







小说工具箱的搭建
最近逐渐喜欢上写小说,除了码代码之余,还会出去旅游。
不过有时候在写小说的时候,会遇上不知道怎么给人物起名字。于是动手做了个小工具,顺便发到线上,供各位喜欢写小说的作者们使用。
工具集成网站示例:点击访问
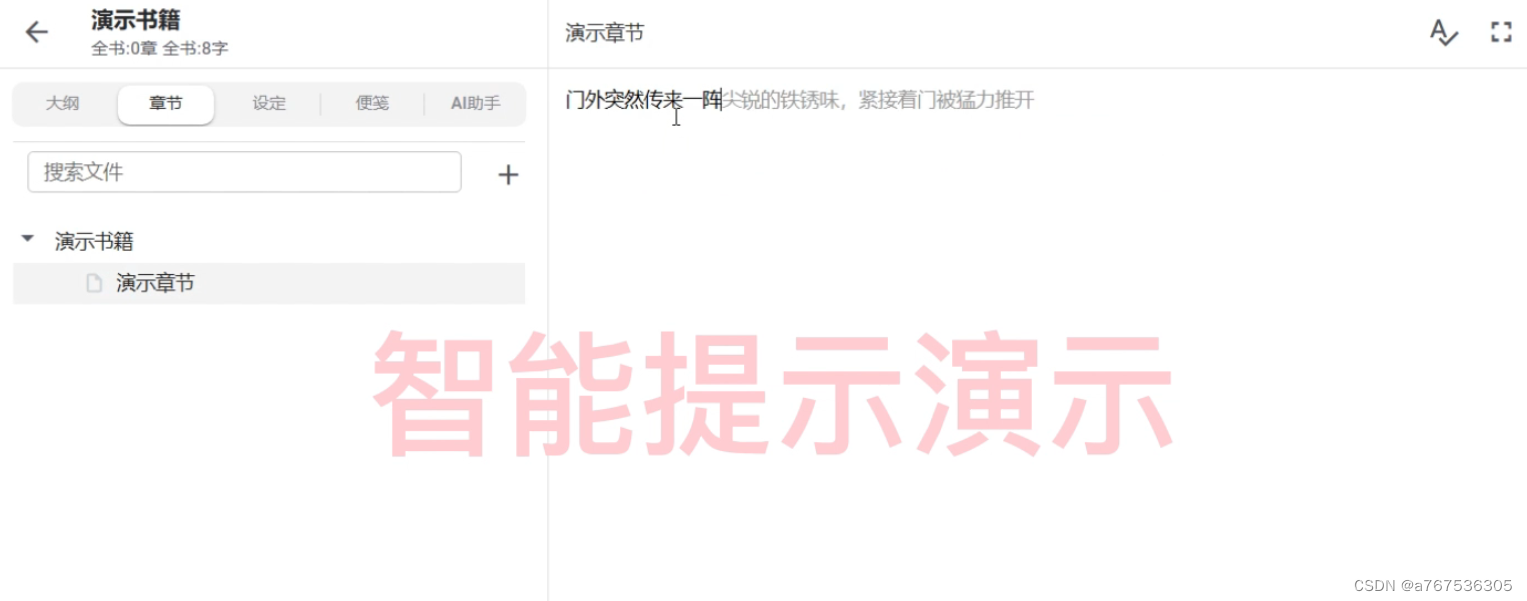
智能提示
在任何地方输入使用TAB键,都能够智能提示:
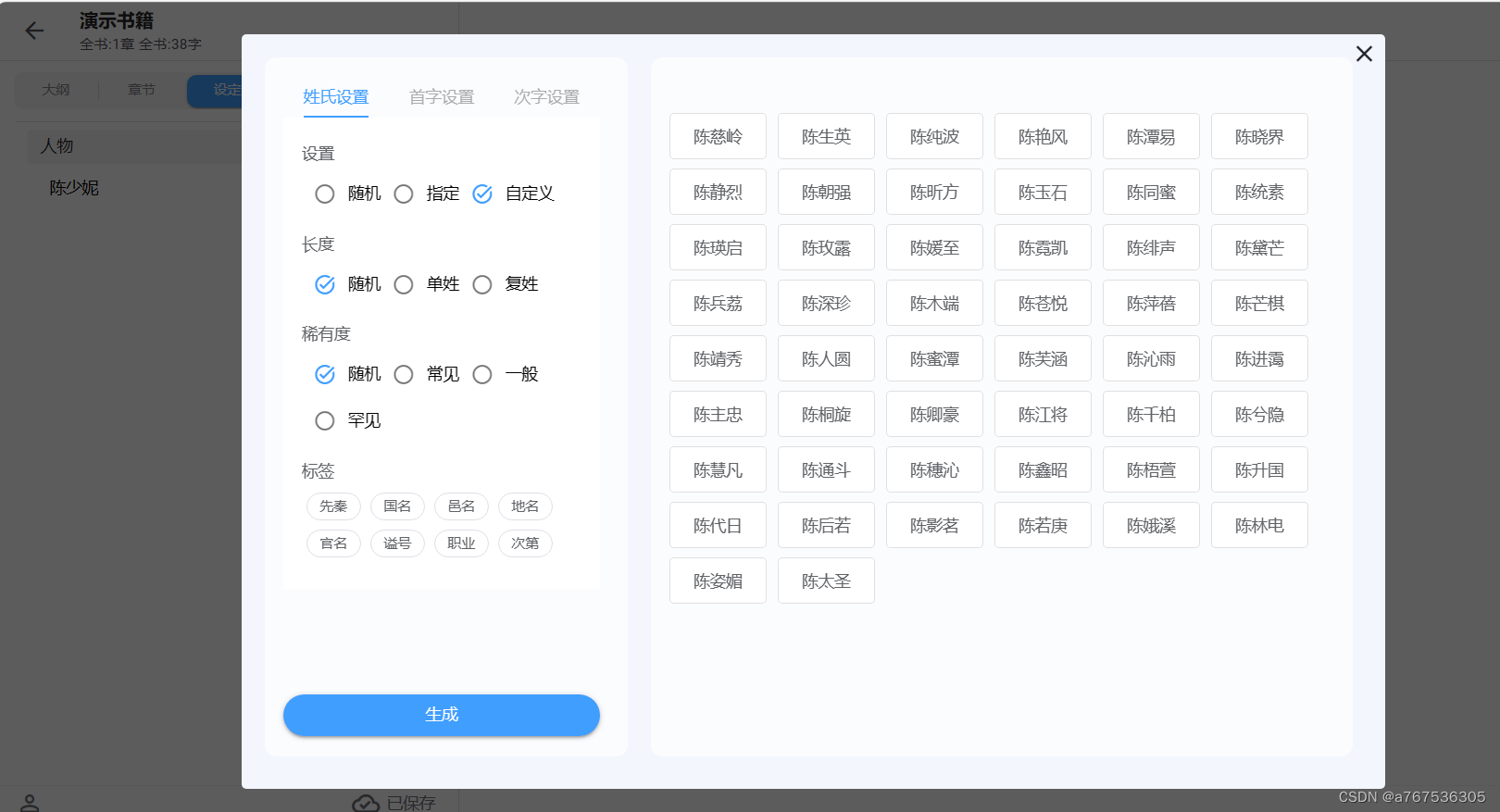
给人物起名字
姓规则:输入单或者复姓
名字规则:可以选择男性、女性或者是中性
参考模型是通过训练普查人物姓名得出的,因此还是比较通顺。
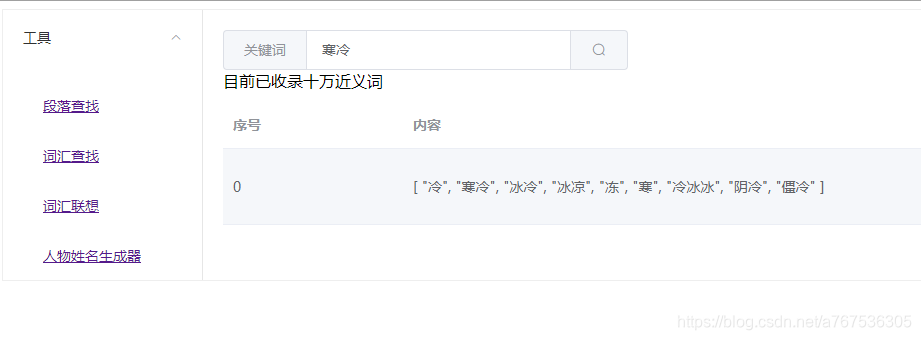
近义词查找
2019/4/1更新:增加近义词查找
最近在写小说过程中,发现有时候需要查找一些近义词来表达,但是经常需要上百度查找,麻烦浪费时间,因此自己写了一个近义词查找的工具,供大家使用。
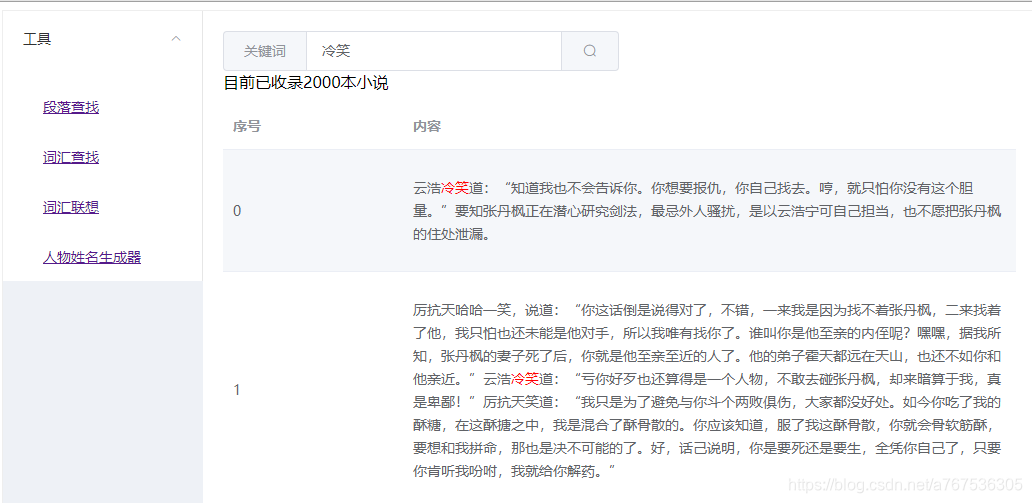
段落查找
2019/5/15更新:增加段落查找
以前我收录的片段都是记在笔记中,现在也写出一个工具出来,方便大家查找。














 4484
4484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









