







四台机分别为node1:192.168.23.111;node2:192.168.23.112;node3:192.168.23.113;node4:192.168.23.114
Hadoop的安装与配置
配置好网络、yum源及关闭防火墙和做好主机映射,并ssh免密互通
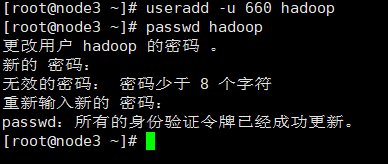
1、创建hadoop用户。
分别在四台节点机上创建用户hadoop,uid=660,密码都设置为123456
2、设置Master节点机ssh无密码登录Slave节点机
详细参考同专栏里的《密码学基础及ssh实现多节点间无密码访问》



3、使用WinSCP上传hadoop-2.7.2.tar.gz软件包到node1节点机的root目录下。
如果hadoop软件包在node1节点机上编译,则把编译好的包拷贝到root目录下即可。

4、解压文件,安装文件。
[root@node1 ~]# tar xvzf hadoop-2.7.2.tar.gz
[root@node1 ~]# cd hadoop-2.7.2/
[root@node1 hadoop-2.7.2]# mv * /home/hadoop
5、修改hadoop配置文件(共6个)
Hadoop配置文件主要有:hadoop-env.sh、yarn-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。配置文件在/home/hadoop/etc/hadoop/目录下,进入该目录进行配置。
[root@node1 hadoop-2.7.2]# cd /home/hadoop/etc/hadoop/
1)修改hadoop-env.sh,将文件中的export JAVA_HOME=${JAVA_HOME}
修改为export JAVA_HOME=/usr/lib/jvm/java-1.8.0 。(可以利用java - version查看版本,若没有安装要先安装)
yum -y install java-1.8.0-openjdk*
#node1、node2、node3、node4都需要安装


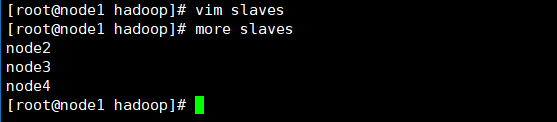
2)修改slaves,该文件登记DataNode节点主机名,本处添加node2,node3,node4三台节点主机名。
3)修改core-site.xml,将文件中的 <configuration></configuration>修改为如下内容。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value> #其中node1为集群的NameNode(Master)节点机,node1可以使用IP地址表示。
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
4)修改hdfs-site.xml,将文件中的<configuration></configuration>修改为如下内容。
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
第二个NameNode也使用node1节点机,NameNode产生的数据存放在/home/hadoop/dfs/name目录下,DataNode产生的数据存在/home/hadoop/dfs/data目录下,设置备份数量3份。
5)将文件mapred-site.xml.template改名为mapred-site.xml。
[root@node1 hadoop]# mv mapred-site.xml.template mapred-site.xml
将文件中的<configuration></configuration>修改为如下内容。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
6)修改yarn-site.xml,将文件中的<configuration></configuration>修改为如下内容。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.23.111</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
</configuration>
6、修改“/home/hadoop/”文件用户主/组属性。
[root@node1 hadoop]# chown -R hadoop:hadoop /home/hadoop
7、将配置好的hadoop系统复制到其他节点机上。
[root@node1 hadoop]# scp -r * hadoop@node4:/home/hadoop
[root@node1 hadoop]# scp -r * hadoop@node3:/home/hadoop
[root@node1 hadoop]# scp -r * hadoop@node2:/home/hadoop
8、分别root用户登录node2,node3,node4节点机,修改 “/home/hadoop/”文件用户主/组属性。
chown -R hadoop:hadoop /home/hadoop #node2、node3、node4执行命令
Hadoop的管理
Hadoop系统搭建完成后,需要对NameNode节点进行格式化,启动相关服务,检查运行状态。
1、格式化NameNode。
登录node1节点机,以用户hadoop登录或su – hadoop登录,格式化NameNode。
[hadoop@node1 ~]$ hadoop namenode -format
#不要多次格式化,如果出现bug,请按照配置文件路径删除缓存

最后显示有“successfully formatted.”表示格式化成功。
2、启动、停止hadoop服务。
进入/home/hadoop/sbin/,可以看到目录的脚本程序。

1)运行start-dfs.sh脚本程序。
2)运行yarn脚本程序。

3)分别检查每台节点机运行情况。
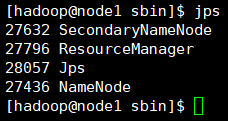
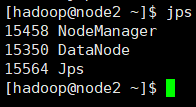
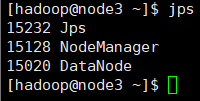
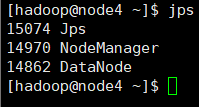
4)停止hadoop服务,停止服务后,后面操作无法进行,这步暂时不操作
stop-yarn.sh
stop-dfs.sh
5)可以使用all来启动关闭所有节点
[hadoop@node1 ~]$ vim .bash_profile

[hadoop@node1 ~]$ source .bash_profile

3、查看集群状态。
[hadoop@node1 ~]$ hdfs dfsadmin -report #执行此条命令,显示内容如下,注意Live datanodes(3) 如果没有3则集成失败的
Configured Capacity: 54716792832 (50.96 GB)
Present Capacity: 48293249024 (44.98 GB)
DFS Remaining: 48293236736 (44.98 GB)
DFS Used: 12288 (12 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Live datanodes (3):
Name: 192.168.23.112:50010 (node2) Hostname: node2 Decommission Status
- Normal Configured Capacity: 18238930944 (16.99 GB) DFS Used: 4096 (4
Name: 192.168.23.113:50010 (node3) Hostname: node3 Decommission Status
KB) Non DFS Used: 2141077504 (1.99 GB) DFS Remaining: 16097849344
(14.99 GB) DFS Used%: 0.00% DFS Remaining%: 88.26% Configured Cache
Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache
Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu
Jul 29 18:09:15 CST 2021- Normal Configured Capacity: 18238930944 (16.99 GB) DFS Used: 4096 (4
Name: 192.168.23.114:50010 (node4) Hostname: node4 Decommission Status
KB) Non DFS Used: 2141249536 (1.99 GB) DFS Remaining: 16097677312
(14.99 GB) DFS Used%: 0.00% DFS Remaining%: 88.26% Configured Cache
Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache
Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu
Jul 29 18:09:15 CST 2021- Normal Configured Capacity: 18238930944 (16.99 GB) DFS Used: 4096 (4
KB) Non DFS Used: 2141216768 (1.99 GB) DFS Remaining: 16097710080
(14.99 GB) DFS Used%: 0.00% DFS Remaining%: 88.26% Configured Cache
Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache
Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu
Jul 29 18:09:18 CST 2021
4、查看文件块组成。

5、使用浏览器浏览Master节点机 http://192.168.23.111:50070,查看NameNode节点状态。
注意:这个网址ip必须是你主节点的ip

6、浏览Datanodes数据节点。

7、使用浏览器浏览Master节点机 http://192.168.23.111:8088查看所有应用。

8、浏览Nodes。

Hadoop Shell命令
为方便对hdfs文件系统和作业提交的操作,hadoop提供了一些基本的shell操作,这些基本操作与linux下的操作有很多相似性。shell操作的基本命令格式为:hdfs dfs -cmd 其中,-cmd为为具体的操作命令如-cp(复制命令)。
1、在hdfs创建gdu目录
[hadoop@node1 ~]$ hdfs dfs -mkdir /gdu
2、在hdfs查看当前目录。

3、在本地系统编辑文件jie.txt。
[hadoop@node1 ~]$ vim jie.txt

[hadoop@node1 ~]$ hdfs dfs -put jie.txt /gdu
4、从hdfs中下载文件。
[hadoop@node1 ~]$ hdfs dfs -get /gdu/jie.txt
5、查看hdfs中/swvtc/jie.txt的内容。

6、Hadoop常用的一些命令
命令介绍如下:
> hdfs dfs -ls <path> #查看指定目录下文件
hdfs dfs -cat <path-file> #查看文件内容
hdfs dfs -put <local-file/path> <hdoop-path> #将本地文件或目录存储至hadoop
hdfs dfs -get <hadoop-path> <local> #将hadoop文件下载至本地
hdfs dfs -rm <hadoop-file> #删除hadoop文件
hdfs dfs -rmr <hadoop-path> #删除hadoop上指定文件夹(包含子目录等)
hdfs dfs -mkdir <hadoop-path> #在hadoop创建新目录
hdfs dfs -touchz <hadoop-path-file> #在hadoop新建一个空文件
hdfs dfs -mv <old-path-file> <new-path-file> #将hadoop文件重命名
hdfs dfs -getmerge <hadoop-path> <local-path-file> #将hadoop指定目录下所有内容
#保存为一个文件,同时下载至本地
hadoop job -kill <job-id> #将正在运行的hadoop作业杀掉
hadoop jar <jar> <mainClass] args... #运行jar文件
hadoop distcp <srcurl> <desturl> #递归地拷贝文件或目录
7、Hadoop其他一些命令
命令介绍如下:
1)运行HDFS文件系统检查工具(fsck tools)
用法:
hadoop fsck [GENERIC_OPTIONS] <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
选项:
<path> 检查的起始目录。
-move 移动受损文件到/lost+found
-delete 删除受损文件。
-openforwrite 打印写打开的文件。
-files 打印正被检查的文件。
-blocks 打印块信息。
-locations 打印出每个块的位置信息。
-racks 打印出data-node的网络拓扑结构。
2)用于和Map Reduce作业交互的命令(jar)
用法:
hadoop job [GENERIC_OPTIONS] [-submit <job-file>] | [-status <job-id>] | [-counter <job-id><group-name><counter-name>] | [-kill <job-id>] | [-events <job-id><from-event-#><#-of-events>] | [-history [all] <jobOutputDir>] | [-list [all]] | [-kill-task <task-id>] | [-fail-task <task-id>]
选项:
-submit <job-file> 提交作业
-status <job-id> 打印map和reduce完成百分比和所有计数器。
-counter <job-id><group-name><counter-name> 打印计数器的值。
-kill <job-id> 杀死指定作业。
-events <job-id><from-event-#><#-of-events> 打印给定范围内jobtracker
接收到的事件细节。
-history [all] <jobOutputDir> -history <jobOutputDir> 打印作业的细节、失败
及被杀死原因的细节。更多的关于一个作业的细节比如成功的
任务,做过的任务尝试等信息可以通过指定[all]选项查看。
-list [all] -list all 显示所有作业。-list只显示将要完成的作业。
-kill-task <task-id> 杀死任务。被杀死的任务不会不利于失败尝试。
-fail-task <task-id> 使任务失败。被失败的任务会对失败尝试不利。
3)运行pipes作业
用法:
hadoop pipes [-conf<path>] [-jobconf<key=value>, <key=value>, ...] [-input <path>] [-output <path>] [-jar <jar file>] [-inputformat<class>] [-map <class>] [-partitioner<class>] [-reduce <class>] [-writer <class>] [-program <executable>] [-reduces <num>]
选项:
-conf<path> 作业的配置
-jobconf<key=value>, <key=value>, ... 增加/覆盖作业的配置项
-input <path> 输入目录
-output <path> 输出目录
-jar <jar file> Jar文件名
-inputformat<class> InputFormat类
-map <class> Java Map类
-partitioner<class> Java Partitioner
-reduce <class> Java Reduce类
-writer <class> Java RecordWriter
-program <executable> 可执行程序的URI
-reduces <num> reduce个数
4)运行一个HDFS的dfsadmin客户端
用法:
hadoop dfsadmin [GENERIC_OPTIONS] [-report] [-safemode enter | leave | get | wait] [-refreshNodes] [-finalizeUpgrade] [-upgradeProgress status | details | force] [-metasave filename] [-setQuota<quota><dirname>...<dirname>] [-clrQuota<dirname>...<dirname>] [-help [cmd]]
选项:
-report 报告文件系统的基本信息和统计信息。
-safemode enter | leave | get | wait 安全模式维护命令。
-refreshNodes 重新读取hosts和exclude文件,更新允许连到Namenode的
或那些需要退出或入编的Datanode的集合。
-finalizeUpgrade 终结HDFS的升级操作。
-upgradeProgress status | details | force 请求当前系统的升级状态,
状态的细节,或者强制升级操作进行。
-metasave filename 保存Namenode的主要数据结构到hadoop.log.dir属性指定
的目录下的<filename>文件。
-setQuota<quota><dirname>...<dirname> 为每个目录 <dirname>设定配额<quota>。
目录配额是一个长整型整数,强制限定了目录树下的名字个数。
-clrQuota<dirname>...<dirname> 为每一个目录<dirname>清除配额设定。
-help [cmd] 显示给定命令的帮助信息。
5)运行namenode。
用法:
hadoop namenode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint]
选项:
-format 格式化namenode。
-upgrade 分发新版本的hadoop后,namenode应以upgrade选项启动。
-rollback 将namenode回滚到前一版本。
-finalize finalize 会删除文件系统的前一状态。
-importCheckpoint 从检查点目录装载镜像并保存到当前检查点目录,
检查点目录由fs.checkpoint.dir指定。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











