






相关UML:
网络引擎整体结构:
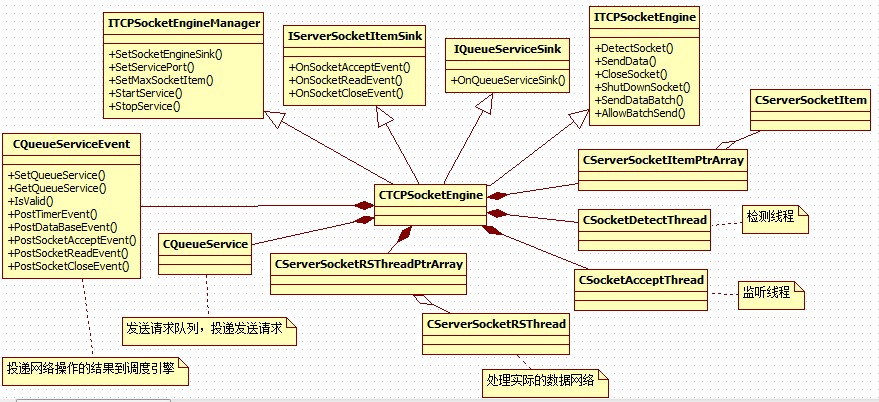
SocketItem细节:
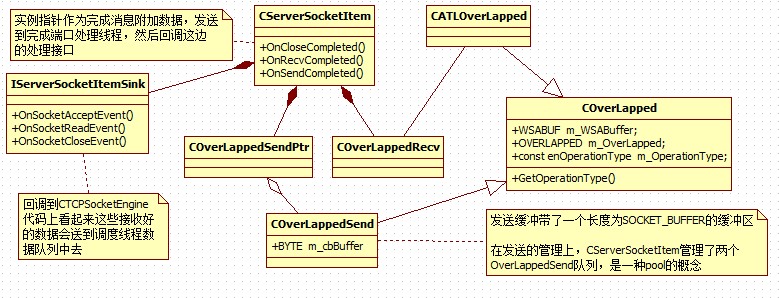
先来看几个底层结构:
先复习下基础,Windows下的网络模型有很多种,这里只拿出三种来说:
EventSelect:基于信号机制,以socket为单位绑定信号量,当socket上有指定的事件发生时激发信号,然后查询事件处理事件重设事件,继续在信号量上等待。其实也是在伯克利select模型上的换不换药的加强。
OverLapped:分两种工作模式完成回调,和完成事件。重叠IO监视每次操作,每次IO都绑定一个重叠对象,当操作完成以后激发信号或者调用回调。
IOCP:和overlapped类似,不过结果经过了Windows的预处理以队列的形式挂在完成端口上
根据上面的复习,可以得出一个结论,IOCP环境中每一次IO操作都需要一个重叠结构,那么一个CServerSocketItem至少需要如些这些东东:
他要接受数据,所以必须有一个接受数据的 OverLapped
它要发送数据,说以必须有一个发送数据的 OverLapped
netFox对OverLapped做了使用了类似池的的管理手段,他的Send都是不等待上一次完成就直接投递下一个请求了,,,这是很操蛋的做法,,,
然后继续复习下基础:
在EventSelect模型中获处理件类型流程是这样:
event受信,使用::WSAEnumNetworkEvents查询和这个event关联的socket发生的事件,根据查询到的事件类型去处理事件
在以每一次IO为查询对象重叠IO、IOCP模型中是这样:
使用GetOverlappedResult 或者 GetQueuedCompletionStatus然后根据重叠结构去查询投递的是什么类型的操作,然后找到关联的socket去操作,,,
这样必然要给OverLapped做个扩展,提供一种通过OverLapped查询操作类型和socket的能力。
通过分析代码,netFox关联socket是通过在创建完成端口的时候绑定SocketItem对象指针完成的,操作类型是通过对OverLapped结构加强完成的。
通过GetQueuedCompletionStatus获取到完成OverLapped以后使用一个宏:
(这是COverLapped类型) pSocketLapped=CONTAINING_RECORD(pOverLapped,COverLapped,m_OverLapped);
来获取包装后的OverLapped,然后获取操作类型,然后执行具体操作。
其实宏的展开如下:
(COverLapped*)((BYTE*)pOverLapped - (COverLapped*)(0)->m_OverLapped);
pOverLapped是获取到的某个COverLapped中的成员变量,(COverLapped*)(0)->m_OverLapped是到在COverLapped中的偏移,((BYTE*)pOverLapped - (COverLapped*)(0)->m_OverLapped) 就是根据pOverLapped推算出来的包含地址为pOverLapped作为成员变量m_OverLapped的COverLapped对象的地址。
然后就分别调用:
//发送完成函数
bool CServerSocketItem::OnSendCompleted(COverLappedSend * pOverLappedSend, DWORD dwThancferred);
//接收完成函数
bool CServerSocketItem::OnRecvCompleted(COverLappedRecv * pOverLappedRecv, DWORD dwThancferred);
为毛要区分Send OverLapped 和 Recv OverLapped呢,,,
应为投递一次Send不一定是瞬间完成的,在处理的过程中存储数据的内存应该是锁定的,也就是不允许修改的,,,所以OverLapped应该自己管理内存。
而recv应该也是需要有一片内存直接接受数据的,很奇怪netFox没有提供,,,
recv居然是在投递接受请求的时候给了一个空的buffer,然后在完成回调中自己再次调用recv方法接受数据。
接受有关的成员变量如下:
难道这么蠢的做法只是为了躲开分包算法?
具体的看看接受代码:
这是还是有分包算法的,总的来说接受流程如下:
直接使用recv把数据接受到SocketItem的缓冲区中,当长度大于CMD_HEAD之后,进入处理阶段,处理head数据各种判断,然后将数据扔出去,再调整缓冲区,,,
简单的说:
Send完全不考虑同步问题,不管一个劲的网队列投递Send请求,,,这边处理队列也是直接Send完事,完全不考虑上一次是否send成功,,,
Recv更是莫名其妙的使用完成端口绕一圈还回到recv直接接受了,,,
很狗血的做法,,,
更正下我自己狗血的不理解:
如果一个服务器提交了非常多的重叠的receive在每一个连接上,那么限制会随着连接数的增长而变化。如果一个服务器能够预先估计可能会产生的最大并发连接数,服务器可以投递一个使用零缓冲区的receive在每一个连接上。因为当你提交操作没有缓冲区时,那么也不会存在内存被锁定了。使用这种办法后,当你的receive操作事件完成返回时,该socket底层缓冲区的数据会原封不动的还在其中而没有被读取到receive操作的缓冲区来。此时,服务器可以简单的调用非阻塞式的recv将存在socket缓冲区中的数据全部读出来,一直到recv返回 WSAEWOULDBLOCK 为止。 这种设计非常适合那些可以牺牲数据吞吐量而换取巨大 并发连接数的服务器。当然,你也需要意识到如何让客户端的行为尽量避免对服务器造成影响。在上一个例子中,当一个零缓冲区的receive操作被返回后使 用一个非阻塞的recv去读取socket缓冲区中的数据,如果服务器此时可预计到将会有爆发的数据流,那么可以考虑此时投递一个或者多个receive 来取代非阻塞的recv来进行数据接收。(这比你使用1个缺省的8K缓冲区来接收要好的多。)
网络引擎整体结构:
SocketItem细节:
先来看几个底层结构:
//
重叠结构类
class COverLapped
{
// 变量定义
public:
WSABUF m_WSABuffer; // 数据指针
OVERLAPPED m_OverLapped; // 重叠结构
const enOperationType m_OperationType; // 操作类型
// 函数定义
public:
// 构造函数
COverLapped(enOperationType OperationType);
// 析构函数
virtual ~COverLapped();
// 信息函数
public:
// 获取类型
enOperationType GetOperationType() { return m_OperationType; }
};
// 接收重叠结构
class COverLappedSend : public COverLapped
{
// 数据变量
public:
BYTE m_cbBuffer[SOCKET_BUFFER]; // 数据缓冲
// 函数定义
public:
// 构造函数
COverLappedSend();
// 析构函数
virtual ~COverLappedSend();
};
// 重叠结构模板
template <enOperationType OperationType> class CATLOverLapped : public COverLapped
{
// 函数定义
public:
// 构造函数
CATLOverLapped() : COverLapped(OperationType) {}
// 析构函数
virtual ~CATLOverLapped() {}
};
class COverLapped
{
// 变量定义
public:
WSABUF m_WSABuffer; // 数据指针
OVERLAPPED m_OverLapped; // 重叠结构
const enOperationType m_OperationType; // 操作类型
// 函数定义
public:
// 构造函数
COverLapped(enOperationType OperationType);
// 析构函数
virtual ~COverLapped();
// 信息函数
public:
// 获取类型
enOperationType GetOperationType() { return m_OperationType; }
};
// 接收重叠结构
class COverLappedSend : public COverLapped
{
// 数据变量
public:
BYTE m_cbBuffer[SOCKET_BUFFER]; // 数据缓冲
// 函数定义
public:
// 构造函数
COverLappedSend();
// 析构函数
virtual ~COverLappedSend();
};
// 重叠结构模板
template <enOperationType OperationType> class CATLOverLapped : public COverLapped
{
// 函数定义
public:
// 构造函数
CATLOverLapped() : COverLapped(OperationType) {}
// 析构函数
virtual ~CATLOverLapped() {}
};
先复习下基础,Windows下的网络模型有很多种,这里只拿出三种来说:
EventSelect:基于信号机制,以socket为单位绑定信号量,当socket上有指定的事件发生时激发信号,然后查询事件处理事件重设事件,继续在信号量上等待。其实也是在伯克利select模型上的换不换药的加强。
OverLapped:分两种工作模式完成回调,和完成事件。重叠IO监视每次操作,每次IO都绑定一个重叠对象,当操作完成以后激发信号或者调用回调。
IOCP:和overlapped类似,不过结果经过了Windows的预处理以队列的形式挂在完成端口上
根据上面的复习,可以得出一个结论,IOCP环境中每一次IO操作都需要一个重叠结构,那么一个CServerSocketItem至少需要如些这些东东:
他要接受数据,所以必须有一个接受数据的 OverLapped
它要发送数据,说以必须有一个发送数据的 OverLapped
netFox对OverLapped做了使用了类似池的的管理手段,他的Send都是不等待上一次完成就直接投递下一个请求了,,,这是很操蛋的做法,,,
然后继续复习下基础:
在EventSelect模型中获处理件类型流程是这样:
event受信,使用::WSAEnumNetworkEvents查询和这个event关联的socket发生的事件,根据查询到的事件类型去处理事件
在以每一次IO为查询对象重叠IO、IOCP模型中是这样:
使用GetOverlappedResult 或者 GetQueuedCompletionStatus然后根据重叠结构去查询投递的是什么类型的操作,然后找到关联的socket去操作,,,
这样必然要给OverLapped做个扩展,提供一种通过OverLapped查询操作类型和socket的能力。
通过分析代码,netFox关联socket是通过在创建完成端口的时候绑定SocketItem对象指针完成的,操作类型是通过对OverLapped结构加强完成的。
通过GetQueuedCompletionStatus获取到完成OverLapped以后使用一个宏:
(这是COverLapped类型) pSocketLapped=CONTAINING_RECORD(pOverLapped,COverLapped,m_OverLapped);
来获取包装后的OverLapped,然后获取操作类型,然后执行具体操作。
其实宏的展开如下:
(COverLapped*)((BYTE*)pOverLapped - (COverLapped*)(0)->m_OverLapped);
pOverLapped是获取到的某个COverLapped中的成员变量,(COverLapped*)(0)->m_OverLapped是到在COverLapped中的偏移,((BYTE*)pOverLapped - (COverLapped*)(0)->m_OverLapped) 就是根据pOverLapped推算出来的包含地址为pOverLapped作为成员变量m_OverLapped的COverLapped对象的地址。
然后就分别调用:
//发送完成函数
bool CServerSocketItem::OnSendCompleted(COverLappedSend * pOverLappedSend, DWORD dwThancferred);
//接收完成函数
bool CServerSocketItem::OnRecvCompleted(COverLappedRecv * pOverLappedRecv, DWORD dwThancferred);
为毛要区分Send OverLapped 和 Recv OverLapped呢,,,
应为投递一次Send不一定是瞬间完成的,在处理的过程中存储数据的内存应该是锁定的,也就是不允许修改的,,,所以OverLapped应该自己管理内存。
而recv应该也是需要有一片内存直接接受数据的,很奇怪netFox没有提供,,,
recv居然是在投递接受请求的时候给了一个空的buffer,然后在完成回调中自己再次调用recv方法接受数据。
接受有关的成员变量如下:
//
状态变量
protected:
bool m_bNotify; // 通知标志
bool m_bRecvIng; // 接收标志
bool m_bCloseIng; // 关闭标志
bool m_bAllowBatch; // 接受群发
WORD m_wRecvSize; // 接收长度
BYTE m_cbRecvBuf[SOCKET_BUFFER*5]; // 接收缓冲
int iRetCode=recv(m_hSocket,(char *)m_cbRecvBuf+m_wRecvSize,sizeof(m_cbRecvBuf)-m_wRecvSize,0);protected:
bool m_bNotify; // 通知标志
bool m_bRecvIng; // 接收标志
bool m_bCloseIng; // 关闭标志
bool m_bAllowBatch; // 接受群发
WORD m_wRecvSize; // 接收长度
BYTE m_cbRecvBuf[SOCKET_BUFFER*5]; // 接收缓冲
难道这么蠢的做法只是为了躲开分包算法?
具体的看看接受代码:
//
接收完成函数
bool CServerSocketItem::OnRecvCompleted(COverLappedRecv * pOverLappedRecv, DWORD dwThancferred)
{
// 效验数据
ASSERT(m_bRecvIng== true);
// 设置变量
m_bRecvIng= false;
m_dwRecvTickCount=GetTickCount();
// 判断关闭
if (m_hSocket==INVALID_SOCKET)
{
CloseSocket(m_wRountID);
return true;
}
// 接收数据
int iRetCode=recv(m_hSocket,( char *)m_cbRecvBuf+m_wRecvSize, sizeof(m_cbRecvBuf)-m_wRecvSize,0);
if (iRetCode<=0)
{
CloseSocket(m_wRountID);
return true;
}
// 接收完成
m_wRecvSize+=iRetCode;
BYTE cbBuffer[SOCKET_BUFFER];
CMD_Head * pHead=(CMD_Head *)m_cbRecvBuf;
// 处理数据
try
{
while (m_wRecvSize>= sizeof(CMD_Head))
{
// 效验数据
WORD wPacketSize=pHead->CmdInfo.wDataSize;
if (wPacketSize>SOCKET_BUFFER) throw TEXT("数据包超长");
if (wPacketSize< sizeof(CMD_Head)) throw TEXT("数据包非法");
if (pHead->CmdInfo.cbMessageVer!=SOCKET_VER) throw TEXT("数据包版本错误");
if (m_wRecvSize<wPacketSize) break;
// 提取数据
CopyMemory(cbBuffer,m_cbRecvBuf,wPacketSize);
WORD wRealySize=CrevasseBuffer(cbBuffer,wPacketSize);
ASSERT(wRealySize>= sizeof(CMD_Head));
m_dwRecvPacketCount++;
// 解释数据
WORD wDataSize=wRealySize- sizeof(CMD_Head);
void * pDataBuffer=cbBuffer+ sizeof(CMD_Head);
CMD_Command Command=((CMD_Head *)cbBuffer)->CommandInfo;
// 内核命令
if (Command.wMainCmdID==MDM_KN_COMMAND)
{
switch (Command.wSubCmdID)
{
case SUB_KN_DETECT_SOCKET: // 网络检测
{
break;
}
default: throw TEXT("非法命令码");
}
}
else
{
// 消息处理
m_pIServerSocketItemSink->OnSocketReadEvent(Command,pDataBuffer,wDataSize, this);
}
// 删除缓存数据
m_wRecvSize-=wPacketSize;
MoveMemory(m_cbRecvBuf,m_cbRecvBuf+wPacketSize,m_wRecvSize);
}
}
catch ( )
)
{
CloseSocket(m_wRountID);
return false;
}
return RecvData();
}
bool CServerSocketItem::OnRecvCompleted(COverLappedRecv * pOverLappedRecv, DWORD dwThancferred)
{
// 效验数据
ASSERT(m_bRecvIng== true);
// 设置变量
m_bRecvIng= false;
m_dwRecvTickCount=GetTickCount();
// 判断关闭
if (m_hSocket==INVALID_SOCKET)
{
CloseSocket(m_wRountID);
return true;
}
// 接收数据
int iRetCode=recv(m_hSocket,( char *)m_cbRecvBuf+m_wRecvSize, sizeof(m_cbRecvBuf)-m_wRecvSize,0);
if (iRetCode<=0)
{
CloseSocket(m_wRountID);
return true;
}
// 接收完成
m_wRecvSize+=iRetCode;
BYTE cbBuffer[SOCKET_BUFFER];
CMD_Head * pHead=(CMD_Head *)m_cbRecvBuf;
// 处理数据
try
{
while (m_wRecvSize>= sizeof(CMD_Head))
{
// 效验数据
WORD wPacketSize=pHead->CmdInfo.wDataSize;
if (wPacketSize>SOCKET_BUFFER) throw TEXT("数据包超长");
if (wPacketSize< sizeof(CMD_Head)) throw TEXT("数据包非法");
if (pHead->CmdInfo.cbMessageVer!=SOCKET_VER) throw TEXT("数据包版本错误");
if (m_wRecvSize<wPacketSize) break;
// 提取数据
CopyMemory(cbBuffer,m_cbRecvBuf,wPacketSize);
WORD wRealySize=CrevasseBuffer(cbBuffer,wPacketSize);
ASSERT(wRealySize>= sizeof(CMD_Head));
m_dwRecvPacketCount++;
// 解释数据
WORD wDataSize=wRealySize- sizeof(CMD_Head);
void * pDataBuffer=cbBuffer+ sizeof(CMD_Head);
CMD_Command Command=((CMD_Head *)cbBuffer)->CommandInfo;
// 内核命令
if (Command.wMainCmdID==MDM_KN_COMMAND)
{
switch (Command.wSubCmdID)
{
case SUB_KN_DETECT_SOCKET: // 网络检测
{
break;
}
default: throw TEXT("非法命令码");
}
}
else
{
// 消息处理
m_pIServerSocketItemSink->OnSocketReadEvent(Command,pDataBuffer,wDataSize, this);
}
// 删除缓存数据
m_wRecvSize-=wPacketSize;
MoveMemory(m_cbRecvBuf,m_cbRecvBuf+wPacketSize,m_wRecvSize);
}
}
catch (
)
{
CloseSocket(m_wRountID);
return false;
}
return RecvData();
}
这是还是有分包算法的,总的来说接受流程如下:
直接使用recv把数据接受到SocketItem的缓冲区中,当长度大于CMD_HEAD之后,进入处理阶段,处理head数据各种判断,然后将数据扔出去,再调整缓冲区,,,
简单的说:
Send完全不考虑同步问题,不管一个劲的网队列投递Send请求,,,这边处理队列也是直接Send完事,完全不考虑上一次是否send成功,,,
Recv更是莫名其妙的使用完成端口绕一圈还回到recv直接接受了,,,
很狗血的做法,,,
更正下我自己狗血的不理解:
如果一个服务器提交了非常多的重叠的receive在每一个连接上,那么限制会随着连接数的增长而变化。如果一个服务器能够预先估计可能会产生的最大并发连接数,服务器可以投递一个使用零缓冲区的receive在每一个连接上。因为当你提交操作没有缓冲区时,那么也不会存在内存被锁定了。使用这种办法后,当你的receive操作事件完成返回时,该socket底层缓冲区的数据会原封不动的还在其中而没有被读取到receive操作的缓冲区来。此时,服务器可以简单的调用非阻塞式的recv将存在socket缓冲区中的数据全部读出来,一直到recv返回 WSAEWOULDBLOCK 为止。 这种设计非常适合那些可以牺牲数据吞吐量而换取巨大 并发连接数的服务器。当然,你也需要意识到如何让客户端的行为尽量避免对服务器造成影响。在上一个例子中,当一个零缓冲区的receive操作被返回后使 用一个非阻塞的recv去读取socket缓冲区中的数据,如果服务器此时可预计到将会有爆发的数据流,那么可以考虑此时投递一个或者多个receive 来取代非阻塞的recv来进行数据接收。(这比你使用1个缺省的8K缓冲区来接收要好的多。)
源码中提供了一个简单实用的解决WSAENOBUF错误的办法。我们执行了一个零字节缓冲的异步WSARead(...)(参见 OnZeroByteRead(..))。当这个请求完成,我们知道在TCP/IP栈中有数据,然后我们通过执行几个有MAXIMUMPACKAGESIZE缓冲的异步WSARead(...)去读,解决了WSAENOBUFS问题。但是这种解决方法降低了服务器的吞吐量。
总结:
解决方法一:
投递使用空缓冲区的 receive操作,当操作返回后,使用非阻塞的recv来进行真实数据的读取。因此在完成端口的每一个连接中需要使用一个循环的操作来不断的来提交空缓冲区的receive操作。
解决方法二:
在投递几个普通含有缓冲区的receive操作后,进接着开始循环投递一个空缓冲区的receive操作。这样保证它们按照投递顺序依次返回,这样我们就总能对被锁定的内存进行解锁。
如果一个服务器同时连接了许多客户端, 对每个客户端又调用了许多 WSARecv, 那么大量的内存将会被锁定到非分页内存池. 锁定这些内存时是按照页面边界来锁定的, 也就是说即使你 WSARecv 的缓存大小是 1 字节, 被锁定的内存也将会是 4k. 非分页内存池是由整个系统共用的, 如果用完的话最坏的情况就是系统崩溃. 一个解决办法是, 使用大小为 0 的缓冲区调用 WSARecv. 等到调用成功时再换用非阻塞的 recv 接收到来的数据, 直到它返回 WSAEWOULDBLOCK 表明数据已经全部读完. 在这个过程中没有任何内存需要被锁定, 但坏处是效率稍低.

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









