







好久没写datax的东西了。。
紧接着之前的说到
hdfsReader
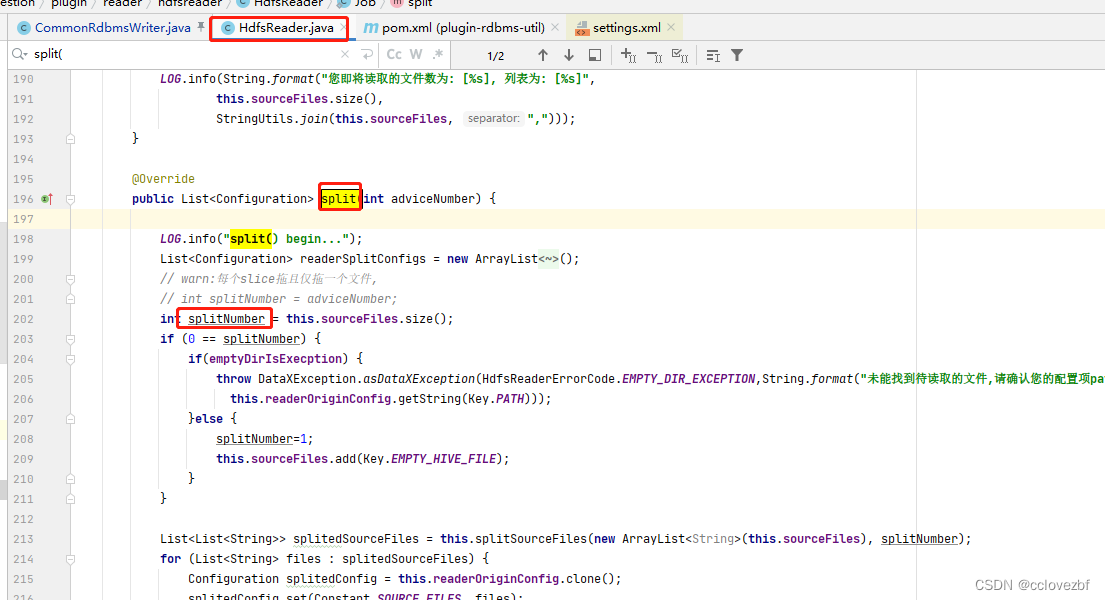
他的切片数是根据他的文件数来的。
比如 我一个table下有 10个文件, 就是分成10个tasks
所以有时候读hdfs hive的时候就会发现导数速度怎么也上不去。。。那么我们就要考虑怎么增加文件数量了?
这时候又有小伙伴要说了
增加hive的reduce个数, 减少每个reduce的数量,distribute by
这些都没错,但是都错了。
你hive 的引擎是啥 mr spark, tez?
你是否有合并小文件?你设置的块大小又是啥? 你是使用hive 的参数还是spark的参数
因为个人原因,我就讲下hive on spark 的例子...其余的自行探索。
以 ia_fdw_b_profile_company_biz_cover 这个表为例 我采用order by 模拟出一个大文件环境
insert overwrite table odsiadata.ia_fdw_b_profile_company_biz_cover
select * from odsiadata.ia_fdw_b_profile_company_biz_cover
order by partition_time
_____________________________________________________________________________
先来一个最普遍的distribute by round(rand()*10)
insert overwrite table odsiadata.ia_fdw_b_profile_company_biz_cover
select * from odsiadata.ia_fdw_b_profile_company_biz_cover
distribute by round(rand()*10)按照预想应该是分成10个小文件?实际上 ...

好像有用 又好像没用?这个时候怎么办?
第一反应...随机数太小。 全部随机到0 1 上 2-9屁都没有,说出来自己都不信..
第二反应 一头雾水不知道咋办。
这种时候,直接看运行日志 就算看不懂也要多看两下。

注意这里有个stage的名称是Spark Merge File Work
这个时候就该引起注意了 spark把小文件merge了?
仔细看下reduce stage 的东西 275个task

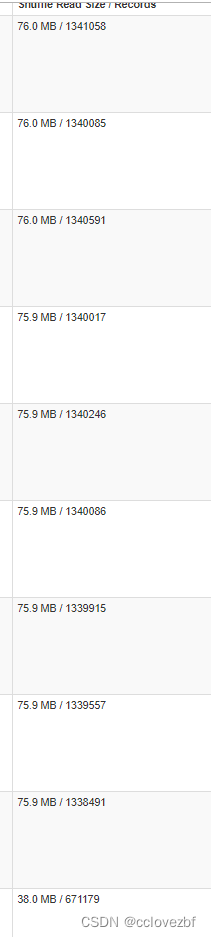
因为截图原因,就直说了 这个275个task里 只有10个task是有数据的
该表总数据量是1340w,可以看到上图都是133w左右 按照猜想,确实是分成了10个task的,所以distribute 是起了作用。
然后看spark merge file stage

可以看到就2个task,点击stderr 可以看到merge的操作

到现在前因后果都知道了。
那还不好说,改spark.merge的参数就好了。。
——————————————————————————————————————————
那参数是啥呢?总不能自己瞎写把,上hive查还是spark查还是百度查。
聪明的小伙伴可能都想到cdh里spark的配置了

笨笨的小伙伴咋办。
beeline -u "jdbc:hive2://node03.data.com:10000/default;principal=hive/node03@CDH.COM" -e "set" >/data/cc_test/set.properties
cat /data/cc_test/set.properties |grep merge
set hive.merge.size.per.task=268435456;
set hive.merge.sparkfiles=true;
那么测试.1
set hive.merge.sparkfiles=false
insert overwrite table odsiadata.ia_fdw_b_profile_company_biz_cover
select * from odsiadata.ia_fdw_b_profile_company_biz_cover
distribute by round(rand()*10)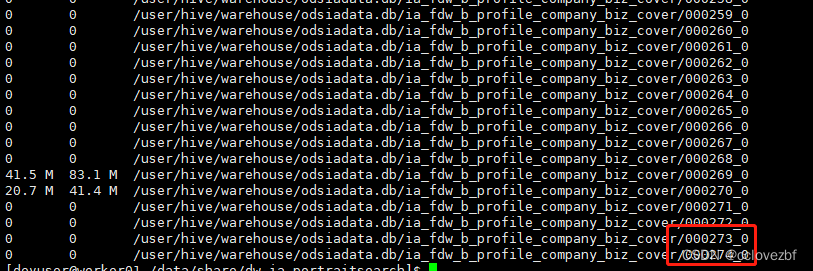
出现了275个文件 --为啥会出现275个。。有时间再研究

发现缺少了merge 的stage
——————————————————————————————————————————
测试.2 因为原始文件400多M分成10个差不多40多M 那就设置64M
set hive.merge.size.per.task=67108864;
set hive.merge.sparkfiles=true;
insert overwrite table odsiadata.ia_fdw_b_profile_company_biz_cover
select * from odsiadata.ia_fdw_b_profile_company_biz_cover
distribute by round(rand()*10)突然发现

大惊一场还是275个文件看了日志还没有merge。
难道我的文章要翻车了? 莫慌莫慌,我写之前都测过了的。。相信小伙伴们也有我这样的经历,本来都是ok的 怎么超出了自己的控制呢?
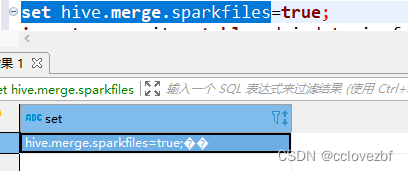
原来如此。各位小伙伴们记得不要把 ; 也执行了。。。!!!!!!!!!!!
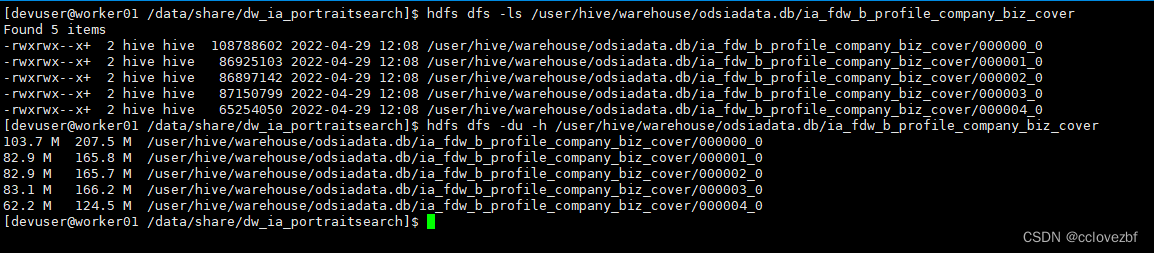
再看文件也好了,只是数量不如我们想的那么多。
因为我们原始的数据都是40M左右。这里merge的话不是说刚好64M,而是两个文件merge只后还要判断的
比如63M的文件和2M的文件 merge之后难道是64M 和1M 那merge还有啥用。肯定是65M了。
导这就结束了。
通过这样改变原始hive文件的数量,可以提高hdfsreader的效率。
-- 275task 这个问题 有时间再研究下。。着急的小伙伴可以评论下。。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









