







文章目录
【BUAA_CO_LAB】p5&p6碎碎念
写在前面的话
首先前面必须要附上一段致歉。其实这篇文章应该早在两三个星期之前就更出来了,但是由于期末月的到来,许多课程面临结课大作业/考试等任务,博主前段时间忙于各种大作业与其他事务,也没能很好地管理自己的时间(指周末睡大觉的屑),这个时候再发布,我估计大部分人其实应该都已经做完了这一部分了,所以这篇文章或许更多的意义在于“造福后人”罢。

不过看到了[p3&p4碎碎念]这篇博文下面的一些反馈,我个人还是很感动的,至少发现自己写的东西有人在看,有帮助到一些像我当初一样有困难的同学,个中情愫实在是无以言表。这也给了我继续写没什么技术含量的技术博客的动力,以及继续攻克计算机学习路上各种困难的决心!再次衷心感谢我的那几位读者!!(泪)
从p5开始,我们就从单周期CPU迈入了流水线CPU的旅程。这里的风景是独特的,其中的转发、阻塞等原理或许会让初遇的同学感到不知所措。刚开始写的时候我也迷茫了很久,但其实只要细心体会个中原理,就会豁然开朗。我的架构没有借鉴gxp老师的PPT和黑书相关内容,所以如果你已经照着这些教程做出架构了,就没必要完全按照此文来。

我不是那种思维跳跃的聪明同学,所以理解都是非常简朴的,在那些聪明同学看来或许会显得过于繁琐冗杂而可笑,但我希望记录下自己的思路,以为后来似我者之鉴(至少我在挣扎于这两p的时候是很希望有这样一种胎教级教程可以看看的)。同时,因为p6事实上是在p5的基础上加装乘除相关模块,没有什么需要特别分开说明的技术细节,因此我采取了以p5为主的叙述模式,与p6有关的“加装”部分我单独放在**[改装p6]**模块里说。
现在手握p4代码的你,就可以跟着本胎教教程着手改造自己的单周期CPU,进入流水线的新阶段了。当然,如有错误,还望在评论区不吝指正。
流水线知识
这个时候大家应该已经在理论课学过流水线相关知识,我就不再讲述流水线的必要性、效率、基础架构之类的东西了。我们直接进入流水线跟单周期CPU最不一样的三点:流水级、转发与阻塞。
流水级与命名
理论课中已经学到,为了使指令能够像PPT例子中的洗衣服那样同时安排(后面将大量使用“洗衣服”的例子),我们要细分出几个“洗衣步骤”或者说“流水线上的车间”,这就是我们的流水级。在书写正式的流水线代码之前,我们先基于p4代码做出一个“Pipeline Without Hazard”,也就是完全不考虑转发与阻塞,只是分出了流水级的CPU来。在课上,我们学到流水线CPU的基础流水级架构是这样的:

传统CPU有四大功能:取指、译码、执行计算、存取,这不就刚好可以分成四个“洗衣步骤”吗?同时,由于后续转发的特殊性,我们增加了一个写回级(Write Back)。这样就构成了五个基础的流水级。接下来,我们就往五个流水级里塞更细的“洗衣步骤”,也就是各个模块(当然,别忘了重要的控制信号生成单元Control Unit)。4个流水级寄存器,不过是我们用来传递“衣服”,或者说流水线上的“工件”的传送带而已,前一周期中的上一阶段所传来的数据,和后一周期中为下一阶段提供的数据,都在且必须在这条传送带上流淌。无论是数据还是信号,都需要在寄存器中进行保存,直至不再需要。
增添模块如下图所示。

可以看到,除了绿色的[比较模块CMP]以外其他都已经在p4里写过了,基础架构拿过来用就行。这里我们还要注意一点,每个“洗衣小车间”是独立的(请务必,务必,务必记住这个概念),只通过流水线传送带——即流水级寄存器连接,也就是说在每一级产生的控制信号是具有其独立性的。因此我们只需要写出一个单独的Control Unit,然后在顶端模块中的不同流水级里对Control Unit分别进行不一样的实例化调用。(阅读课设教程,你会发现这种写法叫做“分布式”)
在把它们组合起来之前,要先给它们改个名字,同时,输入输出各个模块的信号名字都请命名成形如**[Pipeline Level] _ [Module name] _ [Signal name]**的形式(如E_ALU_Result),以辨析各个流水级,避免后续接线之类的错误。课程组教程的命名建议就非常好。我的命名是如图中红字所示。
-
绿色的[比较模块CMP]
它是我们用来判断Branch类跳转是否发生的,它会通过对输入的rs和rt值进行判断,给出一个“branch_or_not”信号指导跳转的发生与否。有的同学可能在p3、p4时期就已经开辟过类似模块做过这件事了。下面给出我的代码(p6版本),相信大家看了以后就明白它的作用了。这个模块在上机的时候也会帮你大忙。
对了,请务必不要一字不差地复制,咱的课设还没结束呢orz
`timescale 1ns / 1ps
`define b_beq 3'd0
`define b_bne 3'd1
`define b_blez 3'd2
`define b_bgtz 3'd3
`define b_bltz 3'd4
`define b_bgez 3'd5
`define nobranch 3'd6
module D_CMP(
input [31:0] RF_RD1, //Read From RD1 -> rs
input [31:0] RF_RD2, //Read From RD2 -> rt
input [2:0] branch_type, //Created by Control Unit
output branch_or_not
);
wire equal = (RF_RD1 == RF_RD2);
wire equal_0 = !(|RF_RD1);
wire greater_0 = ((!equal_0) && (!RF_RD1[31])); //请尽量使用对[31]的判断来辨别正负数,Verilog的有符号系统真的很坑!!!
wire less_0 = ((!equal_0) && (RF_RD1[31]));
assign branch_or_not = (equal && (branch_type == `b_beq)) ||
(!equal && (branch_type == `b_bne)) ||
((less_0 | equal_0) && (branch_type == `b_blez)) ||
((greater_0) && (branch_type == `b_bgtz)) ||
((less_0) && (branch_type == `b_bltz)) ||
((greater_0 | equal_0) && (branch_type == `b_bgez));
endmodule
我给出了这个新的模块的参考写法,剩下的模块中,除了五个流水级寄存器和Control Unit,都可以基本照搬p4了,只需要按照给出的指令集要求稍作修饰即可(比如指令类型、所需的控制信号类型、存储器的大小等)。
-
有一个值得注意的小地方是PC值运算模块NextPC。它的写法与p4略有不同。有些指令的跳转地址选择的 PC 指令是它自己这个小车间对应的相对独立的“当前指令”,而不是电路中宏观的当前指令,比如需要被 CMP 模块判断的分支跳转指令和 J 型指令,它们的各类判断发生在 D 级流水级,因此跳转地址对应的“当前指令”也应该是 D 级流水级中的 PC 值 D_PC,而不是直接从F 级流水级的 IM 模块发出的 F_PC。 其实这一点,只要理解了前面“小车间独立性”的叙述,就非常容易理解了对不对?洗衣服の例子,yyds……
`timescale 1ns / 1ps `define Branch 3'd0 `define J 3'd1 `define Jr 3'd2 `define Normal 3'd3 module NextPC( input [31:0] D_PC, input [31:0] F_PC, input [25:0] Addr, //Addr or Imm16(Addr[15:0]) input [31:0] reg_rs, input [2:0] NextType, input branch_or_not, output [31:0] NPC ); assign NPC = (NextType == `Normal) ? (F_PC + 4) : (NextType == `J) ? {D_PC[31:28], Addr, 2'b00} : (NextType == `Jr) ? reg_rs : ((NextType == `Branch) && (branch_or_not == 1'b1)) ? (D_PC + 4 + {{14{Addr[15]}}, Addr[15:0], 2'b00}) : (F_PC + 4); endmodule
下面介绍五个流水级寄存器和Control Unit的写法。
流水级寄存器
首先我们应该明确模块的输入输出,也就是说,这个寄存器究竟要存“哪些衣服”?刚过过水的?刚打过泡的?这个时候,只要分析一下指令在流水线中流淌的过程就可以明确,也即,我希望将什么样的信号传给下游的“车间”来处理(请务必记住每个流水级是相对独立的五个小车间!它们之间唯一的联系就是一条流水线传送带!)。下面将指令分为R型计算指令、I型计算指令、内存访问指令、Branch类指令和Jump类指令分析。
前文提到过,为保证“小车间独立性”,每一个流水级里都需要单独实例化Control Unit,而光它一个人就需要指令编码Ins[31:0]了吧,因此下文不再重复提及其必要性。而我想,理论课上应该也已经讲过流水线CPU需要将当前PC值不断流水的特性,因此后面也不在每一级赘述了。它们是基础。
时钟信号clk、复位信号Reset和写使能信号WE更是基础中的基础,不必再说了。
同时,由于流水级寄存器为所有指令所共用,因此我会直接列出该流水级寄存器需要存储的所有信号,并在对应的指令分析部分对该指令需要的信号进行下划线处理,望读者辨析。
R型计算指令
- IF_ID - Ins[31:0] + PC[31:0]
- ID_EXE - Ins[31:0] + PC[31:0] + rs[31:0] + rt[31:0] + Ext[31:0]
- 众所周知,R型指令的R指的就是Register,从通用寄存器堆里取出来的数据,为了在E级对它们进行算术运算,GRF[rs]和GRF[rt]值是一定要传递到下一个小车间去的。
- EX_MEM - Ins[31:0] + PC[31:0] + ALU[31:0] + rt[31:0] + Ext[31:0]
- 接收ALU运算结果
- MEM_WB - Ins[31:0] + PC[31:0] + ALU[31:0] + DM[31:0] + Ext[31:0]
- 接收ALU运算结果,把ALU运算结果写回通用寄存器堆
I型计算指令
- IF_ID - Ins[31:0] + PC[31:0]
- ID_EXE - Ins[31:0] + PC[31:0] + rs[31:0] + rt[31:0] + Ext[31:0]
- I指立即数Immediate,我们需要从Ext模块取出的处理好了的立即数,在E级和GRF[rs]进行算术运算
- EX_MEM - Ins[31:0] + PC[31:0] + ALU[31:0] + rt[31:0] + Ext[31:0]
- 接收ALU运算结果
- MEM_WB - Ins[31:0] + PC[31:0] + ALU[31:0] + DM[31:0] + Ext[31:0]
- 接收ALU运算结果,把ALU运算结果写回通用寄存器堆
内存访写指令
- IF_ID - Ins[31:0] + PC[31:0]
- ID_EXE - Ins[31:0] + PC[31:0] + rs[31:0] + rt[31:0] + Ext[31:0]
- 访问:需要从Ext模块取出的处理好了的立即数,在E级和GRF[rs]进行算术运算,获得访问数据存储器的地址,具体参见指令集的RTL描述细节
- 写入:需要将从通用寄存器堆里取出来的数据在E级进行算术运算,rs和rt都要
- EX_MEM - Ins[31:0] + PC[31:0] + ALU[31:0] + rt[31:0] + Ext[31:0]
- 访问:接收ALU运算结果
- 写入:接收ALU运算结果还有rt值,用于计算写入地址
- MEM_WB - Ins[31:0] + PC[31:0] + ALU[31:0] + DM[31:0] + Ext[31:0]
- 接收内存访问结果,把结果写回通用寄存器堆
Branch类指令
不用麻烦后面,一切在D级完结(唯一需要麻烦后面的是转发问题,后面再说)
Jump指令
不用麻烦后面,一切在D级完结(唯一需要麻烦后面的是转发问题,后面再说)
这时你会发现好像还有几个地方没被标过下划线,没关系,那是接下来即将要讲的转发部分需要的。先写上吧!
Control Unit
对于这一部分,我觉得美工非常重要。整洁的排版可以有效地增加上机加指令的效率。总体上说,跟p4部分的架构其实差不多,只是需要进行一些排版。比如说,我们可以合并所有的R型指令为Cal_r等,这样不仅有利于各种控制信号的生成,而且对后面要讲的阻塞有大用处。下面我贴上我的“排版”,大家予以参考即可。
- Part_1: 宏定义

- Part_2: 信号定义分割

- Part_3: 中间信号分类

-
Part_4: 控制信号生成(写之前一定要先列好表噢)
p.s. 在这里,我建议把所有需要用MUX选择的部分(不管是选择写入地址也好,写入数据也好),统统集成到这个地方来,而不是再去费劲心机地写好多个不同位宽的MUX,吃力不讨好,而且会显得逻辑很乱。就如下图的第一条assign一样,把本该通过顶层模块中MUX来选择的寄存器堆写入地址RegDst直接采用这种方式定义出来,就非常方便,要用的时候直接引出一个RegDst就好了,根本不用在外面判断。
类似的例子还有很多,比如MemToReg呀,ALU_Src_A和ALU_Src_B呀,都可以集成到CU这里来。

最后,我给出我对控制信号做出的安排(p5版本),以供大家参考。



至此,能吃p4老本的地方结束。
转发
- 通俗的讲解
转发是流水线 CPU 中至关重要的环节。数据冒险的严格定义请自行复习,我在这里只作我非常简朴的讲解。我认为转发需要存在的根源在于:流水线是一级一级地往下流的,有的时候当前我们需要的GRF[rs]值或者GRF[rt]值还在后边刚被算出来,还没来得及被传回到通用寄存器堆里去,它事实上已经产生了,只是流水线太拖拉,我们还够不到它而已,因此我们需要一条捷径,把已经产生了但走得太慢,还来不及回到通用寄存器堆的数据迅速地传到我们手中。
这就好比我们的洗衣服流水线,ID_EXE级的老哥负责把洗好的衣服打包送给客户。现在客户催着他要衣服,最后一级的老哥其实已经把衣服洗好了,但衣服还在流水线上流着呢,偷工减料的黑心流水线走得过于慢了,还有好一会儿衣服才能到ID_EXE老哥这里。因此现在ID_EXE级老哥叫了一个叫转发的小工蹲在最后一级的老哥那里,他一洗好,就火速夺过衣服跑步送给ID_EXE级老哥。在我们的流水线里,E级、M级和W级都蹲着一个叫转发的小工,随时准备将处理好的衣服夺过来跑步送给寄存器,这就是转发的意义所在。毕竟时间就是金钱,效率就是生命嘛。(怪不得叫暴力转发)

当然,在这里我们假设的是客户来要衣服的时候,衣服必然已经洗好了。如果没洗好,小工啥也没拿到呢?这时就不得不让客户再等等了,这就是下一部分要讲的“阻塞”问题。判断是否洗好的部分交给阻塞模块,在转发模块里,我们默认所有的衣服都已经洗好了,这就是教程里所描述的“全力”转发。
为了实现这一点,我们首先要将“衣服”,也就是通用寄存器组的读出值GPR[rs]和 GPR[rt]不断地在各个流水级寄存器之间流水并且存储,然后通过当前的指令生成的控制信号(一般是RegDst)来判断是不是要发生转发。如果我们现在需要的写入地址值,也就是“客户”,刚好跟某个流水级里的RegDst一样,就说明该客户的衣服在这里洗好了,我正要往客户那里送呢,那么转发小工,就拿上衣服走人吧。
- 代码细节
需要发生转发的时间节点是:当前的“不够”的时候,也就是当某一部件需要使用 GPR[rs]或GPR[rt]时,这个值还没来得及写入 GPR 的时候。这个时候,我们需要通过转发将这个值从流水线寄存器中送到该部件的输入处。这也就说明,**在每一个需要使用 GPR[rs]或者 GPR[rt]的端口节点前面,我们都可以对当前的 rs 和 rt 值做出一个判断,判断是可以使用当前的值,还是说当前的“不够”,需要提前获取后面的值。**教程中的原意应该是用 MUX 来实现,但是由于目标信号数量的不定性,我认为 MUX 模块的设置并不太方便,同时我也不喜欢把转发也集成成为一个模块(线太多了),因此我选择直接在顶层模块连线的时候,在对应端口模块实例化的前面先对输入信号做出一个判断,如下图所示。
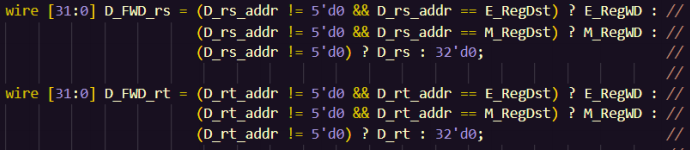


根据对数据通路的分析,这样的位点其实很有限,只有 D 级 CMP 模块的输入、E 级 ALU 模块的输入和 M 级 DM 模块的输入(就是要用rs、rt值的地方嘛)。只要当前位点的读取寄存器地址和某转发输入来源的写入寄存器地址相等且不为 0,就选择该转发输入来源;在有多个转发输入来源都满足条件时,最新产生的数据优先级最高,以实现全力转发。
同时为了满足“最新产生的数据”这一点,我们需要在 GRF 的内部实现内部转发,也就是将输入的数据实时反馈到输出端口,避免数据的滞塞。
需要注意的是对当前流水级来说,能够选择的转发来源是“它之后与 GRF 之前”的流水级区间(小工总不可能把不洗衣服的车间里的衣服也抢了吧),因为如果数据都到了 GPR 就不存在所谓的转发与否的问题了,衣服都已经流到我手上了,直接拿不香吗……因此对 D 是 E、M(由于 W 的回写行为与它直接对接,通过 GPR 的反馈不存在转发的问题),对 E 是 M、W,对 M 是 W,而 W 级已经不存在需要转发的数据了。也就是说,关键其实就是“我需要的数据可能滞留在哪里”。
- 后边加指令的时候也是一个道理,这一级要用,我就全力转发(比如某些指令可能在M级也需要rs值,那你就需要多写一个M_FWD_rs了),转发的范围是我之后到GRF之前,从新到旧,最后到我自己(本级的值)。就是这么简单的思路。
阻塞
比起转发,阻塞的道理其实简单得多,就是在转发没有办法解决问题的时候,比如说新的数据根本还没有产生的时候,向进程中插入“气泡”暂缓流水,等信号产生了以后再开始流动,并实现数据的获取(通过转发等方式)。而 “新的数据根本还没有产生”的条件是【Tuse < Tnew 且满足转发条件】,就是说需要用数据了,客户来了,但我的衣服还踏马没洗好呢。

在CPU中的行为就是把指令暂停在 D 级,也即用一个 Stall 信号来参与控制该级流水寄存器的写入数据行为,使得后面的值不会被更新,相当于插入了一个 nop,或者说是一个“气泡”,让中间的模块安静地执行完现在的进程,等“气泡”消除了之后,把新的值写到流水寄存器中继续开始流水。
插入“气泡”的具体操作是:冻结PC值停止流水线运行(流水线再走衣服真的洗不完了哥,停一会儿罢),清空ID_EXE(后边的慢慢洗罢,不再给你们派新活了,把手头的洗完再说)。看到这个描述,你应该非常清楚前者通过WriteEnable写使能信号完成,后者通过Reset复位信号完成。因此我们只需要新建一个能够生成阻塞信号的阻塞模块,然后将它产生的阻塞信号分别与部分寄存器的WE信号和部分寄存器的Reset信号与一下就可以了。
- 与之类似的一个操作叫做【清空延迟槽】,它的动作是清空IF_ID,但是并不冻结PC值,更不会清空ID_EXE,请阅读英文指令集有关内容自行思考。
Tuse:指令进入 D 级后,其后的某个功能部件再经过多少时钟周期就必须要使用寄存器值。对于有两个操作数的指令,其每个操作数的 Tuse 值可能不等(如 store 型指令 rs、rt 的 Tuse 分别为 1 和 2 )。用D级的信号判断。
Tnew:位于 E 级及其后各级的指令,再经过多少周期就能够产生要写入寄存器的结果。在我们目前的 CPU 中,W 级的指令 Tnew 恒为 0;对于同一条指令,Tnew@M = max(Tnew@E - 1, 0)。 后面每一级都要具体判断。
似乎有很多人喜欢在这里画表,但我感觉不用吧,自己想一想就能明白了,如下图所示。比如对于Tuse,branch类和J类的跳转与否的判断在D级就可以完成,自然是0(不用再找后面的了),需要E级的ALU运算结果的就再往后一个周期,就是1,后面的以此类推了。需要注意的是对于无关的东西我们要把Tuse设置为一个很大的值(比如我的3’d5),相当于一直塞着。


根据 Tuse 和 Tnew 所提供的信息,可以得出:当满足转发条件(详见“转发”部分),且 D 级指令的 Tuse 小于对应 E 级或 M 级指令的 Tnew时,我们就在 D 级暂停指令。在其他情况下,数据冒险都可以通过转发解决。
从 Tuse 和 Tnew 的表达式,我们也能看出需要在每一个流水级都判断一下当前的 Tuse 和 Tnew 值,以完成比对。这整个过程可以看成一个这样的流程:

当然了,在“全力转发”的思路下,我们的代码里已经没有GRF后面的“可与不可”的判断了(管它现在有没有呢,满足转发条件的直接转发),这个图只是对转发必要性的一个更直观的诠释。
p5の完结
最后,在顶端模块里把所有的模块都实例化并连接起来吧——你的流水线CPU就这样诞生了。如果不清楚接线细节,可以参考PPT等资源,但我感觉只要把上面的逻辑捋清了,再结合p4的基础,搭出美丽的p5、p6并不是问题。接下来就是测试等环节,讨论区的同学珠玉在前,我也不在此班门弄斧了,请大家好好利用身边同学的资源吧!!
本学期课设结束后,我会把我的代码上传到Github上去,届时会在本博文评论区里附上网址,以供后来人参考。

改装p6
p6跟p5的区别在于多了很多指令,以及乘除相关的{mult, div, multu, divu, mthi, mtlo, mfhi, mflo}。对于前面新增的指令,相信只要通过了p5课上的同学都能轻松地照葫芦画瓢给它加上去,在此就不赘述了。唯一麻烦的就是乘除相关模块的加装以及访存数据存储器时对不同位宽数据的处理。我们在p5的基础上进行改装,从而实现这两个地方。
乘除模块
乘除法是一种算术运算指令,因此我们把单独开辟出来的乘除模块放在E级,我给它取名叫E_HILO。在这里,我们需要完成乘除法的算术运算,并且模仿乘除法运算延迟的行为和从HI、LO寄存器中取值的行为。
模仿乘除法运算延迟
乘除法运算在电路中进行得很慢,所以我们需要进行一个模仿。这里我想到了之前学过的有限状态机,我们可以设置一个Cycle状态信号,执行过乘除法后,它就充当一个计时器,等Cycle里的延迟时间走完了之后,我们再进行后面的操作。乘除法部件中内置了 HI 和 LO 两个寄存器,这两个寄存器,同时也是这个模块与外界沟通的唯一窗口。
我们假定乘 / 除部件的执行乘法的时间为 5 个 cycle (包含写入内部的 HI 和 LO 寄存器),执行除法的时间为 10 个 cycle。你在乘 / 除部件内部必须模拟这个延迟,即通过 Busy 输出标志来反映这个延迟。

想明白了“计时器”的实现后,代码写起来就没什么技术含量,下面是我的,仅供参考。
always@(posedge clk)begin
if (reset)begin
//Reset all the Signals
end
else begin
if (cycle == 0)begin
if (HILO_mthi)
//Operation
else if (HILO_mtlo)
//Operation
else if (HILO_mult)begin
busy <= 1'b1;
cycle <= 5;
//Operation of MULT
end
else if (HILO_multu)begin
busy <= 1'b1;
cycle <= 5;
//Operation of MULTU
end
else if (HILO_div)begin
busy <= 1'b1;
cycle <= 10;
//Operation of DIV (Attention: Split the result into HI and LO!!!!)
end
else if (HILO_divu)begin
busy <= 1'b1;
cycle <= 10;
//Operation of DIVU (Attention: Split the result into HI and LO!!!!)
end
end
else if (cycle == 1)begin
busy <= 1'b0;
cycle <= 0;
HI <= tmp_hi;
LO <= tmp_lo;
end
else
cycle <= cycle - 1;
end
end
按字节访存
由于我们这一学期的p6改为了【存储器外置】的形式,据我所知跟之前有所不同,我也不确定以后是不是这样,所以我就不写存储器外置的写法了(课程组可能会有具体要求,实现也不难的,在顶端模块里处理就行)。在这里贴上一个通用版本的支持按字节访存的DM代码。(好像p4已经贴过了?)
`timescale 1ns / 1ps
`define BW_word 2'b00
`define BW_halfword 2'b01
`define BW_byte 2'b01
`define word DataMemory[DM_A[15:2]]
`define halfword `word[15 + 16 * DM_A[1] -:16] //-意为从此开始往下16位,同理,如果是+就是往上16位。这么写的原因是因为DM_A并非是一个constant,在Verilog的语法定义里,不可以用变量的值表示向量位宽,除非采用这种写法,不然必报错
`define half_sign `word[15 + 16 * DM_A[1] -:1]
`define byte `word[7 + 8 * DM_A[1:0] -:8]
`define byte_sign `word[7 + 8 * DM_A[1:0] -:1]
module M_DM(
input [31:0] DM_A,
input [31:0] DM_WD,
input [1:0] BW,
input [31:0] PC,
input MemWrite,
input Clk,
input Reset,
output [31:0] DM_out
);
reg [31:0] DataMemory [3071:0];
assign DM_out = (BW == `BW_word) ? (`word) :
(BW == `BW_halfword) ? {{16{`half_sign}}, `halfword} :
(BW == `BW_byte) ? {{16{`byte_sign}}, `byte} : `word;
integer i;
initial begin
for (i = 0; i < 3072; i = i + 1)begin
DataMemory[i] = 32'd0;
end
end
always@(posedge Clk)begin
if (Reset)begin
for (i = 0; i < 3072; i = i + 1)begin
DataMemory[i] = 32'd0;
end
end
else if (MemWrite)begin
$display("%d@%h: *%h <= %h", $time, PC, DM_A, DM_WD);
`word <= DM_WD;
`halfword <= DM_WD[15:0];
`byte <= DM_WD[7:0];
end
end
endmodule
到这里,其实p6就完成了,没有想象中那么难罢。
但是注意:p6的指令很多,加的时候一定要看清楚机器码等细节,尤其是在处理控制信号的时候。
课上指令之套路
课上指令可以总结为三类:R型/I型运算类(运算),B+alr类(条件跳转),lw/sw + [condition]类(条件访存)。它们都有自己对应的套路。
运算类
如果你在Control Unit里做好了中间信号分类,那么运算类就是小菜一碟。在Control Unit里先宏定义好新指令信号,将其合并入cal_r或者cal_i中,这样你就不用再理会任何与阻塞/转发有关的东西了。然后,为它分配一个新的ALUOp码,去ALU模块里定义好它的具体运算操作,基本上就完成了。一般来说加这个运算类指令可以在5分钟内解决战斗——只要你课下没错。所以,做好测试!!!
运算类也可能会出现“条件写”的要求,比如运算结果满足某条件才写回,这里只需要在E级把你运算得到的结果转化成条件真值,然后传到E级Control Unit里去指导RegDst就可以了。
条件跳转类
一般是B+alr类。首先,在Control Unit里将它合并到branch类中,此后阻塞不必再理。然后为它分配合适的BranchType等控制信号,到对应的模块中判断跳转是否发生,并且生成好NextPC的值(根据题干具体定)。这时,我们可以得到来自CMP模块的判断信号branch_or_not(根据判断条件的不同,可以酌情向CMP模块中加入信号)。用这个branch_or_not信号,我们可以在D级中定义是否发生跳转的信号为一个check信号:wire check =branch_or_not,然后将这个信号流水下去。如果新的指令需要你在条件跳转的同时写寄存器(比如写$31),那么就在每个流水级都将这个check信号传入到控制信号生成器中去,和指令信号一起指导RegDst等信号的生成。
条件访存类
在这里,第一步依然是合并指令到load类或者store类中,进行一些常规的控制信号处理操作。不过这时我们不能再对阻塞模块和转发置之不理。因为根据题目的特定要求,它有的时候在M级需要rs值(只是举个例子),这个时候我们就需要在M级加上对rs的转发;
在阻塞模块里,我们也要做出修改,因为我们在M级才能得到条件真值,这个时候如果D级有需要rs、rt的动作(有客户来取衣服了),E级的情形就是不确定的,因此我们需要在E级进行一个保守的条件约束:如果E级也是该条指令,并且此时D级要用该条指令要写入的寄存器,我们就stall。形如:

当然根据不同指令的要求不同,这里给E级强加的暂停条件也不同,请大家根据指令的RTL描述自行变通。但我认为条件暂停的根本是只约束E级,因为事实上只有这里可以产生RegDst等控制信号的不定值(也有人认为M级也要约束,但对于课上测试结果应该是一样的)。
本文到此就结束了,如果文中有错误,或者有我还说得不清楚的地方,欢迎大家在评论区留言告知。虽然也没几个人看,但是已有的读者的反馈真的让我感到非常感动,今后我也会努力学习并分享各种知识(寒假我会选择分享一些独立游戏制作的内容,比如unity3d和GMS2),力求能够帮助到有需要的人!谢谢!!(鞠躬
















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









