







 本文介绍了t检验的历史,它由健力士公司员工戈斯特提出,因公司规定以“学生”笔名发表,又称“学生t检验”。还阐述了t检验思路,以啤酒厂比较两种种植工艺产量为例,说明需综合样本均值、方差和数量得出t值。最后介绍了t分布及如何根据t值和P值进行假设检验。
本文介绍了t检验的历史,它由健力士公司员工戈斯特提出,因公司规定以“学生”笔名发表,又称“学生t检验”。还阐述了t检验思路,以啤酒厂比较两种种植工艺产量为例,说明需综合样本均值、方差和数量得出t值。最后介绍了t分布及如何根据t值和P值进行假设检验。
t检验、t分布、t值其实都是同一个数学概念中的不同部分。
1 t检验的历史
阿瑟·健力士公司(Arthur Guinness Son & Co.)是一家由阿瑟·健力士(Arthur Guinness)于1759年在爱尔兰都柏林建立的一家酿酒公司:

不过它最出名的却不是啤酒,而是《吉尼斯世界纪录大全》:

1951年11月10日,健力士酒厂的董事休·比佛爵士(Sir Hugh Beaver)在爱尔兰韦克斯福德郡打猎时,因为没打中金鸻,于是和同行们争论哪种鸟飞得最快,彼此争论不休。由于当时的参考资料并不足以回答这个问题,这促使比弗想出版一本记载世界之最的书,这就是后来的《吉尼斯世界纪录大全》。
还有一个让健力士公司在历史留名的,就是他的员工威廉·希利·戈斯特(1876-1937):

在健力士公司,戈斯特提出了t检验以降低啤酒质量监控的成本,但健力士酒厂为了保护公司的商业机密和智慧财产,明文禁止员工发表文章。
戈斯特并没有因为这项规定而放弃他的学术研究发表,他在《生物统计期刊》以“学生”(The Student)为笔名,发表了关于t检验的文章,所以t检验又称为“学生t检验”。
直到1937年,戈斯特因心脏病去世之前,健力士酒厂一直不知道戈斯特从事统计研究工作,并以“学生”笔名发表研究成果。许多统计研究者要和戈斯特见面,都必须像间谍电影般地秘密安排见面地点和时间。
现在位于都柏林的健力士专卖店中有一个戈斯特的纪念碑,上面写著“化学家、统计学家威廉·希利·戈斯特,首席酿酒师,学生t检验”:

2 t检验的思路
啤酒,主要原料是大麦,啤酒厂肯定是希望尽力提高亩产。
比如,健力士公司有下面两块麦田:

左边的麦田采用传统A工艺进行种植,平均每株大麦可以结100粒穗子。
而右边的麦田采用改进过的B工艺种植,健力士公司想知道“B工艺是否提高了产量”。
为了节约成本、减小损耗,抠门的健力士公司从B工艺的麦田中采样了5株大麦,样本均值为120粒穗子。然后把难题抛给了戈斯特。
似乎直观看来产量提高了,毕竟均值增加了![]() ,可是戈斯特想得更多一些。
,可是戈斯特想得更多一些。
2.1 戈斯特的分析
戈斯特提出一个假设检验:
-
假设:B工艺没有提高产量,即AB下的麦穗都是同一个分布
-
检验:看看在此假设下,
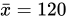 发生的概率高不高
发生的概率高不高
已知的数据是,A工艺下的单株麦穗的个数服从![]() ,标准差
,标准差![]() 未知的正态分布:
未知的正态分布:
![]()
而B工艺下的麦田的样本均值![]() ,采样了5株。
,采样了5株。
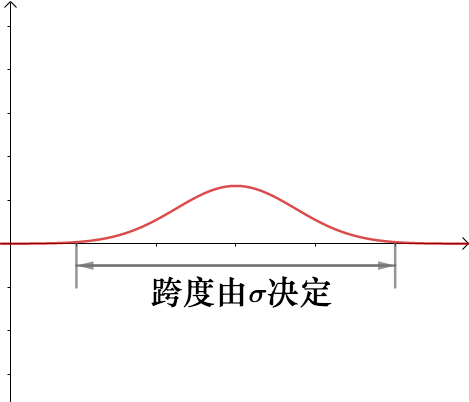
不同的标准差对应的正态分布图像不同:
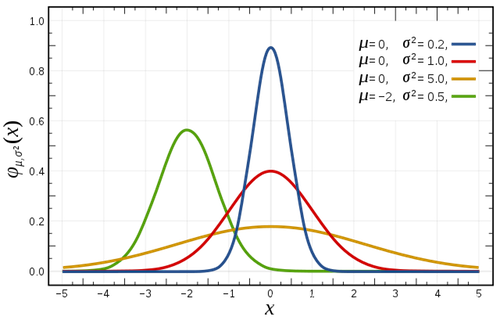
图像的跨度由标准差![]() 决定:
决定:
![]() 如果服从以下正态分布:
如果服从以下正态分布:
![]()
![]() ,跨度不大,采样五个点使其
,跨度不大,采样五个点使其![]() 的图像如下:
的图像如下:
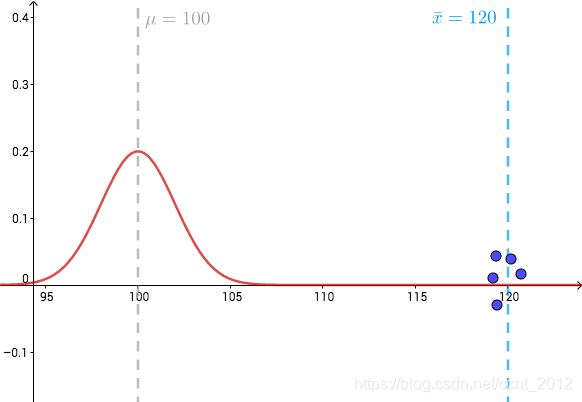
可见,![]() 的概率非常低,即AB下的麦穗是同一个分布的可能性不大,我们有很大把握可以认为B工艺真正提高了产量。
的概率非常低,即AB下的麦穗是同一个分布的可能性不大,我们有很大把握可以认为B工艺真正提高了产量。
而如果![]() 服从的是跨度更大的正态分布,采样五个点使其
服从的是跨度更大的正态分布,采样五个点使其![]() 的图像如下(为了演示,正态分布的参数选的不是很严谨):
的图像如下(为了演示,正态分布的参数选的不是很严谨):
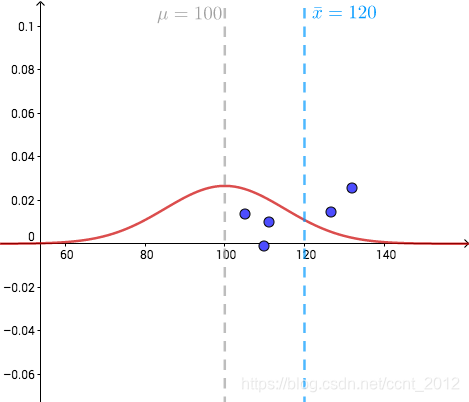
这样的正态分布下,![]() 的概率并不低,即AB下的麦穗还是可能为同一个分布的,我们没十足的把握认为B工艺提高了产量。
的概率并不低,即AB下的麦穗还是可能为同一个分布的,我们没十足的把握认为B工艺提高了产量。
因此,看起来不能单纯依靠![]() ,或许除以样本标准差
,或许除以样本标准差![]() 可以消除跨度的影响:
可以消除跨度的影响:
![]()
因为A工艺的![]() 我们不清楚,但是我们假设AB同分布,所以直接使用了样本标准差
我们不清楚,但是我们假设AB同分布,所以直接使用了样本标准差![]() 。
。
当然,样本数![]() 也会影响结果。比如说,在
也会影响结果。比如说,在![]() 下,得到
下,得到![]() ,那么根据大数定理,我们不用算了,基本上可以认为“B工艺提高了产量”。
,那么根据大数定理,我们不用算了,基本上可以认为“B工艺提高了产量”。
所以,戈斯特认为应该综合考虑样本均值![]() 、样本方差
、样本方差![]() 和样本数
和样本数![]() ,给出了一个统计量t值:
,给出了一个统计量t值:
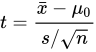
该统计量越大说明AB工艺导致的差别越大,越有可能说明“B工艺提高了产量”。
3 t分布
对于t值:
对应的概率密度函数,也就是t分布为:
其中![]() ,也叫做自由度。而
,也叫做自由度。而![]() 为伽马函数。
为伽马函数。
![]() 接近于正态分布
接近于正态分布![]() (灰色的虚线就是
(灰色的虚线就是![]() ),下面是
),下面是![]() 的t分布:
的t分布:

而t值,实际上对应的就是横坐标的值,比如说t值等于4:
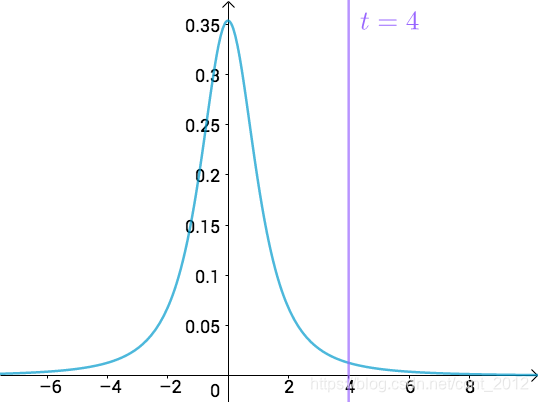
t=4之后的曲线下面积其实就是P值
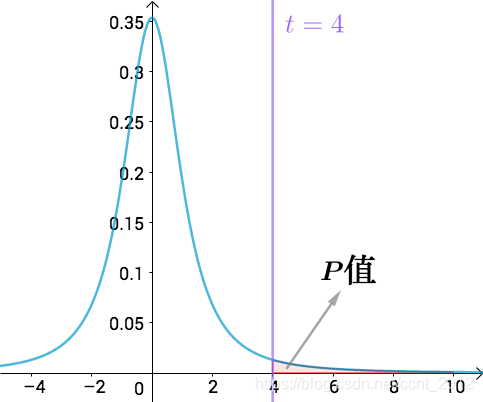
所以,我们知道t值之后,就可以根据![]() 以及要求的P值,查出当前的t值是否会拒绝我们的假设。
以及要求的P值,查出当前的t值是否会拒绝我们的假设。
举个例子,比如本文中的AB工艺下的数据为:
![]()
计算出来:
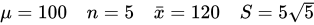
服从![]() 的t分布:
的t分布:
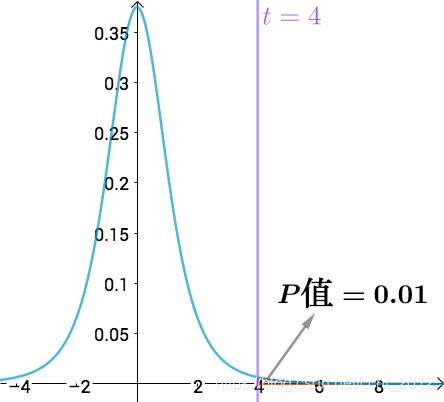
如果我们要求![]() 的显著水平的话,那么就可以拒绝“B工艺没有提高产量”这个假设了。
的显著水平的话,那么就可以拒绝“B工艺没有提高产量”这个假设了。



















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











