







首先给出acwing题目链接 -> 802 区间和
需要掌握的前提知识: vector(使用方法)、pair(使用方法)、auto(自动判断变量)、二分法、离散化思想。
这里给出acwing二分法的模板,和对应三个知识点的csdn超链接
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
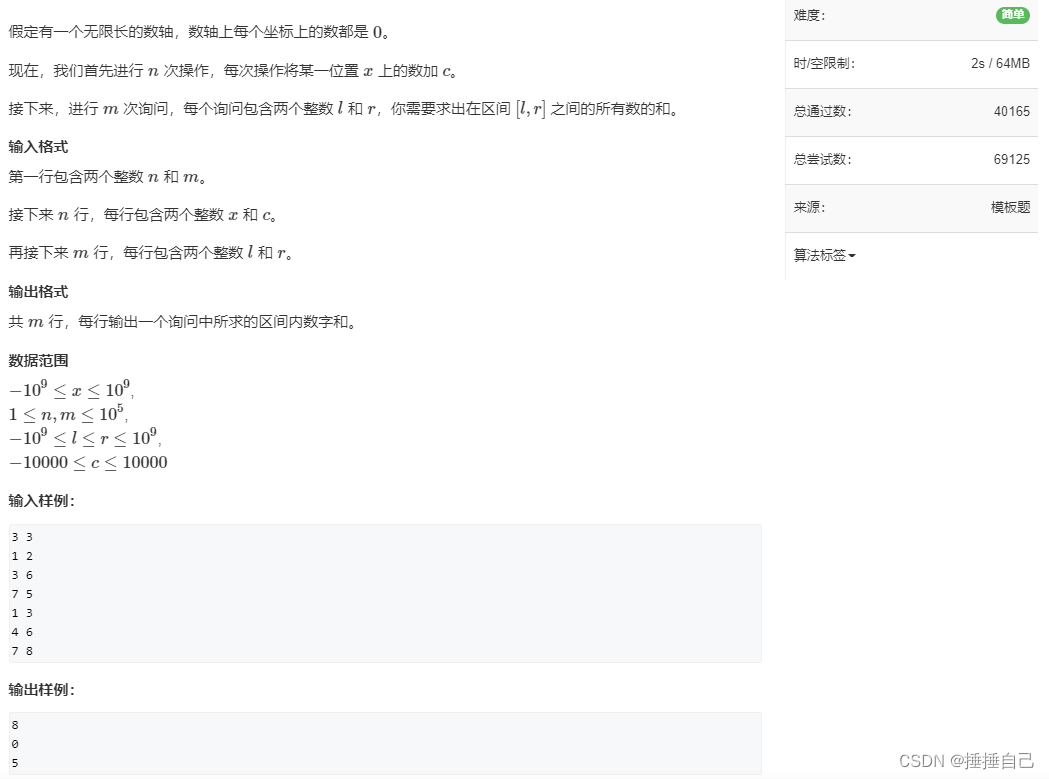
可能有些小伙伴没有办法看到该acwing题目,下面是一张题目截图。(图片和题目均来自于AcWing!)
所谓离散化(说人话就是)我暂时认为是:本来有一段特别长的数组,但是其中存储的值比较分散,最终导致该数组的利用率不高,继而采取的一种方式。就是将有价值的值存储进一个另外的数组并且能够查找到数组内所有的值。
题解的思路是:
我们需要一个能存储对应下标和数值的数组,并且我们并不清楚这个数组的具体长度。所以这时候就需要用到pair和vector,将pair作为vector的类型。然后我们还需要创建一个数组来存储离散化后的对应真实下标。
开始动手:
第一步:
typedef pair<int, int> PII;//因为存储的下标和值是两部分,所以用pair
vector<PII> add, query; //add用来作为映射表插入值,query是为了查询表
vector<int> alls;
第二步:
n m -> 存储接下来出现的行数
l r -> 存储 区间 下标
x c -> 分别存储 有效数值下标和 有效数值
const int N = 300010;//查询操作有两个坐标,离散操作有一个坐标,总共3 * 1e5
int a[N], s[N];//a是存储值,s是存储值的前缀和也就是区间和
int n, m, l, r, x, c;
第三步:
for(int i = 0; i < n; i ++ )
{
cin >> x >> c;
add.push_back({x, c});// 将下标和值插入表中
alls.push_back(x);// 将下标插入alls中
}
for(int i = 0; i < m; i ++ )
{
cin >> l >> r;
query.push_back({l, r});// 创建查询表
alls.push_back(l);
alls.push_back(r);
}
现在 add数组中的情况模拟:
| C1: 2 | C2: 6 | C3: 5 | … |
|---|---|---|---|
| X1: 1 | X2: 3 | X3: 7 | … |
| 0 | 1 | 2 | … |
query 数组中存储的情况模拟:
| R1: 3 | R2: 6 | R3: 8 | … |
|---|---|---|---|
| L1: 1 | L2: 4 | L3: 7 | … |
| 0 | 1 | 2 | … |
alls 数组中存储情况模拟:
| x:1 | x2: 3 | x3: 7 | L1: 1 | r1: 3 | L2: 4 | r2: 6 | L3: 7 | r3: 8 | … |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
第四步:
sort排序
去重操作
sort(alls.begin(), alls.end());// 排序为了二分查找
alls.erase(unique(alls.begin(), alls.end()), alls.end());
// 去重复, 通过画图可以看出其实不去重也一样,因为重复的部分没有值
alls 数组中存储情况模拟:
| x:1 | L1: 1 | x2: 3 | r1: 3 | L2: 4 | r2: 6 | x3: 7 | L3: 7 | r3: 8 | … |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
第五步:进行前缀和以及求区间值
//处理插入
for(auto item : add)
{
int x = midFind(item.first);// 从表中找到真实下标
a[x] += item.second;
}
//预处理前缀和
for(int i = 1; i <= alls.size(); i ++ ) s[i] += s[i - 1] + a[i];
//处理查询
for(auto item : query)
{
int l = midFind(item.first), r = midFind(item.second);
cout << s[r] - s[l - 1] << endl;
}
循环中的解析:
add.first = x1;
x = midFind(x1);
x = 1;
a[1] = c1;
add.first = x2;
x = midFind(x2);
x = 3;
a[3] = c1 + c2;
…
此时的根据图表得出:
a[1] = c1; a[2] = 0; a[3] = c1 + c2; a[4] = 0…a[7] = c1 + c2 +c3;…
下边给出完整代码
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;//因为存储的下标和值是两部分,所以用pair
vector<PII> add, query; //add用来作为映射表插入值,query是为了查询表
vector<int> alls;
const int N = 300010;
int a[N], s[N];//a是存储值,s是存储值的前缀和也就是区间和
int n, m, l, r, x, c;
int midFind(int x)
{
int l = 0, r = alls.size() - 1;
while(l < r)
{
int mid = l + r >> 1;
if(alls[mid] >= x) r = mid;
else l = mid + 1;
}
return l + 1;// 因为前缀和下标是从1开始,所这里直接 +1,避免后续麻烦。
}
int main()
{
cin >> n >> m;
for(int i = 0; i < n; i ++ )
{
cin >> x >> c;
add.push_back({x, c});// 将下标和值插入表中
alls.push_back(x);// 将需要离散的数值插入alls中
}
for(int i = 0; i < m; i ++ )
{
cin >> l >> r;
query.push_back({l, r});// 创建查询表
alls.push_back(l);
alls.push_back(r);
}
sort(alls.begin(), alls.end());// 排序为了二分查找
alls.erase(unique(alls.begin(), alls.end()), alls.end());// 去重复, 通过画图可以看出其实不去重也一样,因为重复的部分没有值
for(auto item : add)
{
int x = midFind(item.first);// 从表中找到真实下标
a[x] += item.second;
}
for(int i = 1; i <= alls.size(); i ++ ) s[i] += s[i - 1] + a[i];
for(auto item : query)
{
int l = midFind(item.first), r = midFind(item.second);
cout << s[r] - s[l - 1] << endl;
}
}
最后想说一下感悟,动手真的是要比空想对解题有巨大帮助,除非你是阿尔法狗doge。
如果上述理解有什么不对的地方请及时指出,我将感谢你的不吝赐教。
















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











