







虽然还是训练一个模型,但是一个模型训练了多个专家,多个专家可以分离。
一、摘要:
多任务学习 (MTL) 中的优化比单任务学习 (STL) 更具挑战性,因为来自不同任务的梯度可能是矛盾的。当任务相关时,在它们之间共享一些参数可能是有益的(合作)。然而,有些任务需要额外的参数,具有特定类型数据或歧视(专业化)的专业知识。为了解决 MTL 挑战,我们提出了 Mod-Squad,这是一种新模型,可模块化为专家组(“Squad”)。这种结构使我们能够将合作和专业化形式化为匹配专家和任务的过程。我们在单个模型的训练期间优化这个匹配过程。具体来说,我们将专家 (MoE) 层的混合合并到 Transformer 模型中,并引入了一种新的损失,它结合了任务和专家之间的相互依赖。因此,每个任务只激活一小组专家。这可以防止所有任务之间共享整个主干模型,这加强了模型,尤其是当训练集大小和任务数量扩大时。更有趣的是,对于每个任务,我们可以将一小组专家提取为一个独立的模型,该模型保持与大型模型相同的性能。在具有 13 个视觉任务的 Taskonomy 数据集和具有 5 个视觉任务的 PASCALContext 数据集上的广泛实验表明了我们方法的优越性。项目页面可以在 https://vis-www.cs.umass.edu/mod-squad 访问。
二、引入
MTL 有两个众所周知的挑战:
- (1)跨任务的梯度冲突 [5, 38];
- (2)如何设计具有高准确性和计算效率的架构。
许多以前的MoE工作[29,31,40]使用负载平衡损失,鼓励专家使用的频率(在所有任务和数据集中)高度相似。一些 MoE 方法 [18, 26] 在多任务场景中每个任务的前向传递之后直接应用这种损失,以便每个任务平均使用所有专家。然而,这种方法可能会迫使专家使用相互抵消的学习梯度在冲突任务上设置参数。换句话说,虽然专家可能受益于在某些任务对之间共享,但可以通过被迫在其他任务对之间共享来伤害。这是在这种专家平衡损失下训练多任务模型的难度的解释。
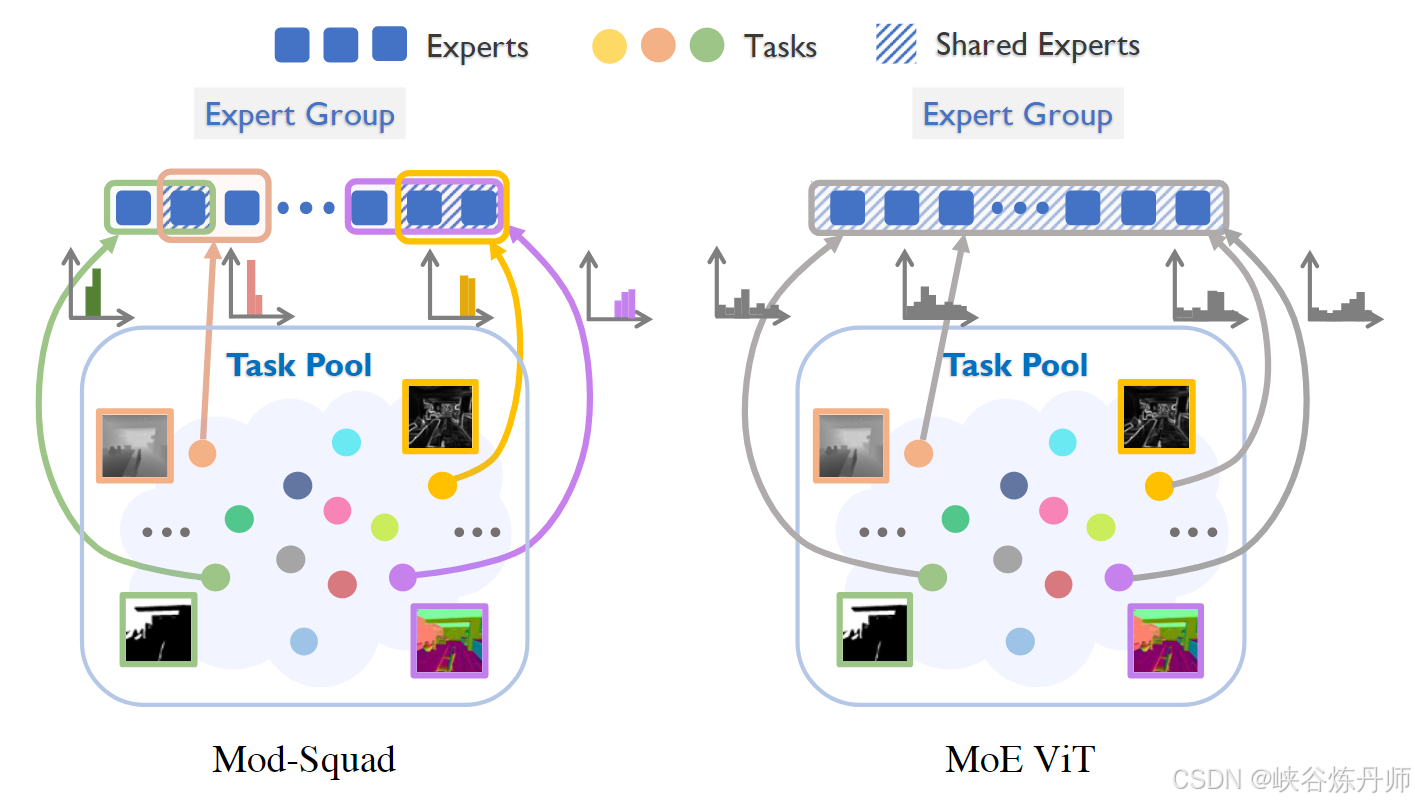
我们的主要动机是专家应该在某些任务(合作)中利用共性,但专注于需要特定特征且不会相互干扰的任务子集(专业化)。
这种专家稀疏化允许我们的模型分解为更小的单任务模型,这些模型表现得非常好。
有趣的是,我们发现我们的模型收敛到这样一种状态,即经过训练后,大多数专家从未或很少用于许多任务(专业化的证据),但专家在其激活频率上仍然平衡。此属性使我们能够从每个任务的巨模型中提取一个紧凑的子网络。以这种方式提取的小型网络独立工作,作为单个任务的独立模型,没有性能下降。此属性使我们能够在放大的多任务学习场景中训练一个巨大的稀疏模型,然后为每个任务获得高性能的紧凑的子网络。
三、方法
M个任务,Q张图片
。这里假设每个任务都用上Q中所有图片。
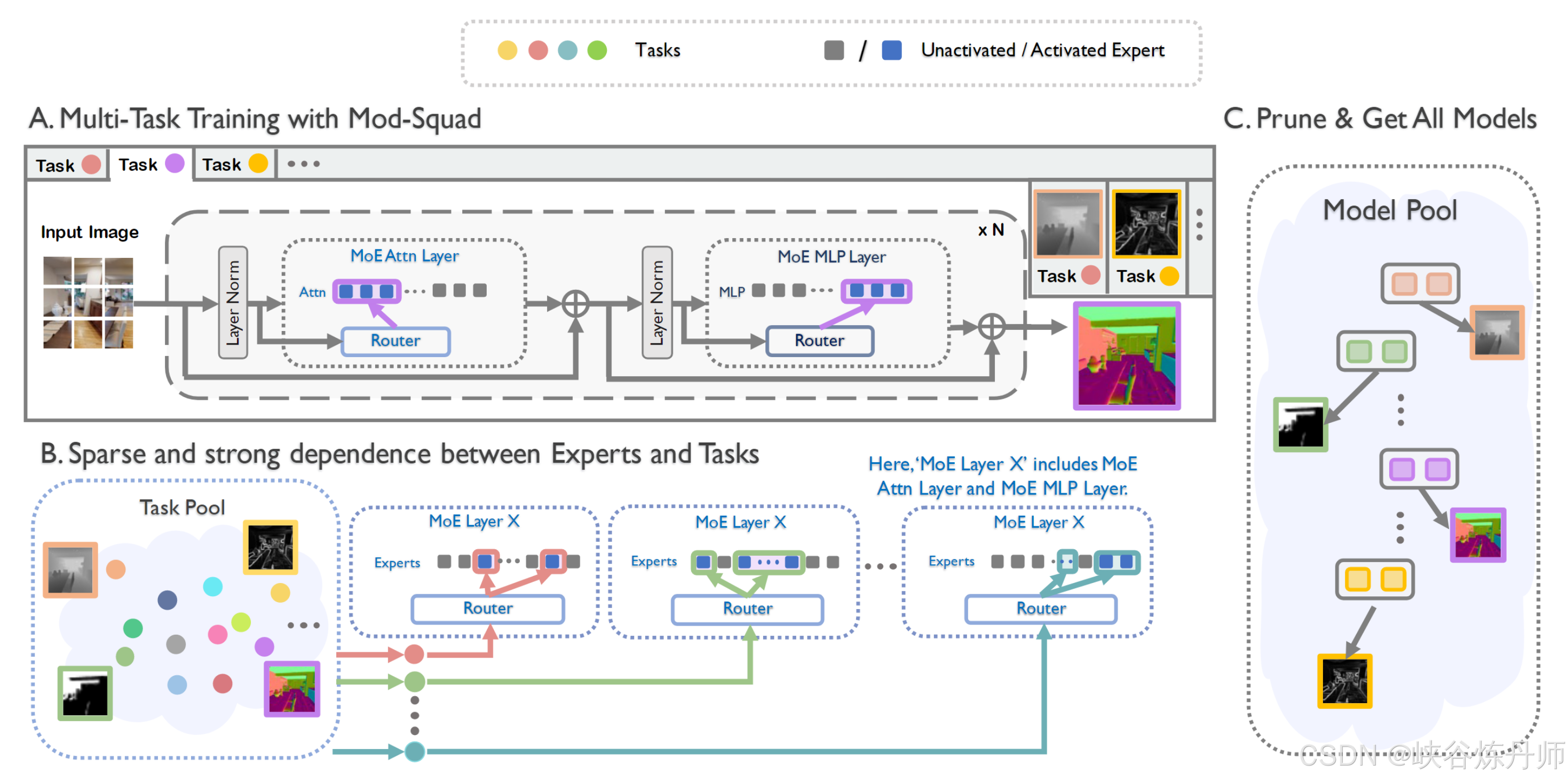
我们的多任务基础模型的管道。Mod-Squad 中的每个变压器块都包含一个 MoE 注意力网络 (MoE attn.) 和一个 MoE MLP 网络。多任务模型 Mod-Squad 使用我们提出的互信息损失进行训练。Mod-Squad 在专家和任务之间有很强的依赖性。然后我们可以为每个任务从 Mod-Squad 中提取一个小的子网络,而不会性能下降。
3.1. Preliminaries
Mixture of Experts:
路由网络:
Softplus 是 ReLU 函数的平滑近似:![]()
3.2. Mod-Squad
我们将MoE注意块(MoA)[40]和MoE MLP块[31]定制入变压器层。每个MoE块由N个专家组成,可以是注意力头或 MLP 层。以及 M 个特定于任务的路由网络
,以输入标记(Input tokens)为条件选择专家。请注意,每个路由网络
都有自己的参数
。我们还将可学习的任务嵌入添加到隐藏输入状态,以便每个专家都知道目标任务:
其中i是任务id,是对应的任务嵌入。
3.3. A joint probability model over tasks and experts
定义概率模型,随机采样一个任务(这里认为任务间是均匀采样),然后根据概率分布
,输入随机图像。
对于给定的MoE层:定义为路由网络对任务
使用专家
的频率。由于路由网络不会将专家硬分配给任务,而是为每个专家分配由 softmax 函数产生的权重,我们将这些软权重相加以测量频率:
是图像集合
的输入
上任务
的专家
的权重。
是任务
的图像总数。
联合概率:,显然
。
作者认为:experts should be dependent on tasks。采用任务和专家之间的互信息(mutual information)概率模型建模:
(5)
如果专家被分配到所有任务的频率相等,那么互信息将为0。如果每个专家被分配到一个任务(当M = N时),那么相关性(因此互信息)最大化。
3.4. Maximize mutual information between experts and tasks
公式(5)可变成:
(6)
- 第一项:
,是一个负熵,最大化这一项鼓励条件分布的锐度。
- 第二项:
由任务分布决定,是个常数
- 第三项:是
的熵。最大化该术语鼓励
损失函数:
是任务特定损失
的自动平衡权重(可学习)。Y表示MoE层,
表示Y中所有专家。
3.5 Train Once and Get All
Mod-Squad 在转发来自同一任务的单个图像和多个图像时激活专家的子集。此外,在转发整个多任务数据集时,所有专家都均匀地用于 Mod-Squad。这保证了 Mod-Squad 的容量被充分利用并且没有浪费。
得益于 Mod-Squad 在图像级和任务级、未使用的或很少使用的专家在进行单任务推理时可以在每个 MoE 模块中删除。这可以通过计算每个专家对任务的使用频率并删除那些频率小于阈值 θ 的专家来完成。请注意,某些任务可以使用更多专家,其他任务对每个 MoE 层使用较少。例如,低级任务可能需要网络前几层的更多专家,高级任务可能需要网络最后几层的更多专家。Mod-Squad 能够根据任务的要求动态自组织架构和选择专家,这为架构提供了一定程度的自由度和分配模型容量的额外灵活性。
在删除专家后,我们的修剪模型可以直接部署到各自的任务中。由于删除的专家从未或很少使用,修剪后的模型实现了与原始模型相同的性能水平,但参数数量要少得多,没有任何微调。在我们设置 θ = 0 并保持所有曾经使用的专家的情况下,我们观察到性能没有下降,同时仍然有效地修剪了很大一部分模型。这种删除专家过程类似于修剪,但我们只是调整一个简单的阈值,然后删除策略,并且不需要像一些修剪工作[3]那样进行额外的训练。一旦训练,就可以为所有任务提取一系列小的子网络。此属性使我们能够构建一个非常大的模型受益于所有任务,但只需要一小部分模型容量来进行单任务推理或微调。
四、实验
4.1 实验设置
数据集和任务。我们在两个多任务数据集上进行评估:PASCAL-Context [25] 和 Taskonomy [39]。PASCAL-Context 包括 10,103 个训练图像和 9,637 个测试图像,具有边缘检测 (Edge)、语义分割 (Seg.)、人体部位分割 (H.部分)、表面法线 (Norm.) 和显着性检测 (Sal.)。Taskonomy 基准包括 3,793k 训练图像和 600k 测试图像,具有 16 种类型的注释。我们使用它们之间的13个注释作为我们的多任务目标:对象分类、场景分类、欧氏深度深度估计、z缓冲区深度深度估计、表面法线、曲率估计、2D中的边缘检测和3D中的关键点检测、2D和3D中的关键点检测、2D和2.5D中的无监督分割。
评价指标:相对于单任务模型的提升: ![]() ,这里的
,这里的是普通的单任务模型,最终评价将每个任务的平均。
主干网络是ViT-base和ViT-small。
- ViT-small使用15专家,top-k为6
- ViT-base使用24名专家,top-k为12。
- 对于MoE MLP,我们使用16名专家,top-k为4。
Taskonomy上的特定于任务的头部是单个线性层。在 PASCAL-Context 上用与 [18] 相同的多层网络。我们设置和删除阈值θ = 1.0%。
在 PASCAL-Context 上,超参数与 [18] 中的相同。在 Taskonomy 上,我们将基础学习率设置为 2e-4,批量大小为 1, 440 和 AdamW [22] 作为优化器。权重衰减为 0.05。我们使用 10 个预热 epoch,总训练 epoch 为 100,模型在 240 个 NVIDIA V100 GPU 下收敛 80 小时。余弦衰减 [21] 用于学习率计划。
4.2 MTL实验结果

Taskonomy 数据集上每个任务的度量。对于每个任务,我们使用不同的指标来评估其性能。
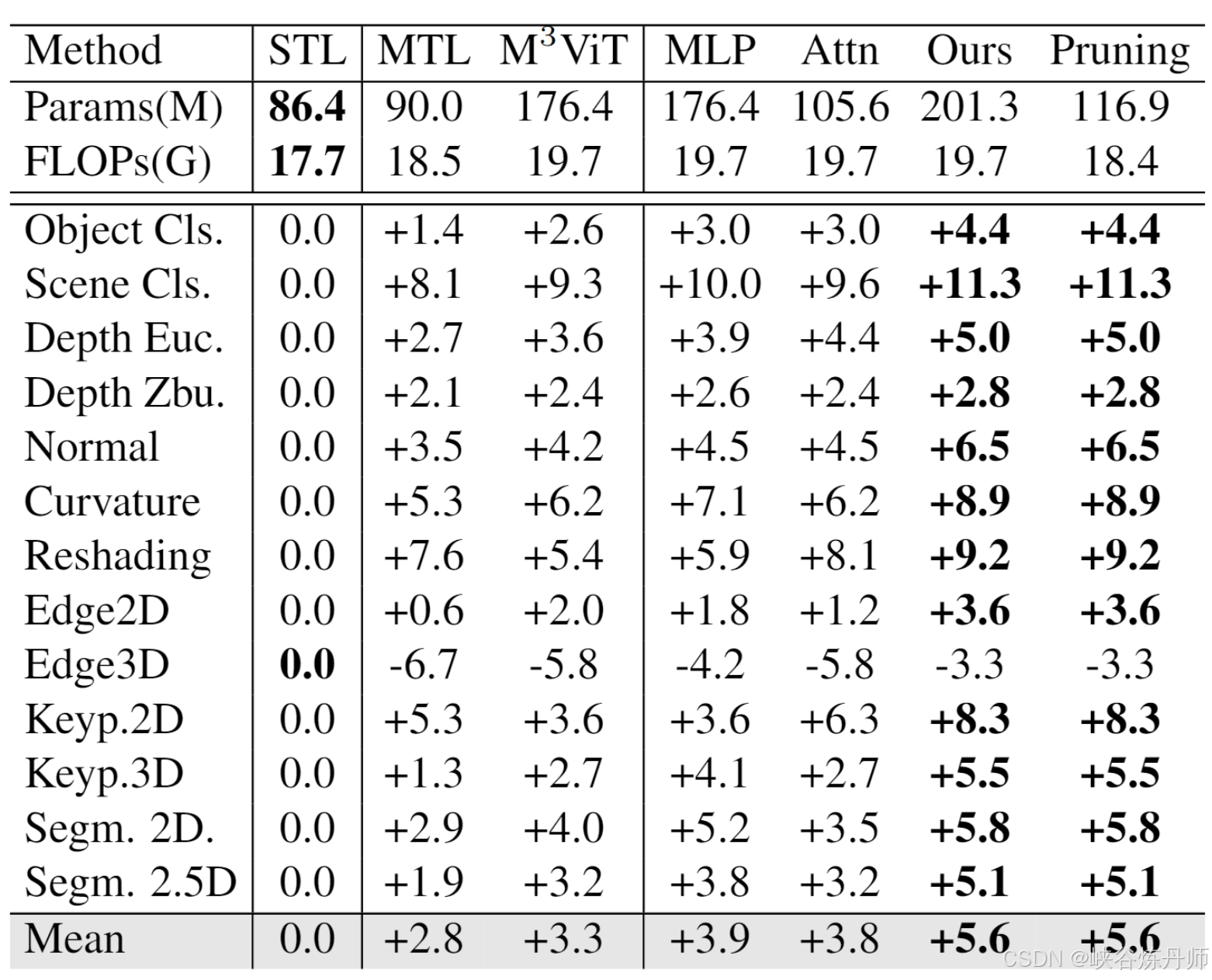
MTL方法在Taskonomy上的∆t比较。我们报告了他们相对于 vanilla 单任务模型每个任务的平均下降。MLP 和 Attn 分别表示在主干中仅使用 MoE MLP 和 MoE 注意力网络。
在计算成本和模型容量方面,我们使用 ViT-Base 主干的模型计算成本非常低(19.7G FLOPs),同时受益于巨大的模型容量(201.3M),对比ViTBase的MTLbaseline:18.5G FLOPs with 86.4M parameters。此外,当计算成本和模型容量相同时,我们的独立剪枝模型在每个单独任务保持与 Mod-Squad 相同的性能:STL: 18.4 FLOPs vs. 17.7 FLOPs和116.9M vs. 86.4M。
4.3. Experts, Tasks, and Pruning
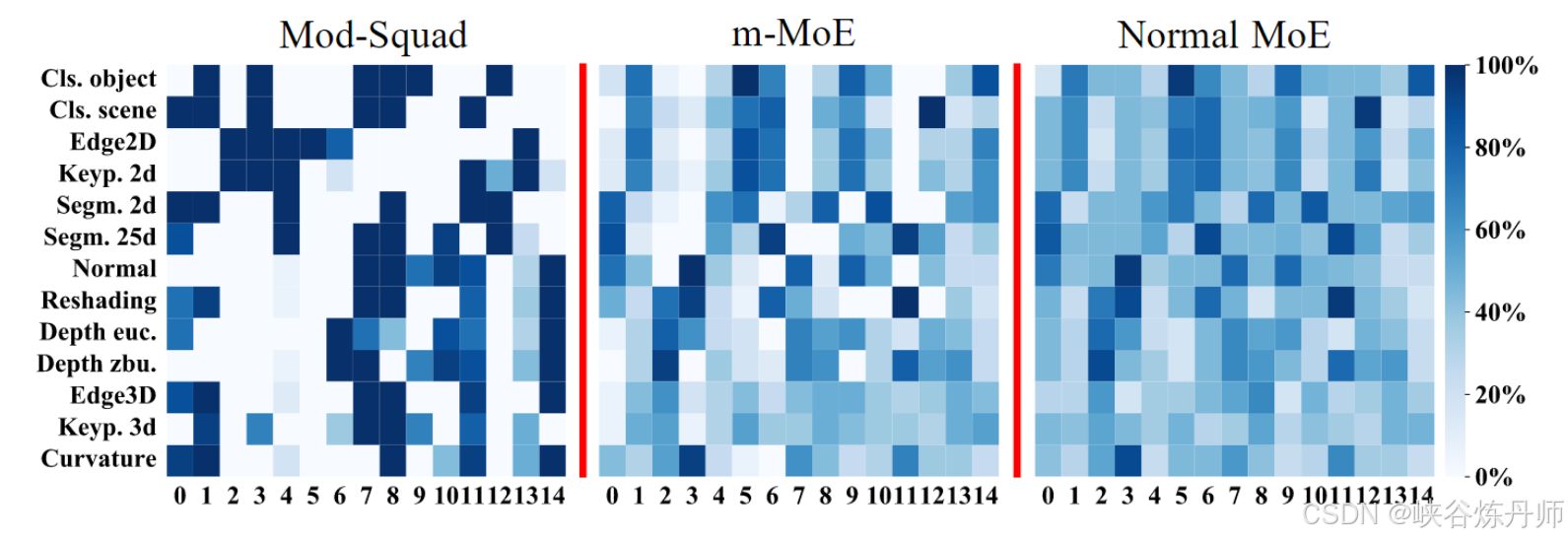
为每项任务选择专家的频率的可视化。
两种删除专家的方法:
- Thresh and remove:删除使用频率低于θ的专家,如果专家数量小于top-k,那就保留更少专家
- Keep the top:保留使用频率最高的H%专家
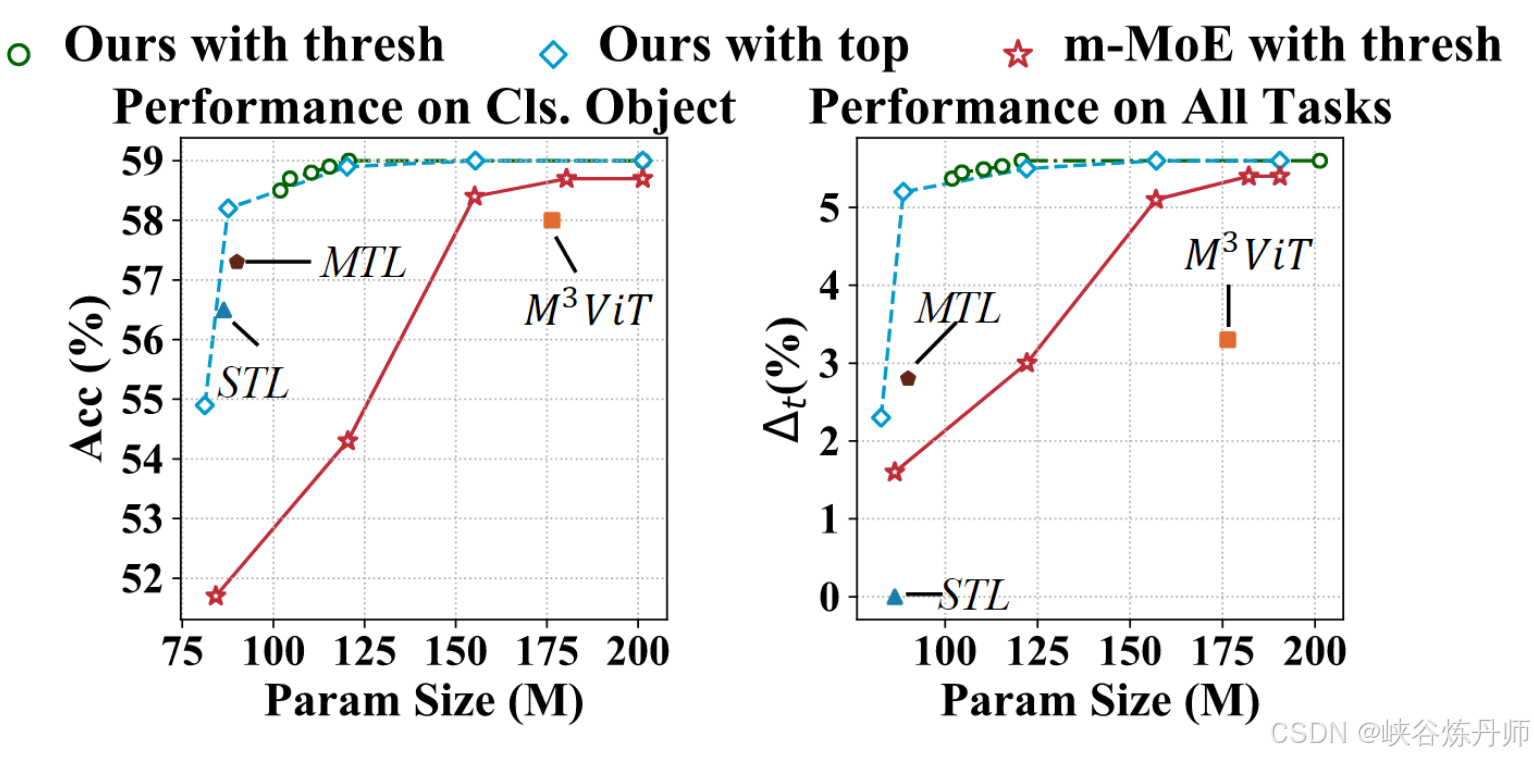
修剪的消融研究。我们探索了两种修剪方式:(1)阈值然后用 θ (2) 删除每个 MoE 模块中使用频率最高的前 H% 专家。对于第一种修剪方式,我们将 θ 的结果报告为 90%、50%、20%、5%、0.1% 和 0.0%(无修剪)。对于第二种修剪方式,我们报告了 H% 的结果为 30%、40%、60%、80% 和 100%(无修剪)。我们还将我们的修剪与在修改后的 MoE (m-MoE) 上应用相同的修剪策略进行比较。
Fine-tuning the router network:训练新任务:调整轻量级路由网络和特定于任务的头部,所有其他参数都被冻结。
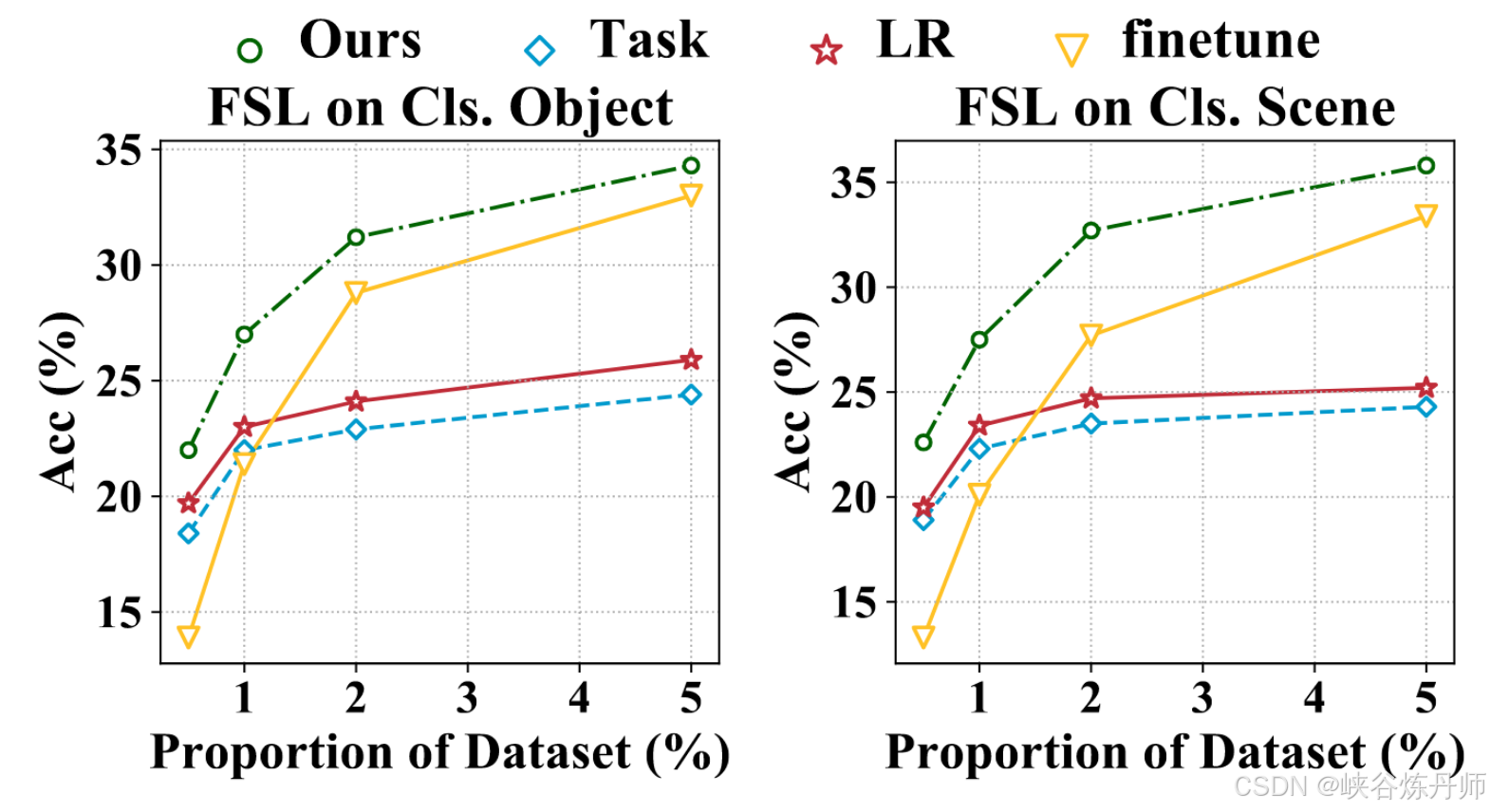
路由器微调可以通过选择合适的专家快速学习新任务。我们在 Taskonomy 的另外 11 个任务上训练我们的模型并转移到 cls。训练样本较少的对象和cls.scene。我们将few-shot分类精度与以下三个基线进行比较。(1) 微调:我们在少数训练样本上微调整个模型。(2) 任务:我们冻结主干模型,只训练新的特定于任务的头部。(3) LR:最先进的基于逻辑回归的小样本学习方法 [33]。我们报告了使用训练集 0.5%、1%、2% 和 5% 进行训练时的测试准确性。
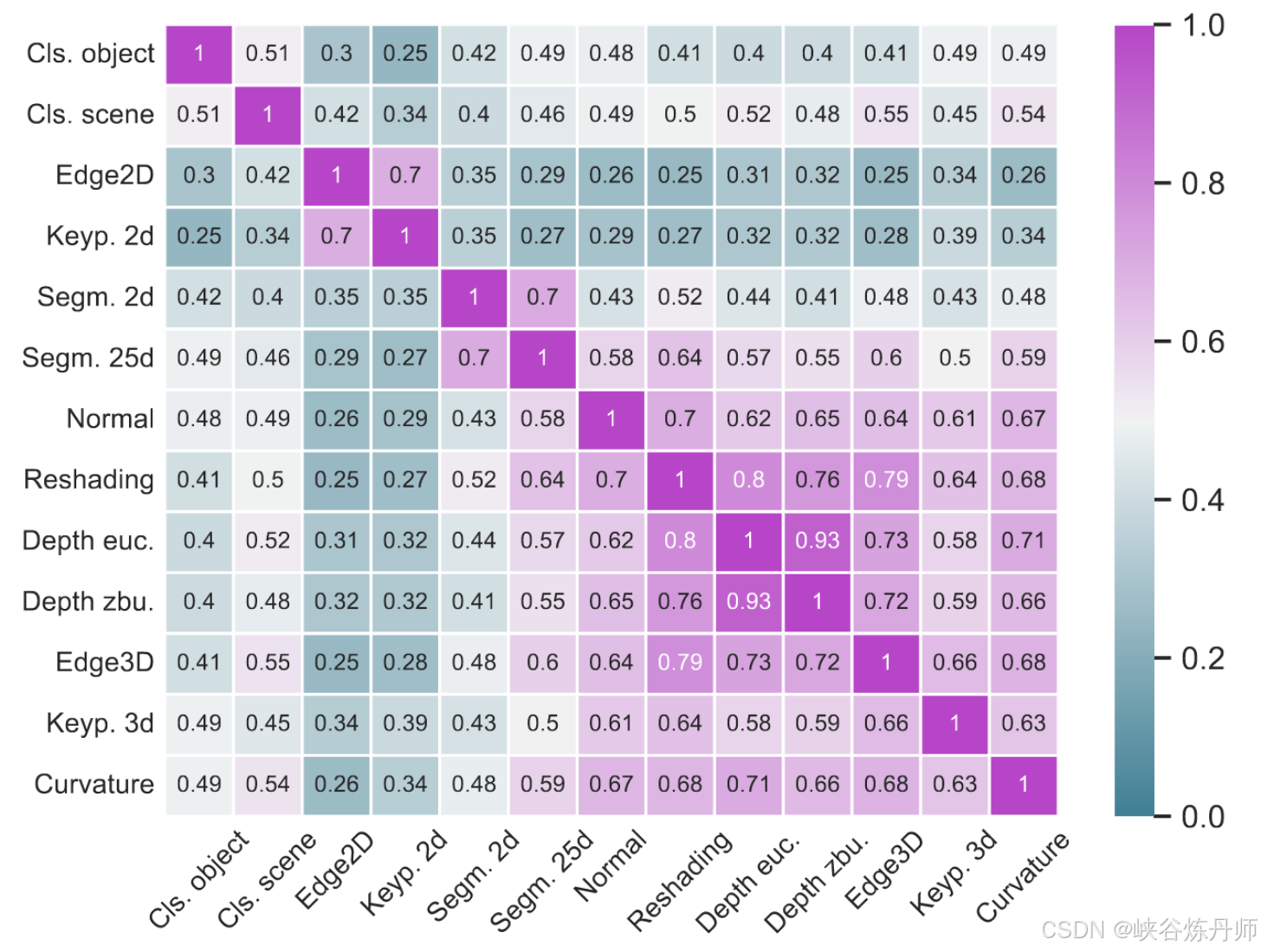
Task Relation:Mod-Squad 不仅可以像其他多任务模型那样隐式建模任务关系,还可以显式可视化它。我们将任务之间的相似性定义为在给定相同输入的情况下共享专家百分比的平均值。如果两个任务比其他成对的任务共享更多的专家,则认为它们更相关。这个定义可能并不完全准确,但基于一个简单的规则:相关任务比不相关的任务更有可能共享专家。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









