







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
能ping成功三个主机名,说明映射配置成功
提示:为了避免手写错误,master的hosts映射配置好后,可以通过scp命令,将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。

2.4设置免密登录
想要在机器1上,远程控制机器2,常用的方案就是在机器1安装ssh客户端,机器2安装ssh服务端,ssh客户端和ssh服务端之间的通信协议是ssh协议。在linux系统中ssh命令,就是一个ssh客户端程序,sshd服务,就是一个ssh服务端程序。在windows中,给大家提供的mobaxterm是一个图形化界面的ssh客户端。因为master、slave1、slave2三个节点都是从之前的已经安装好Hadoop伪分布式的虚拟机复制而来,而当时已经设置了免密登录,故不需再设置了,也就是master可以免密登录到master、slave1、slave2。
2.5关闭防火墙
防火墙实质是一个程序,它可以控制系统进来或者出去的流量,Centos7默认情况下,防火墙是开机自起的,在集群部署模式下,各个节点之间的进程要通信,为了方便,一般都要关闭防火墙。同理,之前已经设置不允许防火墙开机自启,默认开机是关闭的,故也不需要操作。
2.6删除Hadoop伪分布式数据
因为master、slave1、slave2三个节点都是从之前的已经安装好Hadoop伪分布式的虚拟机复制而来,为了保证整个进程环境干净,我们需要删除这三个节点/usr/local/hadoop-2.7.1/data路径。
2.7修改hadoop配置文件
vi core-site.xml,该配置文件内容如下:
<configuration>
<!-- hdfs分布式文件系统名字/地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--存放namenode、datanode数据的根路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.1/data</value>
</property>
</configuration>
vi hdfs-site.xml,该配置文件内容如下:
<configuration>
<!-- 数据块副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondary namenode 按照规划部署到slave1上 -->
<property>
<name>dfs.secondary.http.address</name>
<value>slave1:50090</value>
</property>
</configuration>
vi yarn-site.xml,该配置文件内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
vi mapred-site.xml,该配置文件内容如下:
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
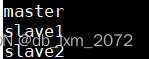
slaves文件里面记录的是集群主机名。一般有以下两种作用:
一是:配合一键启动脚本,如start-dfs.sh、stop-yarn.sh用来进行集群启动,这时候slaves文件里面的主机标记的就是从节点角色所在的机器。
二是:可以配合hdfs-site.xml里面dfs.hosts属性形成一种白名单机制。
dfs.hosts指定一个文件,其中包含允许连接到NameNode的主机列表,必须指定文件的完整路径名,那么所有在slaves中的主机才可以加入的集群中。如果值为空,则允许所有主机。
vi slaves,该配置文件内容如下:
2.8将master主机上的hadoop配置文件,同步到其他两个主机上
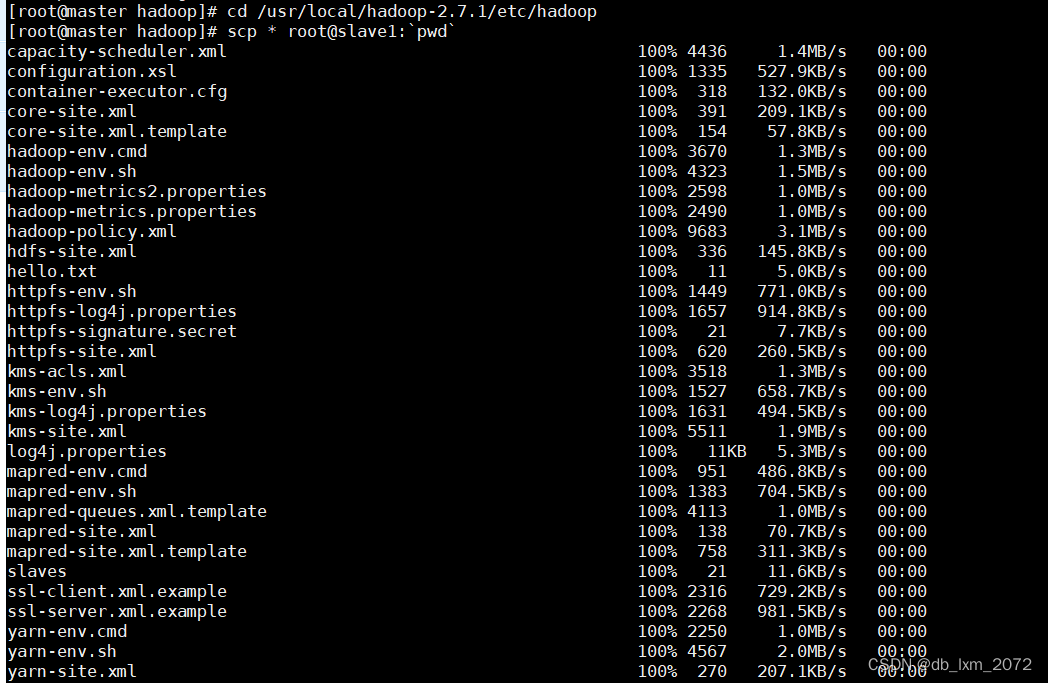
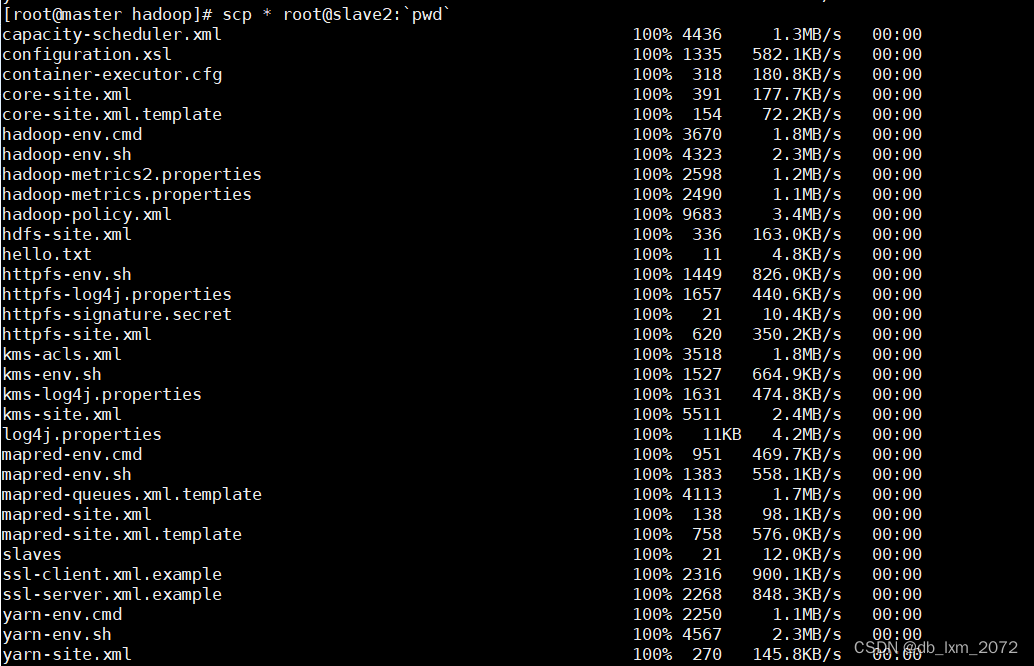
scp第一个参数*表示当前路径下的所有文件,第二个参数冒号左边表示目标主机,冒号右边表示目标主机的路径。pwd打印出当前路径
整句命令的作用是将当前路径下的所有文件,以root身份,同步到slave1、slave2的pwd输出的路径下
2.9时间同步
hadoop集群各个节点之间的时间应该一致,也就是master当前时间如果是2023-01-01 01:01:01,那么slave1和slave2上也应该是这个时间,如果各个节点之间时间不一致/不同步,那么集群就会出现一些错误。ntp(Network Time Protocol,网络时间协议)是一种跟时间设置相关的协议。客户端-服务端架构,ntp.api.bz是一个公开的ntp服务器,执行ntpdate ntp.api.bz命令,可以从这个ntp服务器拉取时间并更新当前机器的时间。在master、slave1、slave2上分别执行该命令,即可完成时间同步,此时三个节点的时间应该是一致的。

2.10NameNode格式化
格式化只需格式化一次,以后启动Hadoop集群时,不需要再格式化。
在master上执行格式化命令:hdfs namenode -format
2.11hadoop集群的启动和停止
启动:start-all.sh
停止:stop-all.sh
master启动了四个进程,与规划表对应

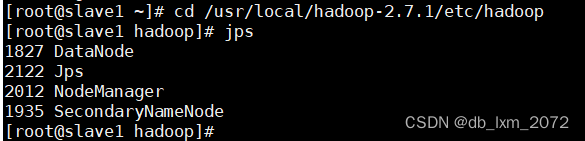
slave1启动了三个进程,与规划表对应
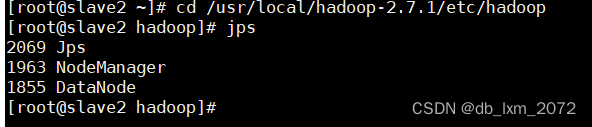
slave2启动了三个进程,与规划表对应
2.12查看hdfs的web管理页面
浏览器访问master的50070端口:http://192.168.1241.100:50070
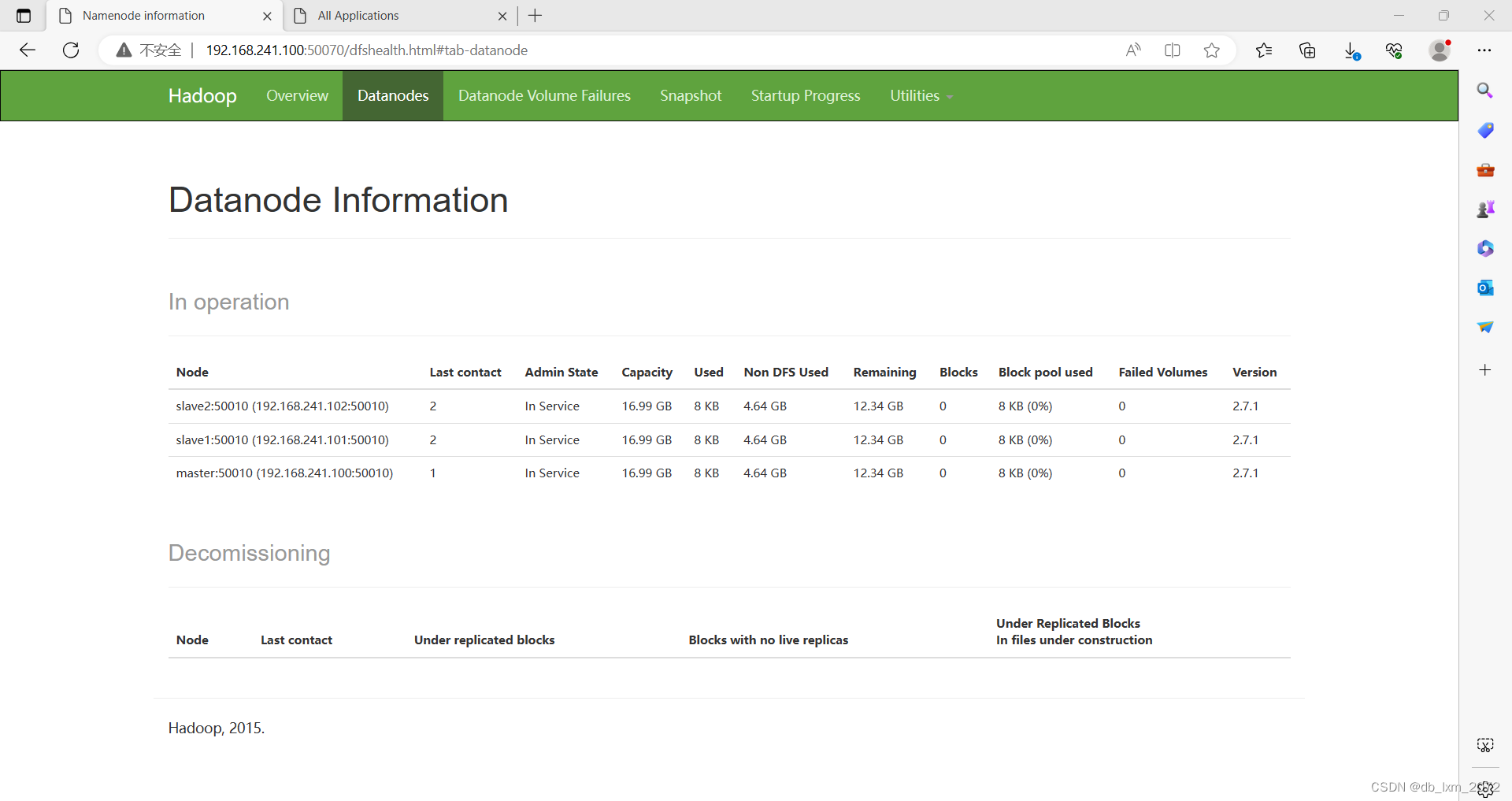
可以看到hdfs有三个datanode节点,没有节点可用的磁盘空间是 16.99GB
2.13查看yarn的web管理页面
验证是否部署成功
192.168.241.100:8088/cluster/nodes
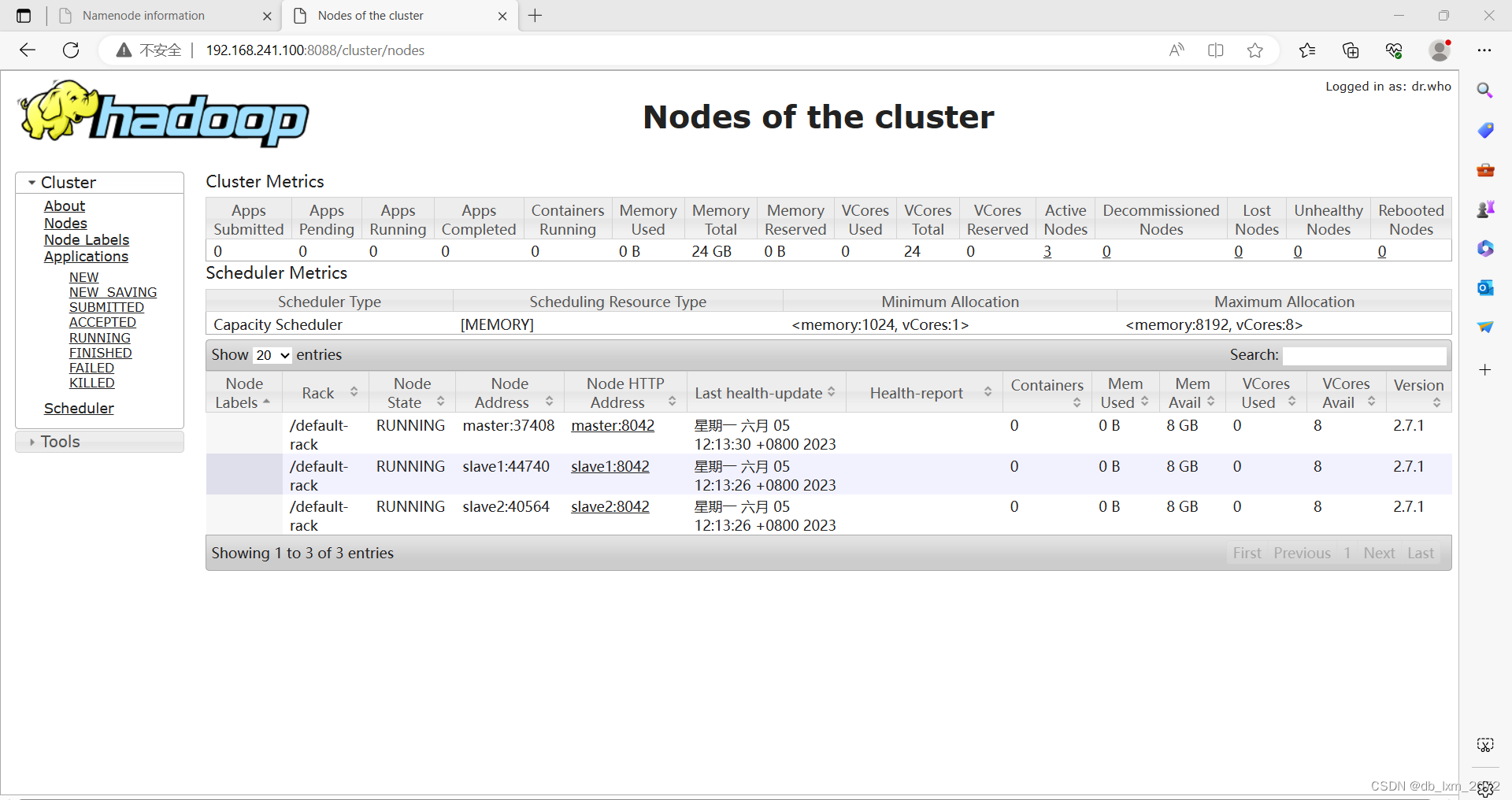
IP改为本人真实IP,访问该地址,看到该页面,YARN组件部署成功
hadoop部署总结:
互联网的快速发展带来了数据快速增加,海量数据的存储已经不是一台机器所能处理的问题了。Hadoop的技术应运而生,对于伪分布式存储,Hadoop有自己的一套系统Hadoop distribution file system来处理,为什么分布式存储需要一个额外的系统来处理,而不是就把1TB以上的文件分开存放就好了呢,如果不采用新的系统,我们存放的东西没办法进行一个统一的管理。存放在A电脑的东西只能在连接到A去找,存在B的又得单独去B找,繁琐目不便干管理,而这个分布式存储文件系统能把这些文件分开存储的过程透明化,用户看不到文件是怎么存储在不同电脑上,看到的只是一个统一的管理界面。现在的云盘就是很好的给用户这种体验。对于分布式计算,在对海量数据进行处理的时候,一台机器肯定也是不够用的,所以也需要考虑将将数据分在不同的机器上并行的进行计算,这样不仅可以节省大量的硬件的1/0开销,也能够将加快计算的速度。
三、HBase部署
3.1配置文件
打开hbase根目录的cof目录下的hbase-site.xml文件,并添加两个配置项,将hbase数据存放在hdfs
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://20210322072-master:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase-1.4.8/zk_data</value>
</property>
</configuration>
启动hadoop和hbase
hbase 启动命令: start-hbase.sh

执行jps,确认hbase是否部署成功

执行hbase shell命令,连接到hbase

3.2创建表
第一个参数是表名,要用单引号括起来;第二个参数及之后的参数,指定列族,并修改版本数的数量为2,即只保留两个版本的数据

查看表
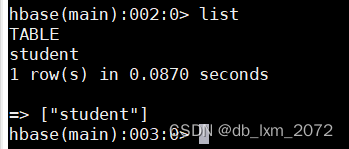
3.3表信息查询
用desc命令查看表结构,desc的输出中,一个大括号对应一个列族,每个字段对应列族的一个属性
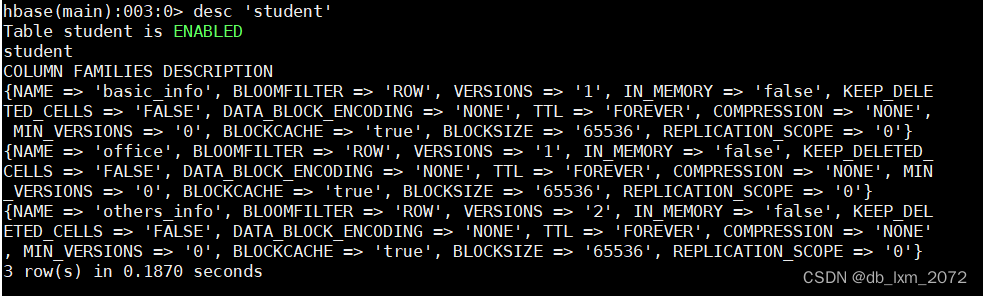
3.4表结构修改
用alter命令添加新的列族

查看是否添加成功
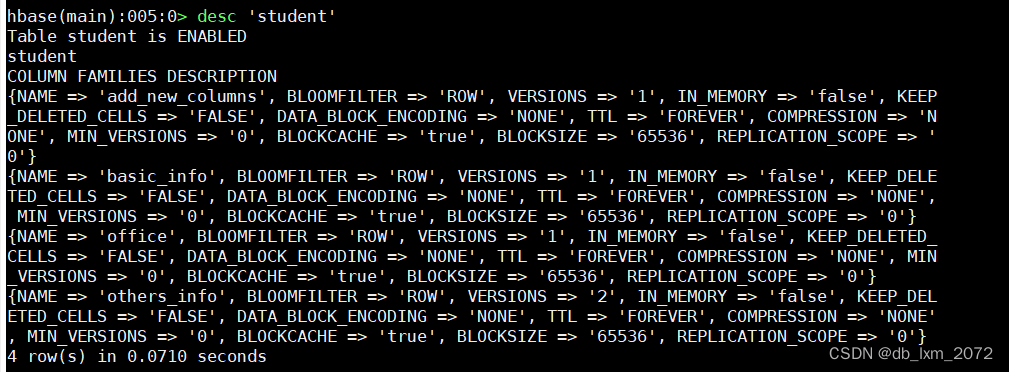
将add_new_columns列族的版本数改为3

删除add_new_columns列族

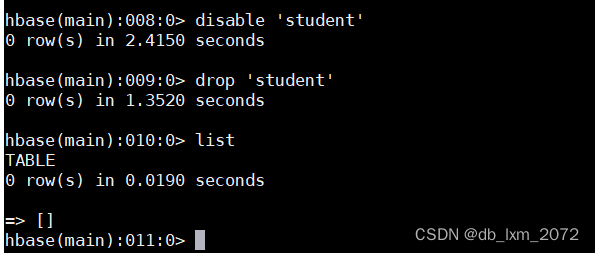
3.5 删除表
先disable,再使用drop命令删除表并查看
3.6 数据插入
用put插入一条记录,get命令可以查看指定表的某个row key的所有列的单元格最新版本的值

3.7数据更新

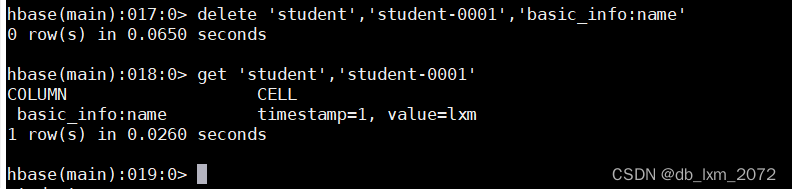
3.8数据删除
删除某个cell最新的数据,用delete删除指定表的指定cell的最新的值,但版本1的数据还在
再delete一次,版本1的数据也没了
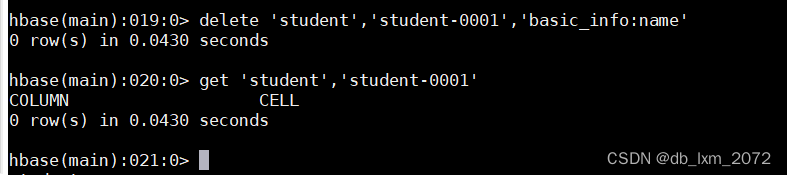
删除指定row key的某个列族的数据
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2BnOCor-1713457421684)]
给大家整理的电子书资料:
[外链图片转存中…(img-Im9sO9SR-1713457421684)]
如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-A5eZ86nn-1713457421684)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









