






【目标】
获取某个csdn博客所有粉丝的名称
【实现方法】
打开本人博客,发现粉丝有关数据网址为:
https://blog.csdn.net/cdl3?type=sub&subType=fans
有两种实现方法:
1.模拟滚动鼠标,直至所有页面数据加载完成。
用scrollBy一直下拉滚动条,然后scrollTop会一直变化,当scrollTop不变时,说明就到底了。跳出循环即可。
示范代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import datetime
def cnt_time(func):
import time
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
result = end_time - start_time
print('函数%s执行了 %.3fs' % (func.__name__, result))
return res
return inner
@cnt_time
def scroll_until_end(driver, interval=0.5):
# 定义一个初始值
temp_height = 0
while True:
# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")
# sleep一下让滚动条反应一下
time.sleep(interval)
# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script(
"return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
# 如果两者相等说明到底了
if check_height == temp_height:
break
temp_height = check_height
# print(check_height)
return True
def get_csdn_browser(headless=True):
chrome_options = Options()
if headless:
chrome_options.add_argument("--headless") # 无头chrome
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument("--disable-dev-shm-usage")
# 不加载图片设置,提升速度:
chrome_options.add_argument('blink-settings=imagesEnabled=false')
chrome_options.set_capability("pageLoadStrategy", "none") # normal eager none 默认normal
browser1 = webdriver.Chrome(options=chrome_options, service=Service('./chromedriver.exe'))
print('启动chrome driver成功')
return browser1
def get_csdn_guanzhu_list(driver, blog_url):
driver.get(blog_url)
driver.maximize_window()
time.sleep(2)
# 滚动鼠标,直至无法滚动
# https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize=20&username=cdl3
scroll_until_end(driver)
people_list = driver.find_elements(By.XPATH, '//div[@class="sub-people-username"]')
guanzhu_list = []
for i in people_list:
guanzhu_list.append(i.text)
if len(guanzhu_list) > 0:
return guanzhu_list
return None
if __name__ == '__main__':
browser = get_csdn_browser(headless=False)
url = 'https://blog.csdn.net/cdl3?type=sub&subType=fans'
print('-----方法1:selenium滚动鼠标直至获取所有数据')
alist = get_csdn_guanzhu_list(browser, url)
print(len(alist))
print(alist)
实现效果如下图所示:以本人博客为例,有231位粉丝,翻页耗时13秒左右。

2.调用api接口快速获取。
经查看当期页面,发现调用接口为:
https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize=20&username=cdl3&fanId=1998601
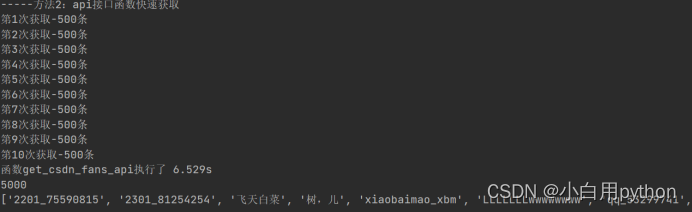
注意,为了防止获取时间太长,代码中限定了最大查询次数,每次最多500条。5000条数据大约需要6.5秒钟(因为需要多次循环获取)。
示范代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import datetime
def cnt_time(func):
import time
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
result = end_time - start_time
print('函数%s执行了 %.3fs' % (func.__name__, result))
return res
return inner
@cnt_time
def get_csdn_fans_api(csdn_username, page_size=500, max_cishu=10):
# csdn page_size最大值为500,超过仍然是500
#最大次数默认是10次,即最大获取5000粉丝数据(约需6.5秒钟),否则数据量太大,时间太长。
#抓取 https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize=20&username=cdl3&fanId=1998601
import requests
fanUrl = f"https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize={page_size}&username={csdn_username}&fanId="
# 发送Post请求
headers = {"User-Agent": ""}
response = requests.get(fanUrl, headers=headers)
# 如果请求成功,接收的响应会是一个Response对象
result = []
fan_id = ''
k = 1
print(f'第{k}次获取-{page_size}条')
if response.status_code == 200:
# 使用json()方法将响应内容解析为JSON
data = response.json()
blist = data['data']['list']
blist1 = [x['nickname'] for x in blist]
result.extend(blist1)
fan_id = data['data']['fanId']
while True:
if fan_id:
fanUrl = f"https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize={page_size}&username={csdn_username}&fanId={fan_id}"
response = requests.get(fanUrl, headers=headers)
k += 1
print(f'第{k}次获取-{page_size}条')
data = response.json()
blist = data['data']['list']
blist1 = [x['nickname'] for x in blist]
result.extend(blist1)
if k >= max_cishu:
break
fan_id = data['data']['fanId']
else:
break
else:
print("请求失败,状态码:", response.status_code)
return None
if len(result) > 0:
return result
else:
return None
if __name__ == '__main__':
print('-----方法2:api接口函数快速获取')
# clist = get_csdn_fans_api('cdl3')
#https://blog.csdn.net/zhongguomao?type=blog
clist = get_csdn_fans_api('zhongguomao')
print(len(clist))
print(clist)
选择一个较多粉丝主页,如 https://blog.csdn.net/zhongguomao?type=blog
执行效果如图:
【发文章不易,请多多关注、点赞、留言支持!谢谢!】















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









