






数据分类分级,作为数据安全治理的基础和首要工作,重要性无需赘言。今年以来,《数据安全法》、《个人信息保护法》、《网络数据安全管理条例(征求意见稿)》相继出台,国家层面明确提出建立数据分类分级保护制度;金融、工业等行业监管也早已制定相关配套标准规范;上海市、武汉市和浙江省等多地分别发布公共数据开放分级分类试行指南,为落实数据分类分级管理提供指导性参考。
但如何开展、怎样开展数据分类分级工作,对绝大多数单位组织而言,依然是一项很困难的事情。无标准难规范、有标准难落地、已落地难应用,问题众多。
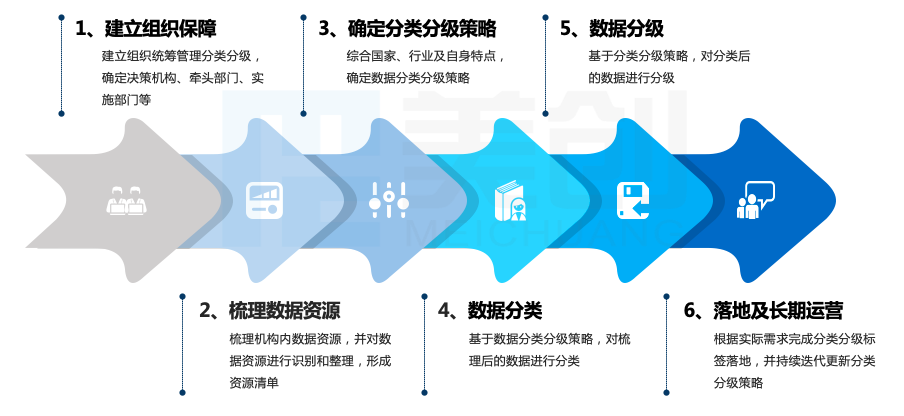
在相关法律法规、国内外标准研究基础上,结合专业咨询服务团队、数据分类分级方法论和成熟工具,形成数据分类分级方案,从走访调研、组织建设、数据梳理、数据分类、数据分级以及最后应用落地,提供完善的、流程化的方法路径。
如今,数据分类分级方案也已先后在大数据局、人社部门、银行等单位机构实践落地,为数据安全精细化管控、数据共享交换、数据价值提升奠定扎实基础。
#人社局
数据分类分级实践
在省人社厅要求“开展数据资产梳理,摸清数据资产家底,强化数据资产常态化管理”通知下,为更好的盘活海量政务数据,支撑政府决策和便民服务、满足合规需求,建设数字人社。按照边试点、边总结、边推广的思路,共同探索形成了可落地、可复制的政务数据分类分级实施路径和模式。
在深入理解客户业务需求基础上,根据“建组织-盘资产-定策略-稳执行”,以 “六步走”方法路径,助力该人社局推进数据分类分级工作:
事前走访调研:
通过走访调研,深入沟通探讨其业务平台数据痛点难点问题,输出调研结论。
建立组织保障:
成立数据资产梳理领导组和工作组,其中:领导组负责统筹和决策职责,确定数据资产梳理工作目标、内容、范围、标准规范等;工作组负责按照工作目标和要求开展数据资产梳理工作,协调人员和解决问题,并牵头进行工作效果评价。
![]()
数据资源盘点:
项目组对接局内相关资产部门,开展数据资源盘点工作,形成统一基础数据资源列表,内容包括但不限于所属部门、所在系统、数据类型、安全等级、内容描述、数据量、保存位置、保存期限、数据处理情况、数据对外提供情况、数据生命周期各环节安全措施配套情况等。
数据分类分级策略制定
数据分类
目前,公共数据分类维度主要有以下四类:数据管理、业务应用、数据安全和数据对象。综合考虑国家、地方、行业法律法规和自身数据分类的目的,确定从数据对象维度对人社数据分类。

分类共形成7个一级分类,包括:个人信息、业务信息、组织机构信息、客体信息、系统数据、基础类型、统计信息。其中业务信息分类下包括人社8个业务主题分类,分别为:社会保险、人才管理、智慧就业、职称申请与认定、职业能力建设、网签劳动合同、智慧监察、行政管理,以及45个二级子类的数据资产。
数据分级
人社数据分级与其共享、开放的类型、范围、审批和管理要求直接相关,要考虑数据聚合情况、数据体量、数据时效性、数据脱敏处理等因素,根据实际升高或降低数据安全级别。同时兼顾人社数据在遭到破坏后对国家安全、社会秩序、公共利益以及对公民、法人和其他组织的合法权益(受侵害客体)的危害程度。
基于综合考量,按照就高从严原则确定安全等级,将人社数据分为1级、2级、3 级、4级,并根据就高原则进行定级(数据集的级别根据下属数据项的最高级来定级)。根据各级别的公共数据特征,帮助客户进一步梳理了安全控制点,提出分类分级的安全管控规则。
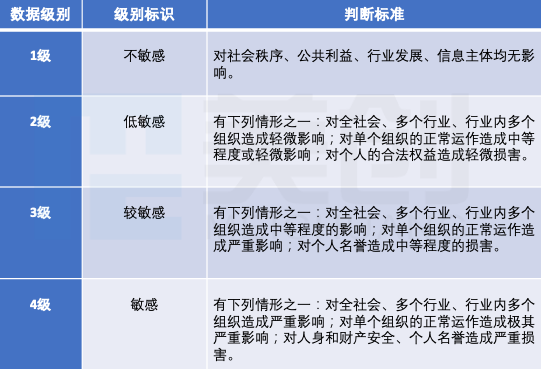
表:数据级别与判断标准
因人社数据均可共享,因此无4级数据,最终将原先数据级别为4级的数据调整为3级。将业务信息从3级调整为2级。本次分级将数据分为3级,分别为:1级(非敏感)、2级(低敏感)、3级(较敏感)。
落地及运营工具
基于自研的暗数据发现和分类分级平台,集合自动扫库扫表、模型匹配、数据统计、机器学习等技术,进行数据发现、数据含义识别、业务类型确认、数据分类分级、多维结果输出,以提升数据发现和分类分级的准确性和规范性,缩短项目周期。同时,暗数据发现与分类分级平台动态拓展能力,可持续迭代更新分类分级策略,为长期持续运营提供支持。
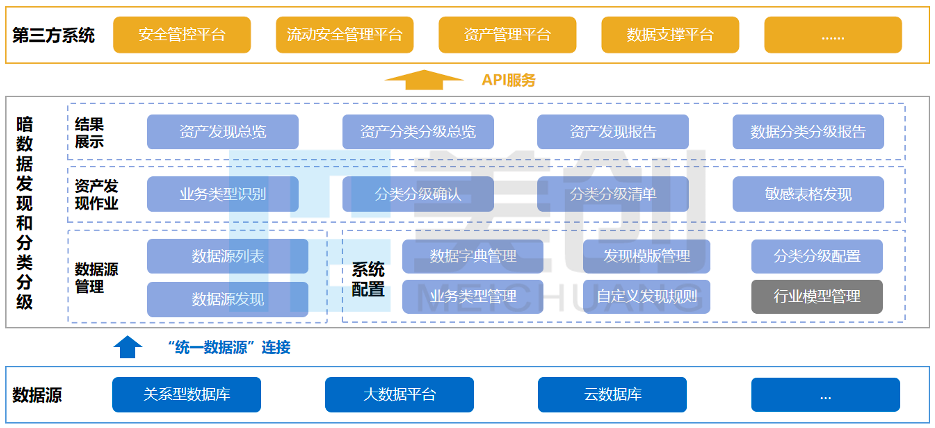
暗数据发现与分类分级平台产品架构
#大数据局
数据分类分级实践
结合《公共数据分类分级指南》、《人口综合库数据规范》、《信息安全技术 个人信息安全规范》等规范,对某市大数据局人口综合库进行梳理和分类分级。
该大数据局数据分类分级实施过程从规划到落地,包括准备工作、数据资产盘点与分类分级咨询、实施落地,以“服务+产品”的方式配合完成:

暗数据发现与分类分级落地流程
分类分级标准梳理
结合《公共数据分类分级指南》、《人口综合库数据规范》、《信息安全技术 个人信息安全规范》等规范,对市大数据局的人口库进行梳理,形成《市大数据局数据分类分级参考规范》,并将标准内置到分类分级工具中。
资产发现
通过暗数据发现产品提前配置人口库分类分级及发现模版,自动进行数据源扫描、识别,发现数据库的数量、IP、端口、类型等信息;自动完成数据格式、内容识别,数据含义解析,自动输出分类分级结果。项目组根据咨询结果形成的分类分级大纲确认和补充分类分级结果,补充发现规则。
数据分类分级
在业务类型识别的基础上完成对人口库数据的分类分级,通过工具进行标签管理,并生成可视化的分类分级报告,资产发现和分类分级的结果通过标准接口的方式,提供给安全产品和大数据局其他数据资源管理平台,完成对数据资产的安全访问和高效管理。
最终完成:
-
对人口库形成11个二级分类、50个三级分类,5个敏感等级(极敏感、敏感、较敏感、低敏感、不敏感)。
-
梳理人口综合库30多个schema,近1000张数据表,25000个左右的字段。
-
敏感数据发现超40%的数据表中都有敏感字段。可按照不同分级对敏感数据和敏感表格进行安全管控。
#某银行
数据分类分级实践
2020年9月中国人民银行发布《金融数据安全 数据安全分级指南》,要求各个金融机构对数据实施分类分级管理,加强数据安全管理,促进数据安全共享。合规需求和业务发展共同驱动下,该银行通过暗数据发现和分类分级平台完成51张表格,2409个字段分类分级工作。
暗数据发现和分类分级平台已内置金融行业分类分级标准(参照《JR/T 0197-2020金融数据安全 数据安全分级指南》),在综合该银行合规及安全需求下,通过工具实现业务系统的梳理和识别、发现敏感字段,建立分类分级管理。

-
初次扫描发现:通过“暗数据发现和分类分级”工具,自动对数据进行智能扫描分析,确定数据业务类型,进行分类分级;
-
发现结果确认:系统展示发现结果,辅助人工对发现结果进行确认,重点对未识别出的业务类型字段、业务类型识别错误的内容进行人工判断;
-
新增业务类型:新增未内置的业务类型,根据数据的特征(数据内容、字段名称、字段注释)进行发现规则的设计,并绑定分类分级;
-
发现规则优化:对于业务类型识别错误的字段,根据数据特征进行规则内容、规则优先级、规则权重的优化;
-
再次扫描发现:再次启动暗数据发现和分类工具的自动扫描程序,根据最新规则对数据重新进行智能匹配和分类分级工作;同时,工具支持对两次发现结果进行对比,清晰展现最新发现结果的执行效果。
在此次分类分级项目中,通过产品直接进行数据分类分级工作,凭借高自动化能力,以及根据实际情况对分类分级策略进行不断优化,大大减少人工投入工作量,提高工作效率。根据识别结果形成可视化的数据资产清单,并输出分类分级报告,为不同资产和场景试行安全防护策略,满足数据应用需求提供有力支撑。
“数据驱动”已成为新的全球大趋势,明确数据保护对象,并对数据实施分级管理,将有助于组织单位合理分配数据保护资源和成本,是组织单位建立全生命周期数据保护框架的基础,也是有的放矢地实施数据安全管理的前提条件。同时,统一的数据分级管理制度,能够促进数据在机构间、行业间的安全共享,有利于数据价值的挖掘与实现。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









