Filename = new Text();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] all = line.split(" ");
String[] wandc = all[0].split("--");
String word = wandc[0];
String document = wandc[1];
String num = all[1];
Word.set(word);
Filename.set(document + " -->" + num + " ");
context.write(Word, Filename);
}
}
4.4 Reducer
Reducer1
package com.bcn.mapreduce.document;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class Document1Reducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Iterator<Text> it = values.iterator();
String s = "";
StringBuilder wordNum = new StringBuilder();
if (it.hasNext()) {
wordNum.append(it.next().toString());
}
for (; it.hasNext(); ) {
wordNum.append(it.next().toString());
}
s = s + wordNum.length();
context.write(key, new Text(s.toString()));
}
}
Reducer2
package com.bcn.mapreduce.document;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class Document2Reducer extends Reducer<Text, Text, Text, Text> {
public Text text=new Text();
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder filename= new StringBuilder(" ");
for(Text t :values){
filename.append(t);
}
text.set(filename.toString());
context.write(key,text);
}
}
4.5 Driver
Driver1
package com.bcn.mapreduce.document;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Document1Driver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.Get the config and job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.Connect Driver with jar
job.setJarByClass(Document1Driver.class);
// 3.Connect with Mapper、Reducer
job.setMapperClass(Document1Mapper.class);
job.setReducerClass(Document1Reducer.class);
// 4.Set the class of Mapper output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5.Set the class of final output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 6.Set the input and output path
FileInputFormat.setInputPaths(job, new Path("E:\\Hadoop and Spark\\data\\doc"));
FileOutputFormat.setOutputPath(job, new Path("E:\\Hadoop and Spark\\output\\doc"));
// 7.Submit the job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
Driver2
package com.bcn.mapreduce.document;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Document2Driver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1.Get the config and job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2.Connect Driver with jar
job.setJarByClass(Document2Driver.class);
// 3.Connect with Mapper、Reducer
job.setMapperClass(Document2Mapper.class);
job.setReducerClass(Document2Reducer.class);
// 4.Set the class of Mapper output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 5.Set the class of final output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 6.Set the input and output path
FileInputFormat.setInputPaths(job, new Path("E:\\Hadoop and Spark\\data\\period1.txt"));
FileOutputFormat.setOutputPath(job, new Path("E:\\Hadoop and Spark\\output\\doc_result"));
// 7.Submit the job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











