






 文章介绍了时序数据库的概念,重点讲解了InfluxDB的特性、TICK架构、数据存储原理,并提供了InfluxDB的安装及使用示例,包括Telegraf数据收集和Jmeter性能监控的集成。此外,还展示了Flux在Python中的查询和数据插入操作。
文章介绍了时序数据库的概念,重点讲解了InfluxDB的特性、TICK架构、数据存储原理,并提供了InfluxDB的安装及使用示例,包括Telegraf数据收集和Jmeter性能监控的集成。此外,还展示了Flux在Python中的查询和数据插入操作。
什么是时序数据库
时序数据库,全称时间序列数据库(Time Series Database,TSDB),用于存储大量基于时间的数据,时序数据(Time Series Data)指的是一系列基于时间的数据,例如CPU利用率,北京的房价变化趋势,某一地区的温度变化等。
时序数据库支持时序数据的快速写入、持久化,多维度查询、聚合等操作,同时可以记录所有的历史数据,查询时将时间作为数据的过滤条件。
时序数据的使用场景广泛,包括DevOps监控,应用程序指标,IoT传感器数据,实时动态数据分析等场景。
1
初识InfluxDB
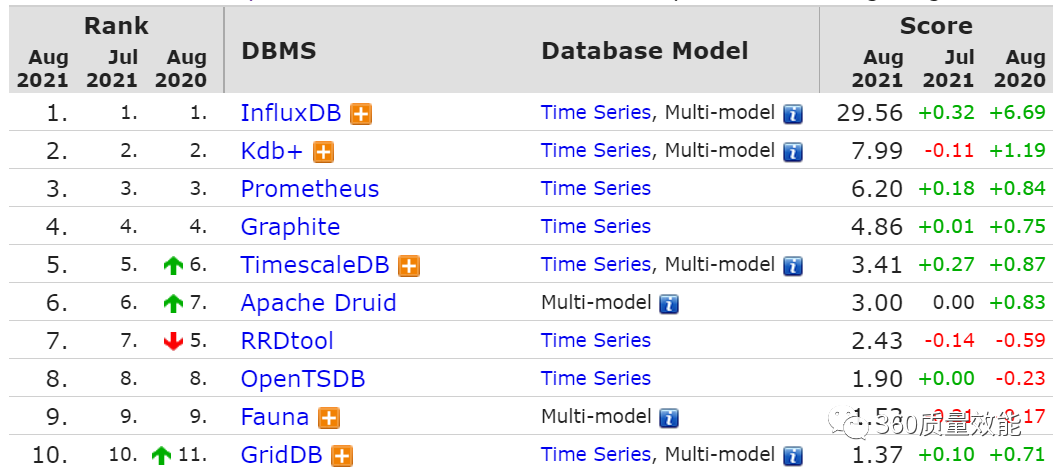
InfluxDB是时序数据库中应用比较广泛的一种,在DB-Engines TSDB rank中位居首位,可见InfluxDB在互联网的受欢迎程度是非常高的。下图是截止到2021年8月时序数据库的排名情况。
它是go语言开发的数据库,InfluxDB自发布至今,已经有两个版本,InfluxDB1.x系列提供一种类似SQL的查询语言InfluxQL,用于数据交互。2019年1月新推出的influxDB2.0 alpha版本,主推全新的查询语言Flux,支持TICK架构。在 2020 年底推出InfluxDB 2.0 正式版本,该版本又分为InfluxDB Cloud 和 InfluxDB OSS两个系列。
时序数据库与我们熟悉的关系型数据库有所不同,首先需要了解一下InfluxDB中字段的含义,如下图所示:
2
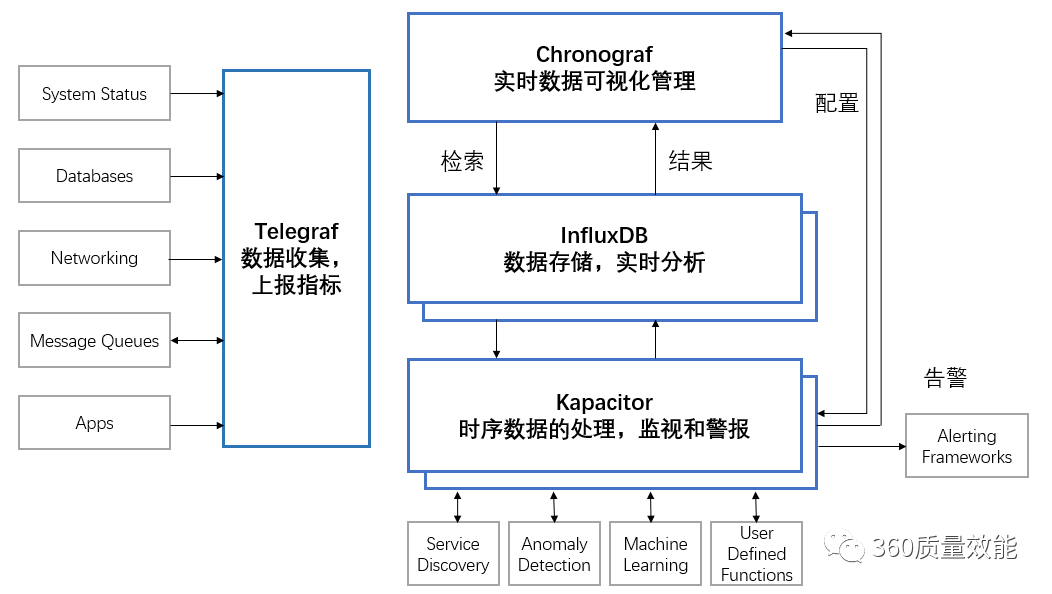
TICK架构分析与各组件功能介绍
TICK架构 是 InfluxData 平台的组件的集合首字母缩写,该集合包括Telegraf、InfluxDB、Chronograf和 Kapacitor。TICK架构以及各组件分工情况如图所示:
除了上图可视化管理工具Chronograf外,还有一种可视化工具Grafana,它也是用于大规模指标数据的可视化展示,提供包括折线图,饼图,仪表盘等多种监控数据可视化UI,若应用过程中考虑到扩展性问题,也会使用Grafana代替Chronograf。
3
InfluxDB的特点
● 数据写入:
①. 高并发高吞吐,可持续的数据写入。
②. 写多读少,时序数据95%以上都是写操作,例如在监控系统数据的时候,监控数据特别多,但是通常只会关注几个关键指标。
③. 数据实时写入,不支持数据更新,但是可以人为更新修改。
● 数据分析与查询:
①. 数据查询是按照时间段读取,例如1小时,1分钟,给出具体时间范围。
②. 最近的数据读取率高,越旧的数据读取率越低。
③. 多种精度查询和多种维度分析。
● 数据存储:
①. 存储数据规模大的数据,监控数据的数据大多数情况下都是TB或者PB级。
②. 数据存放具有时效性,InfluxDB提供了保存策略,可以认为是数据的保质期,超过周期范围,就可以认为数据失效,需要回收。节约存储成本,清理低价值的数据。
4
InfluxDB存储原理
InfluxDB的存储结构树是时间结构合并树(Time-Structured Merge Tree,TSM),它是由日志结构化合并树(Log-Structured Merge Tree,LSM),根据实际需求变化而来的。
**①. LSM树 **
LSM树包含三部分:Memtable,Immutable和SSTable。MemTable是内存中的数据结构,用于保存最近产生的数据,并按照Key有序地组织数据。内存并不是可靠存储,若断电就会丢失数据,因此通常会使用预写式日志(Write-ahead logging,WAL)的方式来保证数据的可靠性。
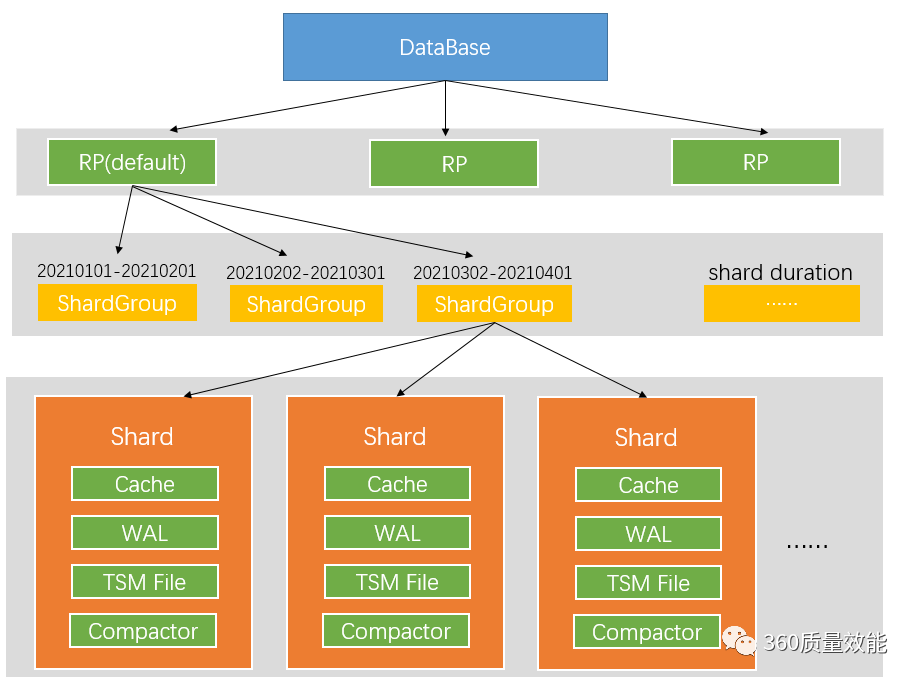
②. TSM存储引擎
TSM存储引擎主要包括四部分:Cache,WAL,TSM File,Compactor。下图中shard与TSM引擎主要部分放在一起,但其实shard在是TSM存储引擎之上的一个概念。在 InfluxDB 中按照数据产生的时间范围,会创建不同的shard分组,每个 shard 都有本身的 cache、wal、tsm file 以及 compactor。
InfluxDB 2.0应用实践
准备工作
安装虚拟机,创建Ubuntu环境,安装Jmeter5.4版本。
1. 安装influxdb2.0
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.7-amd64.deb
sudo dpkg -i influxdb2-2.0.7-amd64.deb
③. 启动influxdb服务
sudo service influxdb start
④. 关闭influxdb服务
sudo service influxdb stop
sudo service influxdb status
⑥. 卸载influxdb
sudo dbkg –r influxdb2
2. 安装telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.19.0~rc1-1_amd64.deb
②. 安装telegraf
sudo dpkg -i telegraf_1.19.0~rc1-1_amd64.deb
③. 启动telegraf
systemctl start telegraf
systemctl status telegraf
应用实践
1. Telegraf+InfluxDB2.x系统可视化监控
Influxdb2.0 已经集成了图形界面,简单的可视化监控可以无需使用 Grafana,本文例子暂时没有使用Grafana。
①. 访问influxdb2
首先在终端键入启动influxdb服务的指令,然后在虚拟机的火狐浏览器地址栏输入 http://localhost:8086 2,点击回车键进入influxDB浏览器访问首页。首次登录会设置用户名,密码,点击sign in完成登录。
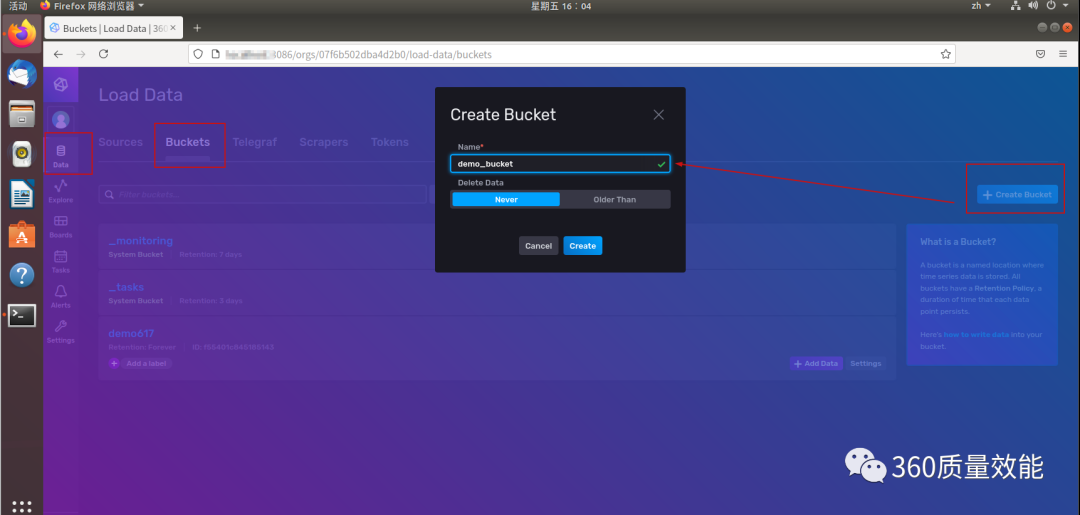
②. 创建bucket,存储数据
依次点击 Data → Bucket → Create Bucket,在弹框中输入bucket名字,然后点击创建,完成bucket的创建,此处创建了一个name为demo_bucket的 bucket。
③. 创建一个telegraf收集数据
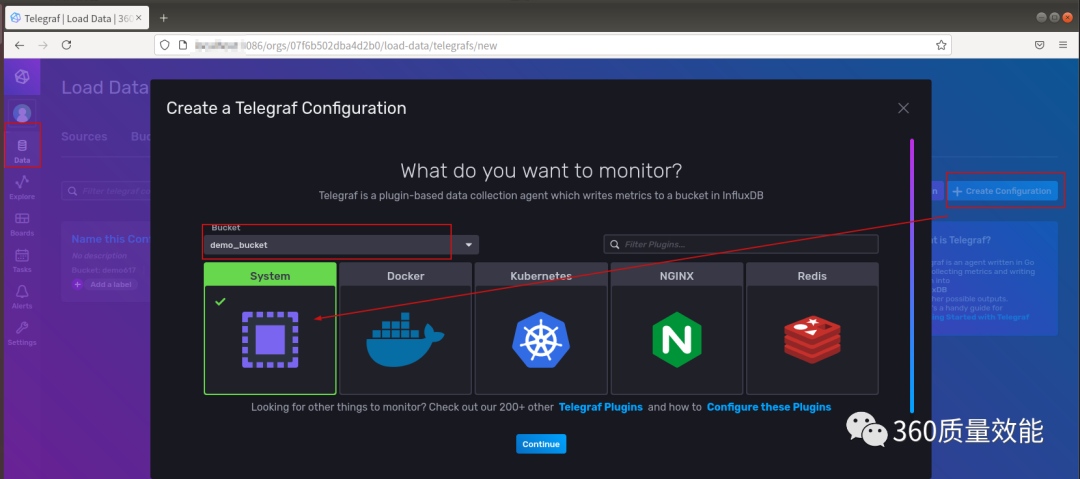
依次点击Data → Telegraf → Create Configuration → continue。在Bucket选择刚才创建的 “demo_bucket“ ,监控目标选择系统System,然后点击continue。
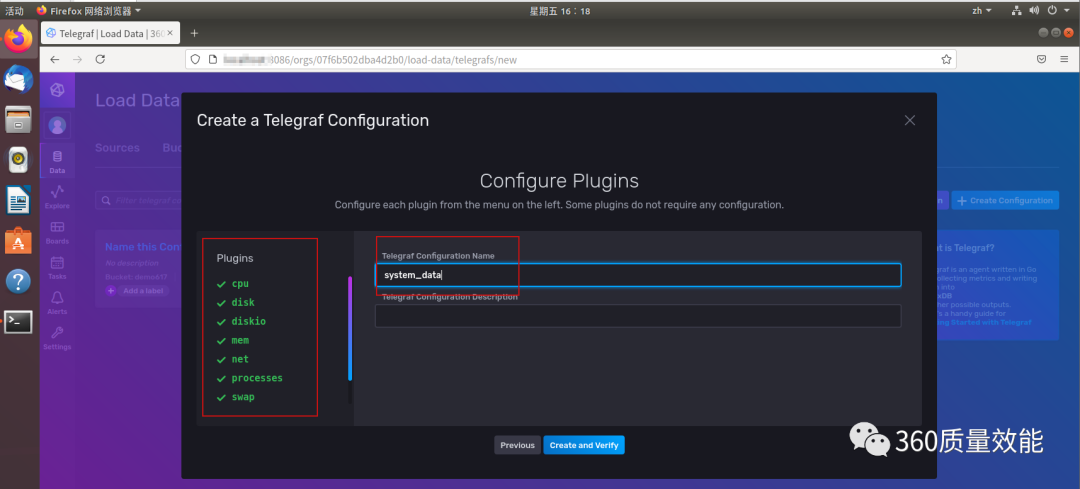
点击 continue 之后,可以知道要系统数据包括哪些,Telegraf Configuration name需要填充,此处填写为system_data,然后点击create and verity,完成这一操作。
④. 使用Telegraf搜集数据
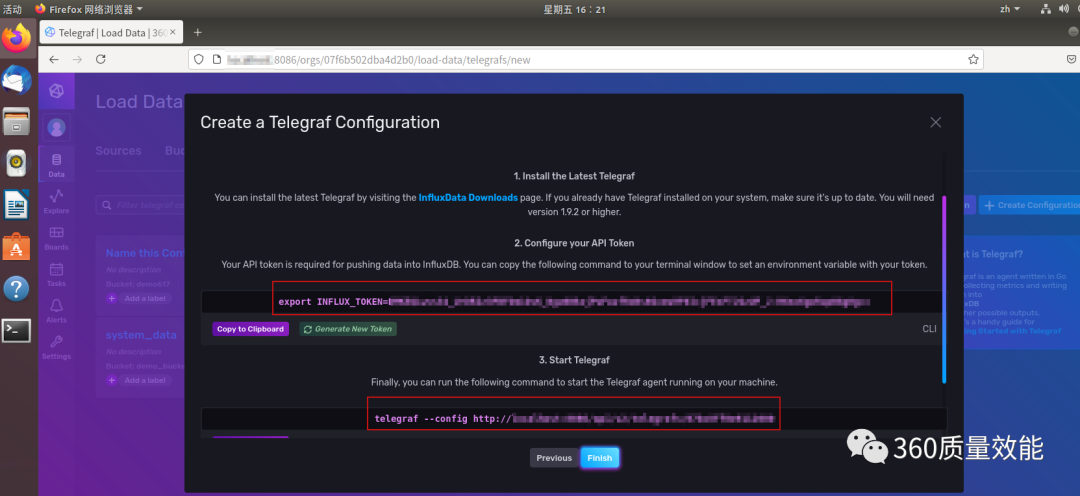
点击 create and verity 之后,并不能马上实现数据搜集,需要在当前页面获取API Token和Telegraf的启动指令,依次复制,并在终端执行指令。
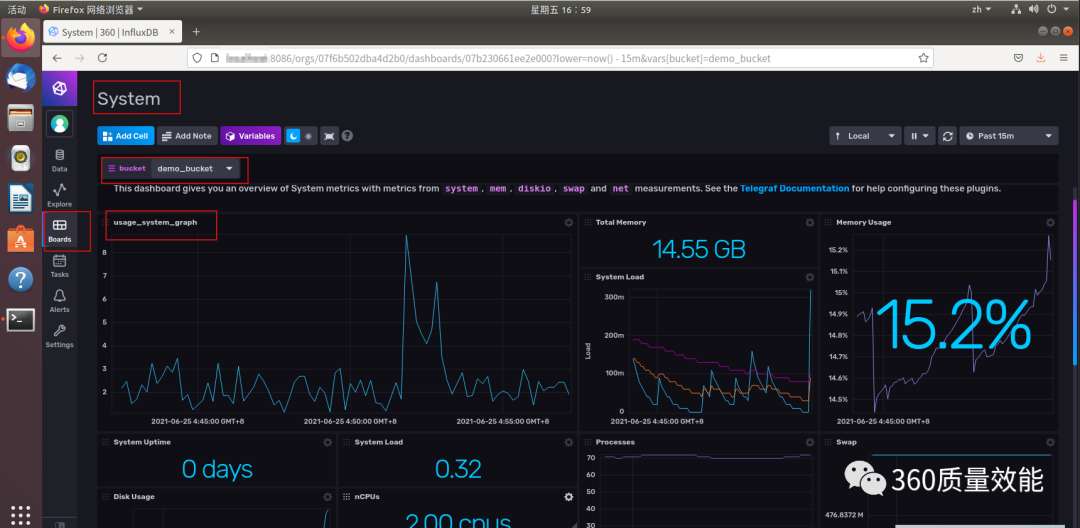
⑤. 系统数据可视化呈现与保存
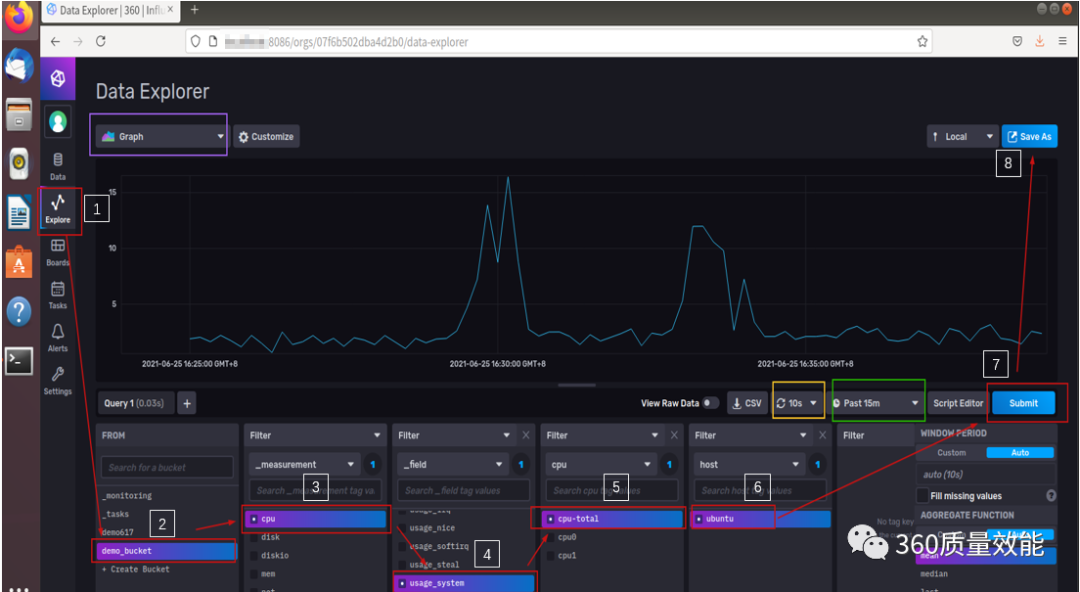
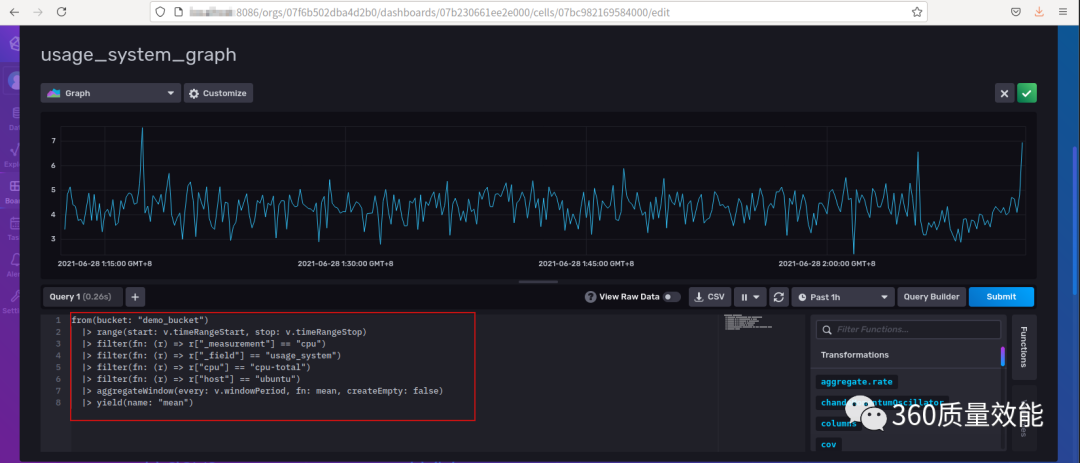
点击Export,在From这里选择刚才创建的bucket:demo_bucket,在第一个filter那里会在选择bucket之后,默认出现_measurement,选择cpu,相当于关系型数据库中的表,在第2个Filter处选择可视化的字段。例子选择的是usage_system(系统用量百分比),相关的Filter选定之后,点击submit,就会呈现出可视化的结果,这里默认的是Graph,出现如图所示的曲线图。在图中黄色线框部分可以选择动态页面刷新时间,在绿色线框部分可以选择数据开始的时间。
点击Save会保存刚才的图,在选择target dashboard,可以选择已经存在的system ,这里将可视化图命名为usage_system_graph。
2. Jmeter+InfluxDB2.0搭建性能监控环境
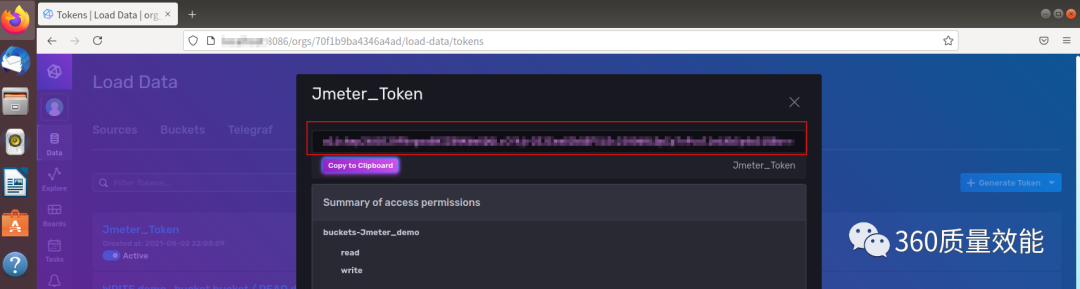
Jmeter相对于InfluxDB来说,属于外部系统,所以需要在InfluxDB中生成一个token用于外部时序数据写入数据库。
在InfluxDB中选择 Data → Tokens, 点击 Generate → Read/Write Token ,完成token创建。
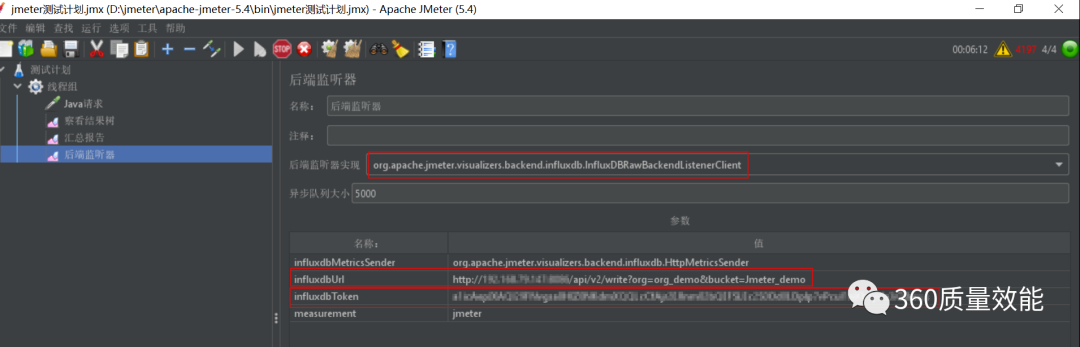
通过双击jmeter.bat进入Jmeter工作界面,创建一个线程组(Thread Group),在线程组中点选Loop Count Infinite,然后依次添加Java请求(Java Request),查看结果树(View Results Tree),汇总报告(Summary Report),后端监听器(BackendListener)。主要是在后端监听器填写相关参数,influxdbUrl要修改host,填写创建的组织org和bucket,influxdbToken就是上面创建的Jmeter_Token复制进去。若可以在influxdb中看到Java请求的数据结果,说明Jmeter与InfluxDB连接成功。
3. Flux在python3中的查询应用
Flux查询语言是InfluxDB2.0主推的查询语言,提供FluxTable,CSV,DataFrame和Raw Data四种查询API,但是在时间和日期上,较InfluxQL相对局限,仅支持RFC3339格式,默认值是当天零点。
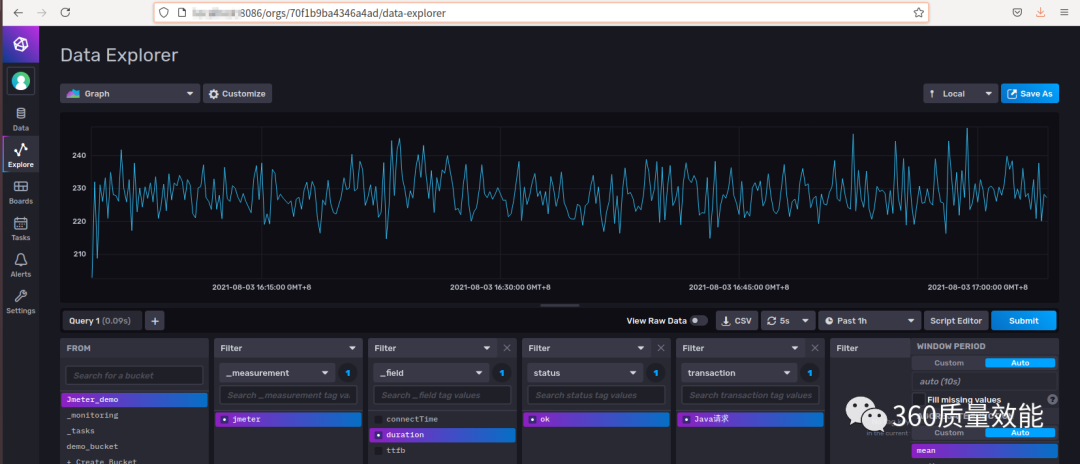
下图中红色框图则是曲线图的Flux查询语句,from表示数据源所在的bucket,|>表示管道连接符,range表示所查询数据所在的时间范围,其中 v.timeRangeStart 和 v.timeRangeStop 代表时间区间下拉框选中的时间段,filter是对range范围内的数据进行过滤,filter中的参数fn,是基于列和属性过滤数据逻辑的匿名函数,yield只在同一个Flux中出现多查询的时候才会出现,yield函数将过滤后的表作为Flux查询结果输出。
①. Flux语言实现系统数据的查询
首先通过InfluxDBClient连接InfluxDB数据库,InfluxDBClient中需要提供url,token的作用是保证外部系统可以访问数据,不同的bucket有不同的token,org是数据存储所在的组织,在首次登录的时候完成创建。
import pandas as pd
from influxdb_client import InfluxDBClient
# 设置
my_token = "PePwz1xFzM_edpm6NB0DyR2B04XWqDNQEFPmp9i8hxVW8DmlTTSzywrTyh_p5uv_k1h0Qdxy3U99J2S7TV9X7A=="
client = InfluxDBClient(url='http://192.168.79.147:8086', token=my_token, org='org_demo')
query_api = client.query_api()
# Flux查询语句
mem_query = '''
from(bucket: "demo_bucket")
|> range(start: -5w, stop: now())
|> filter(fn: (r) => r["_measurement"] == "mem")
|> filter(fn: (r) => r["_field"] == "available")
|> filter(fn: (r) => r["host"] == "ubuntu")
|> yield(name: "mean")
'''
table = query_api.query_data_frame(mem_query, "org_demo")
# 提取查询结果的部分字段值
mem_example = pd.DataFrame(table, columns=['_start', '_value', '_field', 'host'])
print(mem_example.head(5))
client.close()

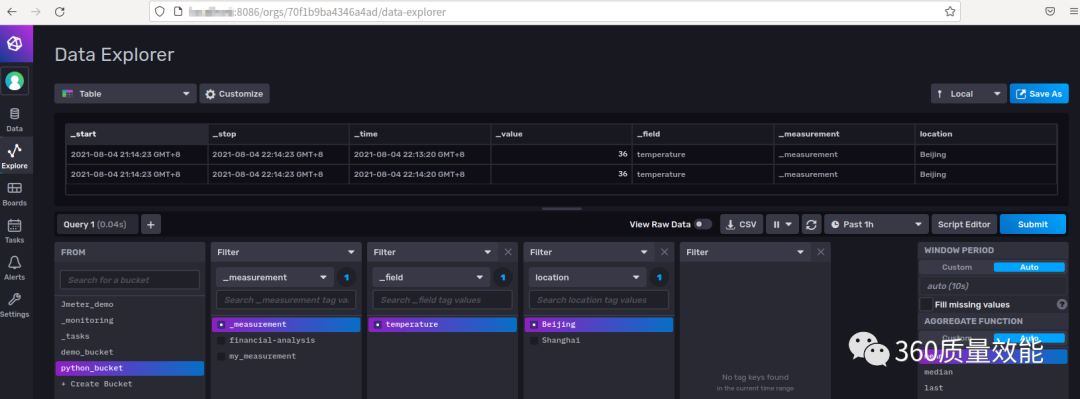
②. Flux语言实现数据插入
from influxdb_client import InfluxDBClient, Point, Dialect
from influxdb_client.client.write_api import SYNCHRONOUS
my_token="ENL3dUfGzTBFGcHzJ8iCIfbKF0fF7C7-P5PDkGpDWLzvvHuP2v9tKVgeZAFqV3y8sLXJt8alK0e-jicHVDgOEg=="
client = InfluxDBClient(url='http://192.168.79.147:8086', token=my_token, org='org_demo')
write_api = client.write_api(write_options=SYNCHRONOUS)
"""
数据准备
"""
_point1 = Point("_measurement").tag("location", "Beijing").field("temperature", 36.0)
_point2 = Point("_measurement").tag("location", "Shanghai").field("temperature", 32.0)
write_api.write(bucket="python_bucket", record=[_point1, _point2])
结果:
总结
从DB-Engines数据库趋势排行榜中可以看出,时序型数据库是数据库市场中份额增长最快的部分,尤其是在大数据的背景下,随时都在产生海量的时序数据,现在更多的企业会通过时序数据存储和数据分析来获得预测能力和实时决策能力,为客户提供更好的使用体验。















 8085
8085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}