







目录
0、数据集介绍
数据集来源:UCI
UCI Machine Learning Repository: Car Evaluation Data Set
-
Title: Car Evaluation Database
-
Sources:
(a) Creator: Marko Bohanec
(b) Donors: Marko Bohanec (marko.bohanec@ijs.si)
Blaz Zupan (blaz.zupan@ijs.si)
(c) Date: June, 1997 -
Number of Instances: 1728
-
Attribute Values:
buying v-high, high, med, low
maint v-high, high, med, low
doors 2, 3, 4, 5-more
persons 2, 4, more
lug_boot small, med, big
safety low, med, high -
Missing Attribute Values: none
-
Class Distribution (number of instances per class)
unacc 1210 (70.023 %)
acc 384 (22.222 %)
good 69 ( 3.993 %)
v-good 65 ( 3.762 %)
1、导入必要的包
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import pandas as pd2、读入数据
读入数据,并为每个特征命名。
car_data=pd.read_csv("d:/datasets/car_evaluation.csv",names=["buying","maint","doors","person","lug_boot","safety","car_acc"])3、数据探索
car_data.head()
car_data.tail()
car_data.describe()
car_data.info()
#查看特征与标签的取值
for i in car_data.columns:
print(car_data[i].value_counts())4、数据预处理
标签编码(map方法)。
car_data.car_acc=car_data.car_acc.map({"unacc":1,"acc":0,"good":0,"vgood":0})特征编码get_dummies())
car_data_=pd.get_dummies(car_data[["lug_boot","safety","buying","maint","doors","person"]])5、训练集、测试集划分
train_x,test_x,train_y,test_y=train_test_split(car_data_,car_data.car_acc,test_size=0.3,random_state=10)6、建立模型
6.1逻辑回归
建立模型、训练、预测
lr=LogisticRegression()
lr.fit(train_x,train_y)
y_pre=lr.predict(test_x)
评价
print(classification_report(y_pre,test_y)) #输出分类报告
print(lr.coef_) #输出回归系数
lr.score(test_x,test_y) #输出正确率
from sklearn.metrics import accuracy_score
accuracy_score(y_pre,test_y) #输出正确率
from sklearn.metrics import confusion_matrix
import seaborn as sns
sns.set(font="SimHei")
lgr=LogisticRegression(random_state=1)
lgr.fit(X_train,Y_train)
y_pre=lgr.predict(x_test)
print(lgr.score(x_test,y_test))
ax=sns.heatmap(confusion_matrix(y_test,y_pre),annot=True,fmt="d",xticklabels=["满意","不满意"],yticklabels=["满意","不满意"])
ax.set_ylabel("真实")
ax.set_xlabel("预测")
ax.set_title("混淆矩阵")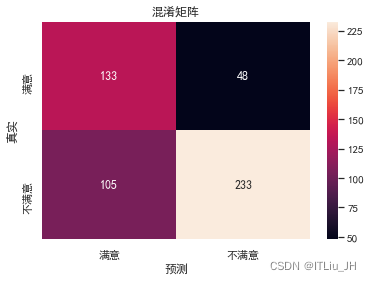
6.2 K近邻
建立模型、训练、预测
from sklearn.neighbors import KNeighborsClassifier
kn=KNeighborsClassifier()
kn.fit(X_train,Y_train)
y_pre=kn.predict(x_test)评价
print(kn.score(x_test,y_test))
print(classification_report(y_test,y_pre))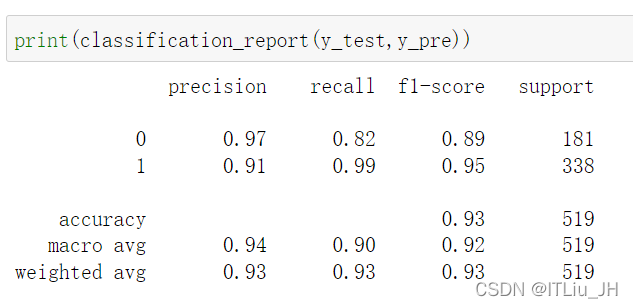
ax=sns.heatmap(confusion_matrix(y_test,y_pre),annot=True,fmt="d",xticklabels=["满意","不满意"],yticklabels=["满意","不满意"])
ax.set_ylabel("真实")
ax.set_xlabel("预测")
ax.set_title("混淆矩阵")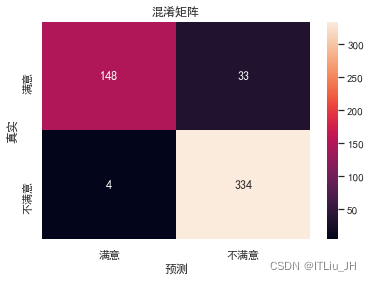
调参(不同邻居数量对模型的效果的影响)
k_score=[KNeighborsClassifier(n_neighbors=k).fit(X_train,Y_train).score(x_test,y_test) for k in range(1,10)]import matplotlib.pyplot as plt
plt.plot(range(1,10),k_score,"b")
plt.xlabel("k")
plt.ylabel("正确率")
plt.title("k值对正确率的影响")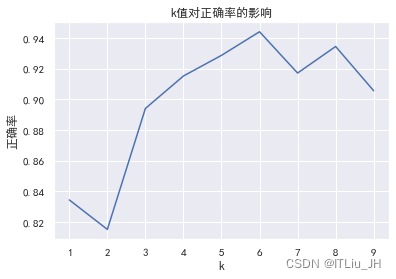
6.3 决策树
建立模型、训练、预测
from sklearn.tree import DecisionTreeClassifier
dt=DecisionTreeClassifier(max_depth=3) #深度较小,为方便可视化
dt.fit(train_x,train_y)
dt_pre=dt.predict(test_x)
评价
dt.score(test_x,test_y)
print(classification_report(dt_pre,test_y))可视化决策树
前提:已安装graphviz
安装graphviz过程:
- 下载graphviz,选择与操作系统对应的版本 Download | Graphviz
- 安装graphviz
- 修改环境变量(将dot.exe文件的路径加到用户或系统环境变量的path中,一般是:C:\Program Files\Graphviz\bin)
- 安装graphviz python包:pip install graphviz
- 重启 jupyter
from sklearn.tree import export_graphviz
from six import StringIO
from IPython.display import Image
import pydotplus
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus']=False #正常显示负号“-”
## 输出图片到dot文件
export_graphviz(dt, out_file='tree.dot',
feature_names=train_x.columns,
rounded=True, filled=True,
class_names=['acc', 'unacc'])
## 使用dot文件构造图
graph= pydotplus.graph_from_dot_file('tree.dot')
Image(graph.create_png())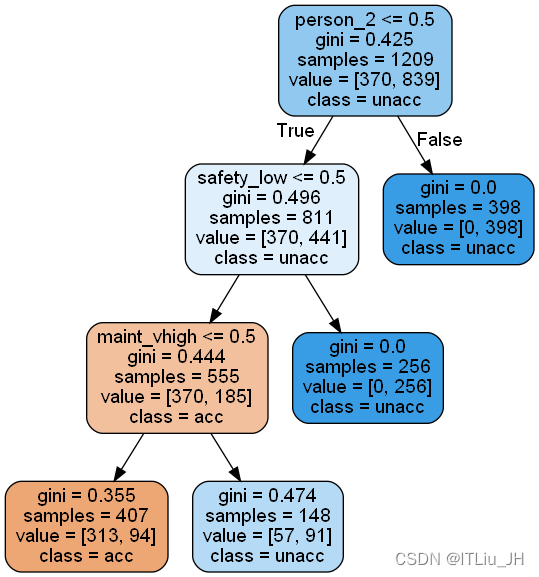
6.4 朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BernoulliNB
from sklearn.naive_bayes import MultinomialNBGNB=GaussianNB()
GNB.fit(train_x,train_y)
y_pred=GNB.predict(test_x)
GNB.score(test_x,test_y)
print(classification_report(test_y,y_pred))pd.DataFrame(GNB.theta_.T,index=test_x.columns).rename(columns={0:"0类",1:"1类"}).plot(kind="bar",rot=60,figsize=(12,5))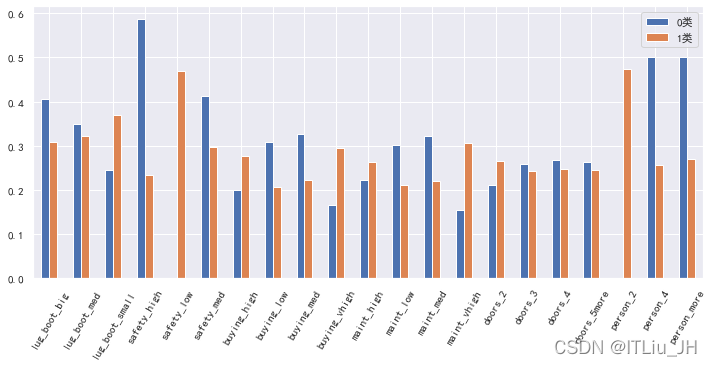
BNB=BernoulliNB()
BNB.fit(train_x,train_y)
y_pred=BNB.predict(test_x)
BNB.score(test_x,test_y)
print(classification_report(test_y,y_pred))MNB=MultinomialNB()
MNB.fit(train_x,train_y)
y_pred=MNB.predict(test_x)
MNB.score(test_x,test_y)
print(classification_report(test_y,y_pred))6.5 SVC
from sklearn.svm import SVC
from sklearn.svm import LinearSVCSVC_=SVC()
SVC_.fit(train_x,train_y)
y_pred=SVC_.predict(test_x)
SVC_.score(test_x,test_y)
print(classification_report(test_y,y_pred))LSVC_=LinearSVC()
LSVC_.fit(train_x,train_y)
y_pred=LSVC_.predict(test_x)
LSVC_.score(test_x,test_y)
print(classification_report(test_y,y_pred))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











