






DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning
论文网址:[2403.08506] DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning (arxiv.org)中文翻译:联邦学习中多个潜在域泛化的分离提示调优
一、摘要
联邦学习 (FL) 已成为从分散数据中学习的强大范式,联邦域泛化进一步考虑分散训练数据(源域)中不存在测试数据集(目标域)。然而,大多数现有的 FL 方法都假设在训练期间提供域标签,并且它们的评估对域的数量施加了明确的约束,必须严格匹配客户端的数量。由于现实世界中大量边缘设备的利用不足和额外的跨客户端域注释,这种限制可能不切实际,并涉及潜在的隐私泄露。在本文中,我们提出了一种高效且新颖的方法,称为解开提示调整 (DiPrompT),这是一种通过学习自适应提示以分布式方式进行域泛化来解决上述限制的方法。具体来说,我们首先设计了两种类型的提示,即全局提示来捕获所有客户端和域提示的一般知识,以捕获特定领域的知识。它们消除了对源域和目标域之间的一对一映射的限制。此外,引入了动态查询度量来自动搜索每个样本的合适域标签,其中包括基于提示调优的两步文本图像对齐,无需劳动密集型注释。在多个数据集上的广泛实验表明,当没有提供域标签时,我们的 DiPrompT 比最先进的 FL 方法实现了卓越的域泛化性能,甚至优于许多使用域标签的集中式学习方法。
一、论文动机

在联邦学习中,随着客户端数量的增加,来自源域的数据被分散到各个客户端之间,从而产生仅限于某些客户端并变得特定的知识。在图 1(a) 中,对于马类,所有客户端的唯一一般事物是形状。然而,某些客户端的某些特定知识具有与目标域更小的特征距离(例如,客户端 2 和目标域之间的马特征距离仅为 70.59)。
动机:同时在局部训练中同时旋转具有不同轻量级组件的特定领域和一般特征,最大限度地减少它们的干扰并删除不相关的细节。
基于此,本文提出两种类型的提示:1)全局提示(G-Prompt)维护所有客户端的域不变表示。它对分散训练中所有客户端带来的域转移是不变的。2)域提示(D-Prompts):受原型学习[34]的启发,本文为每个预定义的源域构造一个原型提示,将每个源域的判别特定知识封装到各自的提示中。此外,当训练和测试期间域标签都未知(即潜在域)时,本文设计了一种自适应查询机制来探索每个样本的潜在域。引入了一个额外的提示(Q-prompt),它在排除语义类别的干扰后,通过图像-文本对齐自动从所有可能的选项中查询每个样本的域标签。最后,在推理时,本文利用协作集成度量从 GPrompt 和 D-Prompts 中提供有价值的补充信息,以实现更好的目标预测。
相关工作部分比较简略,对Domain generation不熟悉的朋友们可以移步一篇综述带你全面了解领域泛化(Domain Generalization)-腾讯云开发者社区-腾讯云
二、方法
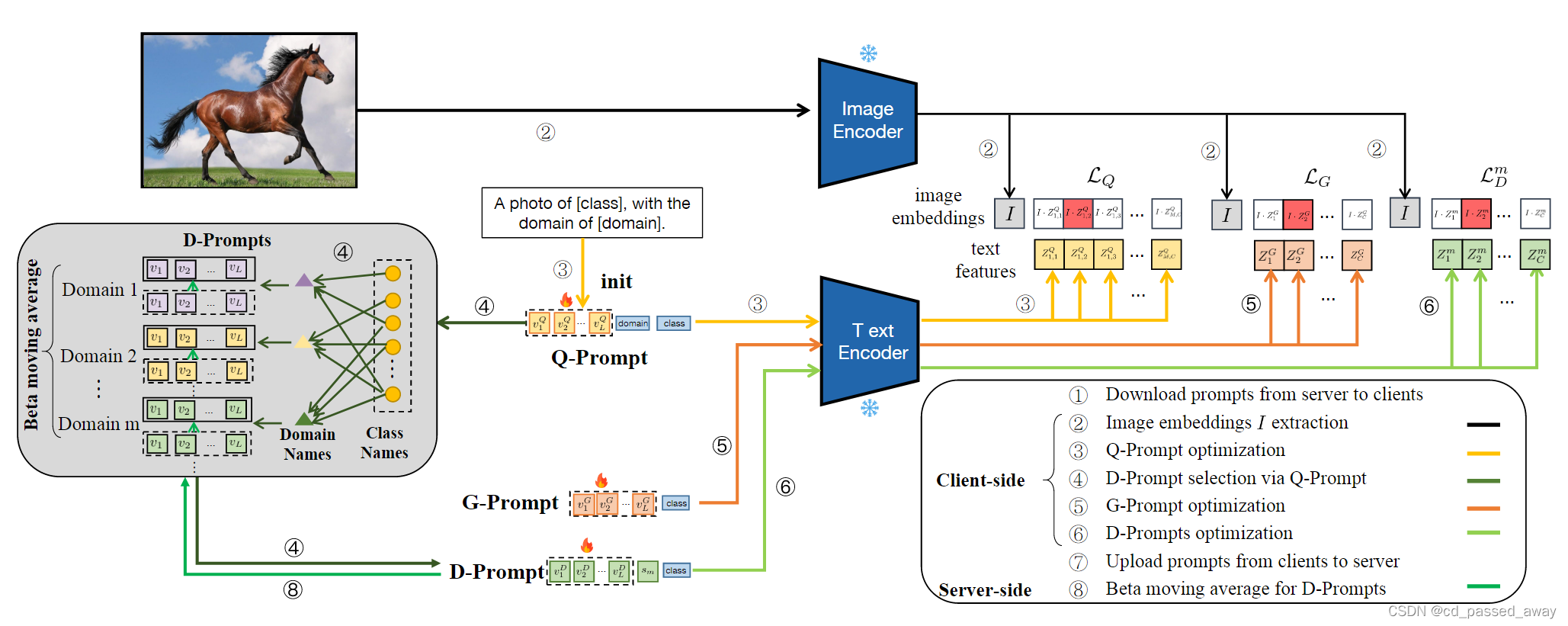
文中解开提示调整 (DiPrompT) 的图示。本文设计了一种替代优化策略来更新两个关键模块(解开提示学习和动态查询方案),它主要包含六个步骤,除了客户端和服务器之间的通信。我们首先分别通过步骤 2 和 3 生成图像嵌入并更新 Q-Prompt。然后在步骤4中使用Q-prompt选择合适的D-Prompt。利用步骤5和步骤6同时优化解缠提示学习中G-Prompt和D-Prompt。最后,我们对D-Prompts进行beta移动平均更新,以避免步骤8中中央服务器中的客户端漂移。
3.1 Global Prompt Tuning (G-Prompt)
捕获所有客户端之间共享的通用特征
本质就是类别交叉熵损失。
3.2 Domain Prompts Tuning (D-Prompts)
捕获特定域(Domain)的原型提示
针对每个类和域设定文本提示嵌入:
标签损失+域的提示对比损失,是手动制作的提示"a photo of a [class] with the domain of <domain >"
由于多个客户端可能持有源自共享域的数据。当 K>M 时,我们设计了一种域聚合策略来聚合来自同一域的知识。它可以表示为来自同一域的这些提示的加权组合:
该操作只聚合这些更新的提示,并过滤那些未更改的提示以确保有效的学习。
尽管从不同域提取的知识多样化,但分别优化每个域的域提示给客户端漂移的风险。受CLIPood[33]中预先训练的视觉语言更新的启发,我们采用beta动量平均机制来更新域提示。
采用联邦平均算法对P-Prompts优化聚合,采用移动平均对D-prompts优化聚合。
3.3 Dynamic Query Scheme (Q-Prompt)
为了有效地学习具有未知域标签的提示,我们设计了一种基于提示调优的动态查询方案,该方案自动为不同的源输入选择合适的域提示。
对输入文本图像对执行类和域相似度匹配:
训练优化Q-prompt(其实是代表域和类别文本提示的MSE损失+代表代表域和类别的输出概率的KL散度损失。):
总优化:
m是Q-prompt的预测域。
3.4 推理
预测过程文本嵌入的构造:
就是每个域计算一个文本提示,加权平均后和全局文本提示相加
四 实验
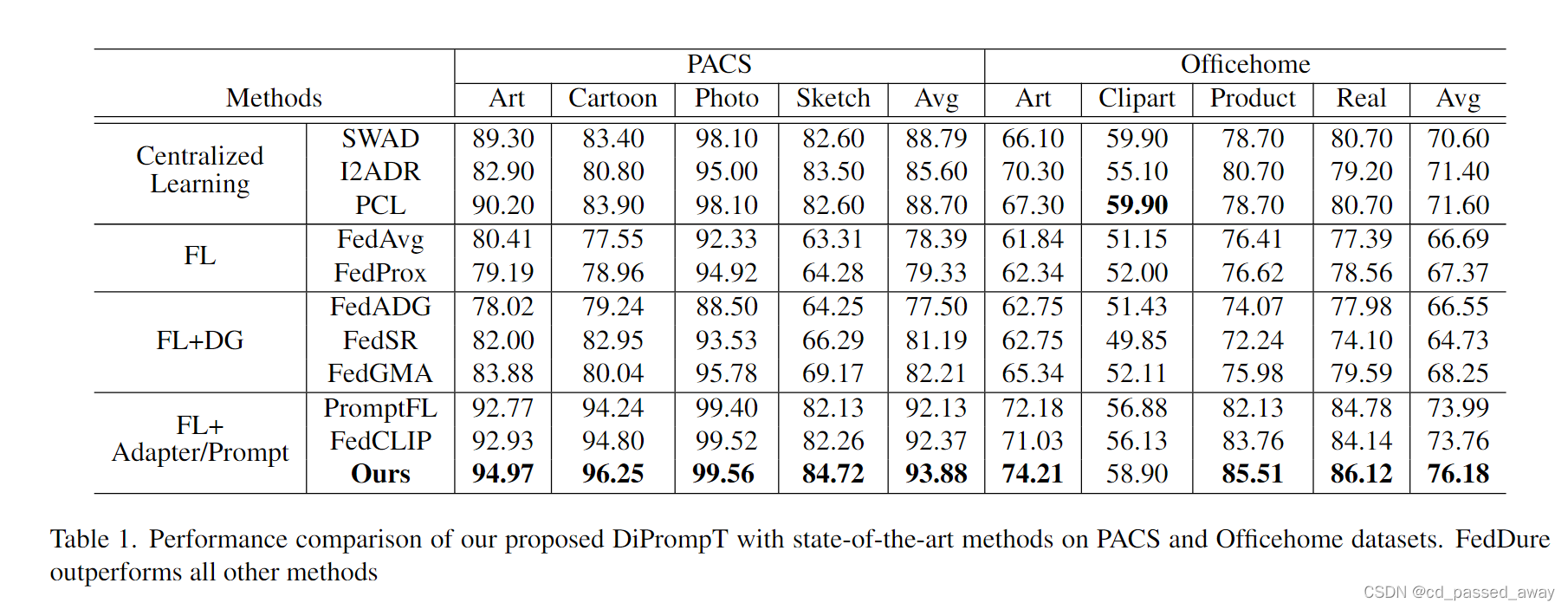

















 3664
3664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









