








欢迎来到Cefler的博客😁
🕌博客主页:那个传说中的man的主页
🏠个人专栏:题目解析
🌎推荐文章:题目大解析(3)

目录
👉🏻关联式容器
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、
forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
在C++标准库中,关联式容器是一类可以存储有序键值对的容器,它们提供了快速的查找、插入和删除操作。这些容器使用键来索引其元素,而不是像其他容器那样使用位置。
C++标准库中的四个关联式容器是:
std::set:一个有序不重复元素的集合。std::multiset:一个有序允许重复元素的集合。std::map:一个有序的键-值对集合,每个键唯一对应一个值。std::multimap:一个有序的键-值对集合,一个键可以对应多个值。
这些容器都是基于红黑树或哈希表实现的。它们提供了各种成员函数来进行元素的插入、删除和查找操作,并支持迭代器来遍历所有元素。
关联式容器的主要优点是提供了快速的元素查找能力。例如,在std::map中,元素可以通过键进行快速检索,而在std::set中,元素可以直接按照顺序进行遍历。另外,由于这些容器是有序的,因此它们还提供了对元素的范围查询操作。
总之,关联式容器是一种非常有用的数据结构,可以用于需要高效地查找元素的场景,如数据库索引、字典、词典等。
👉🏻键值对
键值对(Key-Value Pair)是一种数据结构,它由一个唯一的键和与之关联的值组成。在这种结构中,通过键可以快速地查找、访问或修改对应的值。
键值对在编程中有广泛的应用,特别是在关联式容器中常见。例如,在std::map和std::unordered_map中,每个元素都是一个键值对,其中键用于唯一标识该元素,值则是与键相关联的数据。
使用键值对的好处包括:
- 快速查找:通过键,可以在常数时间内找到对应的值,而无需遍历整个数据结构。
- 数据关联性:键值对能够将相关联的数据放在一起,方便管理和操作。
- 唯一性要求:键在键值对中是唯一的,因此可以用作标识或索引。
在C++中,可以使用std::pair来表示键值对。std::pair是一个模板类,包含两个成员变量first和second,分别表示键和值。例如:
std::pair<int, std::string> myPair;
myPair.first = 42; // 键为整数 42
myPair.second = "Hello, World!"; // 值为字符串 "Hello, World!"
在关联式容器中,键值对的插入、删除和查找等操作都是基于键进行的,通过键可以快速定位和访问对应的值。
总而言之,键值对是一种常见的数据结构,用于将键与相应的值关联起来,提供了高效的数据查找和操作能力。它在各种编程场景中都有重要的应用,包括数据库、缓存、配置文件等。
👉🏻pair
pair官方文档:pair
pair 类是 C++ 标准库中的一个模板类,定义在 <utility> 头文件中。pair 类用于存储一对值,它将两个值组合在一起,形成一个有序对。
pair 类的声明如下:
template <class T1, class T2>
struct pair {
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
// 构造函数
constexpr pair();
template<class U, class V> constexpr pair(U&& x, V&& y);
template<class U, class V> pair(const pair<U, V>& p);
template<class U, class V> pair(pair<U, V>&& p);
template<class... Args1, class... Args2> pair(piecewise_construct_t, tuple<Args1...> first_args, tuple<Args2...> second_args);
// 重载赋值运算符
pair& operator=(const pair& p);
template<class U, class V> pair& operator=(const pair<U, V>& p);
pair& operator=(pair&& p) noexcept(see below);
template<class U, class V> pair& operator=(pair<U, V>&& p);
// 比较操作符
template<class U, class V> bool operator==(const pair<U, V>& lhs, const pair<U, V>& rhs);
template<class U, class V> bool operator!=(const pair<U, V>& lhs, const pair<U, V>& rhs);
// 更多比较操作符省略...
// 交换函数
void swap(pair& p) noexcept(see below);
};
pair 类有两个成员变量:first 和 second,分别用于存储两个值。这两个成员变量是公有的,可以直接访问。
pair 类提供了多个构造函数,可以根据需要选择不同的构造方式。使用默认构造函数时,两个成员变量会被初始化为默认值。另外还提供了通过传入两个参数或使用其他 pair 对象进行构造的构造函数。
除了构造函数之外,pair 类还重载了赋值运算符和比较操作符。可以使用赋值运算符将一个 pair 对象的值赋给另一个 pair 对象。比较操作符可以用于比较两个 pair 对象的大小关系。
此外,pair 类还提供了 swap 函数,用于交换两个 pair 对象的值。
下面是一个使用 pair 类的简单示例:
#include <iostream>
#include <utility>
int main() {
std::pair<int, std::string> myPair(42, "Hello");
std::cout << "First value: " << myPair.first << std::endl;
std::cout << "Second value: " << myPair.second << std::endl;
myPair.first = 99;
myPair.second = "World";
std::cout << "Updated first value: " << myPair.first << std::endl;
std::cout << "Updated second value: " << myPair.second << std::endl;
return 0;
}
上述示例中,我们创建了一个 pair 对象 myPair,其中包含一个整数和一个字符串。然后我们分别访问和修改了 first 和 second 成员变量的值,并输出到控制台。
make_pair
当我们需要创建一个 pair 对象时,可以使用 make_pair 函数。make_pair 是一个模板函数,它接受两个参数,将这两个参数组合成一个 pair 对象并返回。
make_pair 函数的声明如下:
template <class T1, class T2>
constexpr pair<typename std::decay<T1>::type, typename std::decay<T2>::type> make_pair(T1&& t, T2&& u);
make_pair 函数的参数可以是任意类型,包括基本类型、自定义类型和其他标准库类型。参数的类型会被自动推导,并根据推导的结果创建一个对应类型的 pair 对象。
下面是一个使用 make_pair 的示例:
#include <iostream>
#include <utility>
int main() {
auto myPair = std::make_pair(42, "Hello");
std::cout << "First value: " << myPair.first << std::endl;
std::cout << "Second value: " << myPair.second << std::endl;
return 0;
}
在上述示例中,我们使用 make_pair 函数来创建一个 pair 对象 myPair,其中包含一个整数和一个字符串。由于 make_pair 函数会自动推导参数类型,我们不需要显式指定类型。
通过 make_pair 函数创建的 pair 对象可以直接使用,无需手动指定模板参数类型,使代码更加简洁。
总结一下,make_pair 是一个方便的函数模板,用于创建 pair 对象。它可以根据参数的类型自动推导并创建对应类型的 pair 对象。
👉🏻Set
set官方文档:set
C++中的std::set是一个容器类,它可以存储一组有序、不重复的元素,set中的元素不允许修改。std::set是基于红黑树数据结构实现的,它自动保持元素的顺序,并提供了有效的查找和插入操作。
std::set可以在O(log n)的时间内完成插入、删除和查找操作,其中n是当前元素数量。它提供了多个成员函数,包括:
insert(val):插入一个值为val的元素erase(val):删除值为val的元素clear():清空所有元素size():返回当前元素数量empty():判断是否为空
此外,std::set还提供了迭代器,可以通过以下方式遍历所有元素:
for (auto it = mySet.begin(); it != mySet.end(); ++it) {
// 执行操作
}
总之,std::set是一个高效且易于使用的容器类,在需要维护一组有序、不重复元素的场景下非常有用,注意set不支持修改元素。

T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
Compare:set中元素默认按照小于来比较
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
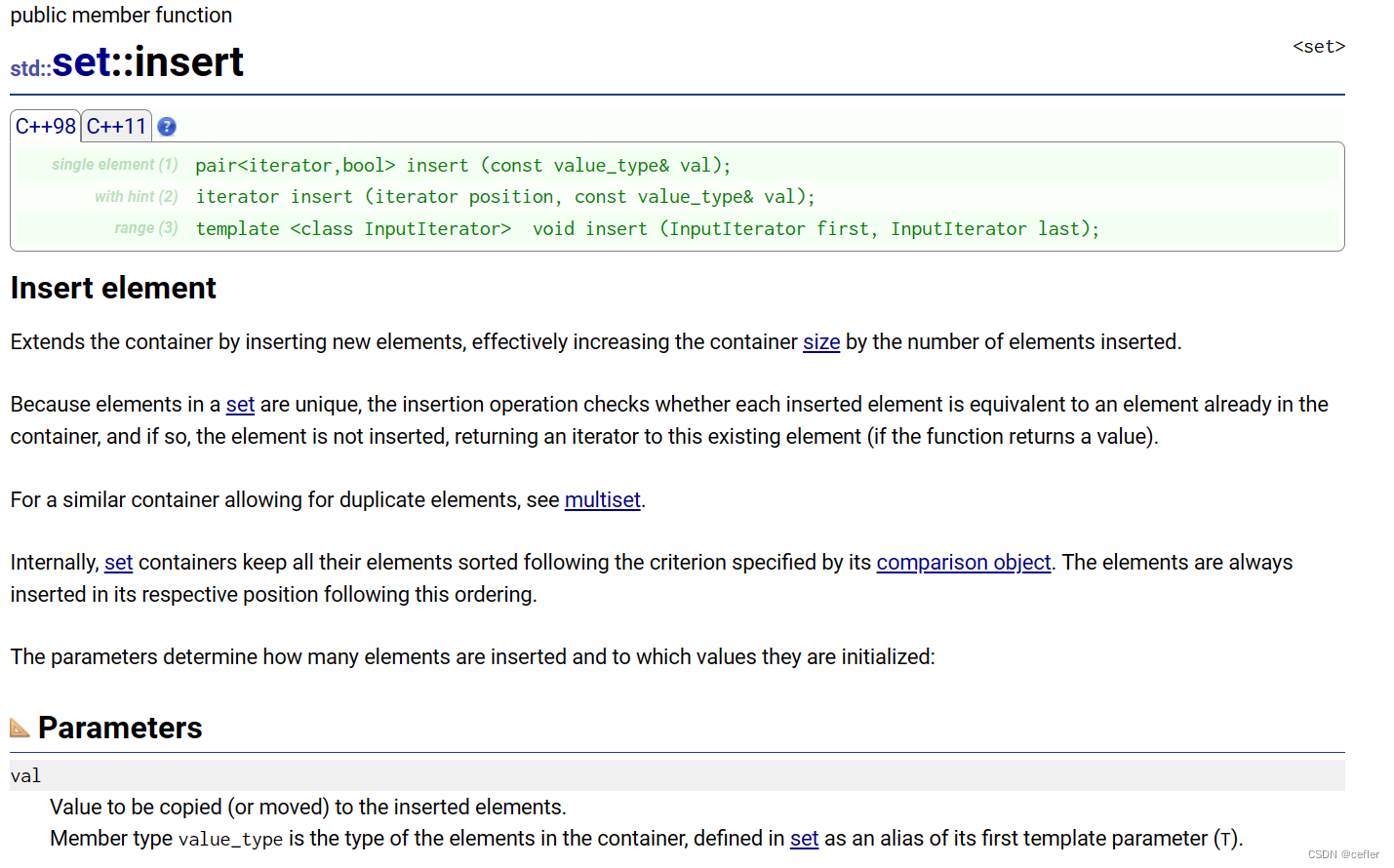
insert
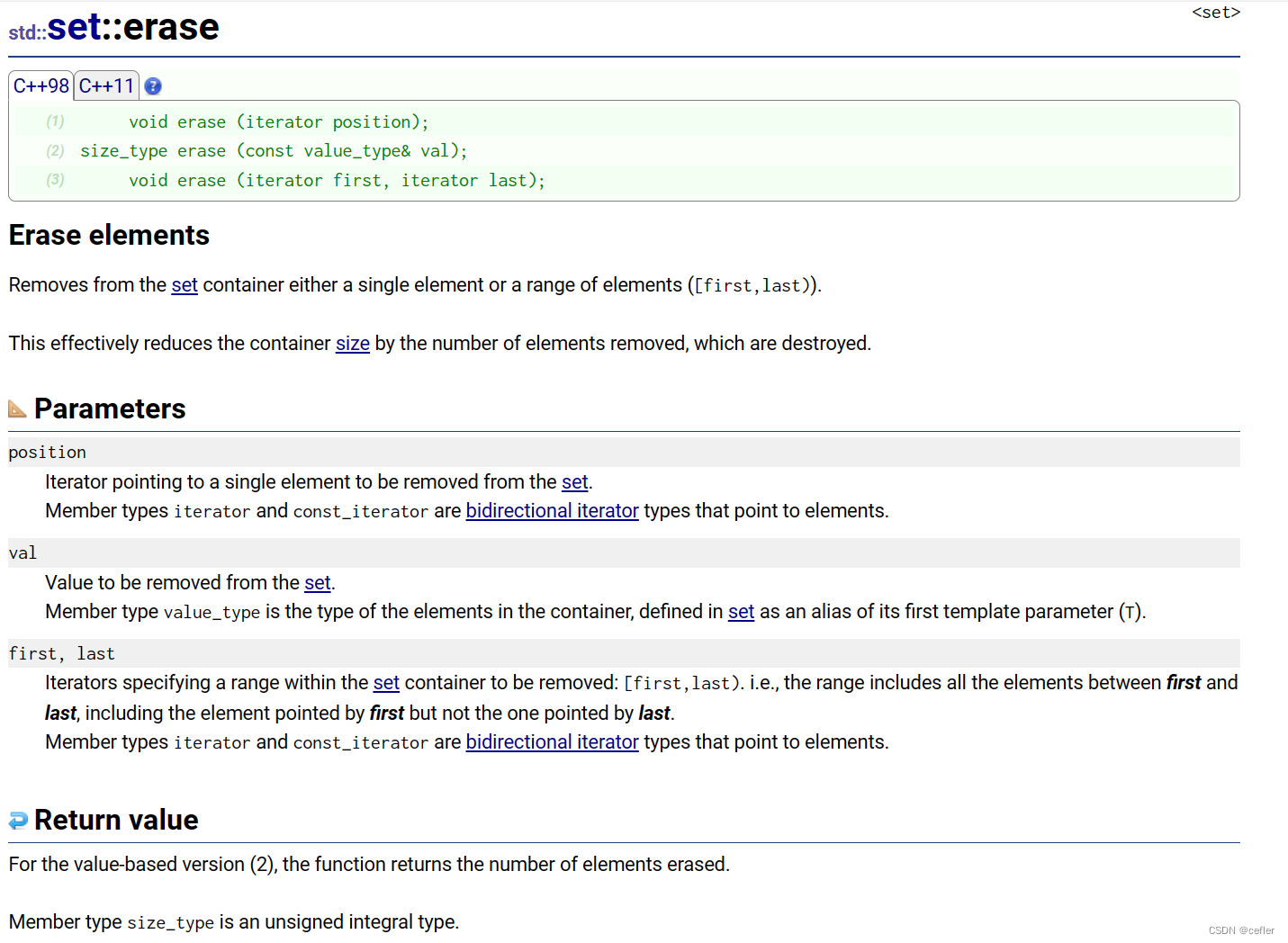
erase
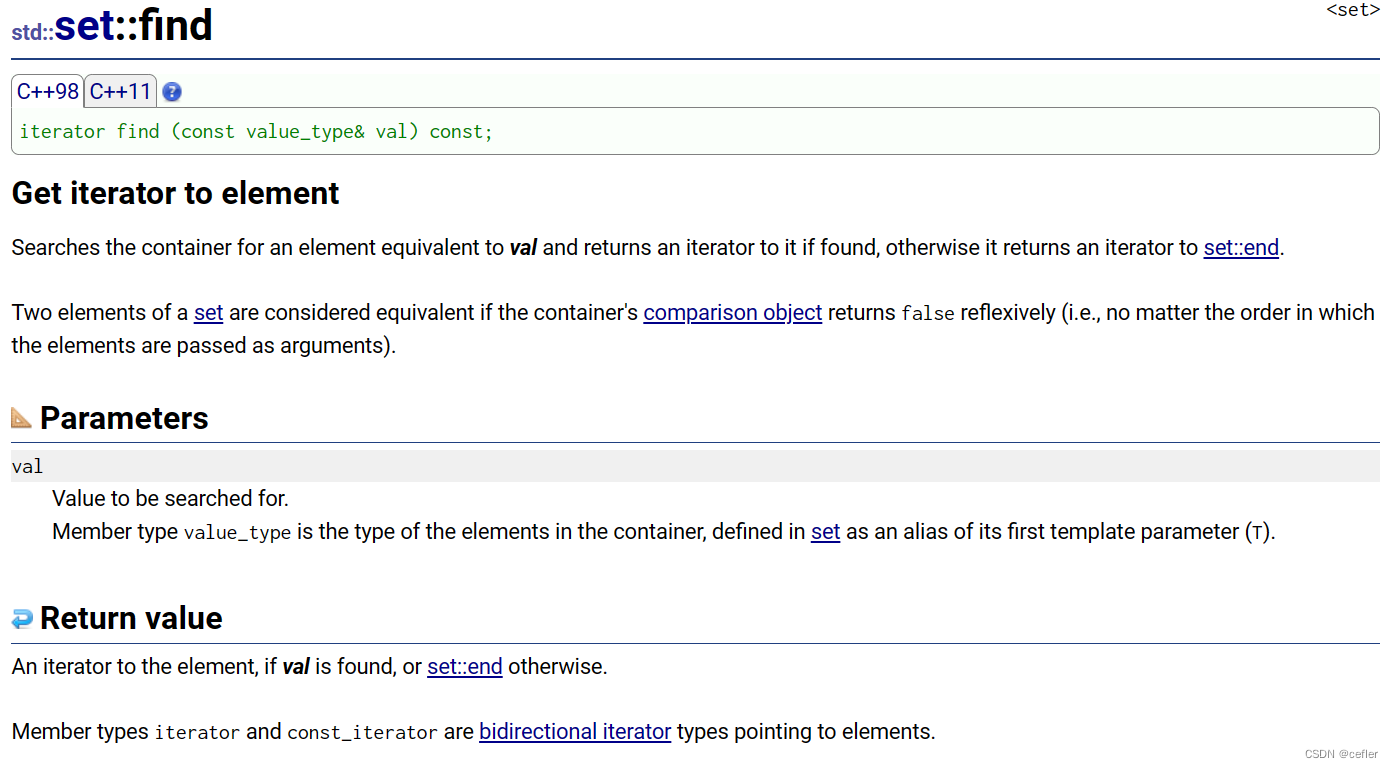
find
lower_bound和upper_bound
std::set 是 C++ 标准库中的一个关联式容器,它用于存储一组按照特定顺序排列的唯一元素。lower_bound 和 upper_bound 是 std::set 提供的两个成员函数,用于在集合中进行范围查询。
lower_bound函数返回一个迭代器,指向集合中第一个不小于给定值的元素。upper_bound函数返回一个迭代器,指向集合中第一个大于给定值的元素。
这两个函数都接受一个参数,即要搜索的值。它们利用二分查找算法在集合中进行搜索,并返回满足特定条件的元素的迭代器。如果在集合中找不到符合条件的元素,那么它们将返回一个指向集合末尾的迭代器。
下面是使用 lower_bound 和 upper_bound 的示例:
#include <iostream>
#include <set>
int main() {
std::set<int> mySet = {10, 20, 30, 40, 50};
auto itLower = mySet.lower_bound(25); // 返回大于等于 25 的第一个元素的迭代器
auto itUpper = mySet.upper_bound(35); // 返回大于 35 的第一个元素的迭代器
for (auto it = itLower; it != itUpper; ++it) {
std::cout << *it << " "; // 输出结果为 30
}
return 0;
}
在上述示例中,lower_bound(25) 返回的迭代器指向值为 30 的元素,因为 30 是第一个不小于 25 的元素。而 upper_bound(35) 返回的迭代器也指向值为 30 的元素,因为 30 是第一个大于 35 的元素。
和迭代器一样——左闭右开
这两个函数常用于范围查询,通过结合使用它们可以方便地获取某个范围内的元素。需要注意的是,lower_bound 和 upper_bound 函数只适用于有序集合,如 std::set 和 std::map。对于无序容器,例如 std::unordered_set 和 std::unordered_map,可以使用 equal_range 函数来实现类似的功能。
count
std::set 是 C++ 标准库中的一个关联式容器,用于存储一组按照特定顺序排列的唯一元素。count 是 std::set 提供的成员函数之一,用于计算集合中特定值的出现次数。
count 函数接受一个参数,即要搜索的值,并返回该值在集合中的出现次数。由于 std::set 中的元素是唯一的,所以它只能返回 0 或 1。如果指定的值存在于集合中,count 函数将返回 1;否则,它将返回 0。
下面是使用 count 函数的示例:
#include <iostream>
#include <set>
int main() {
std::set<int> mySet = {10, 20, 30, 40, 50};
int value1 = 30;
int value2 = 60;
int count1 = mySet.count(value1);
int count2 = mySet.count(value2);
std::cout << "Value " << value1 << " appears " << count1 << " time(s) in the set." << std::endl;
std::cout << "Value " << value2 << " appears " << count2 << " time(s) in the set." << std::endl;
return 0;
}
在上述示例中,count1 的值为 1,因为值为 30 的元素在集合中出现了一次。而 count2 的值为 0,因为值为 60 的元素不在集合中。
count 函数对于判断集合中是否存在某个特定值非常有用。如果只是关心某个值是否存在而不需要知道具体的出现次数,可以使用 find 函数来实现类似的功能。find 函数返回一个迭代器,指向集合中与给定值相等的元素,如果找不到则返回指向集合末尾的迭代器。通过检查返回的迭代器是否等于集合末尾的迭代器,可以确定值是否存在于集合中。
总结起来,count 函数用于计算集合中特定值的出现次数,只能返回 0 或 1。如果只是需要判断值是否存在,可以使用 find 函数。
equl_range对于set和multiset的不同意义
equal_range 是 C++ 标准库中的一个函数模板,用于在有序关联容器中查找某个特定值的范围。对于 std::set 和 std::multiset 这两个有序关联容器,equal_range 的意义稍有不同。
-
对于
std::set:- 如果指定的值存在于集合中,
equal_range函数将返回一个包含两个迭代器的std::pair对象。这两个迭代器分别指向集合中的第一个等于给定值的元素和最后一个等于给定值的元素之后的位置。 - 如果指定的值不存在于集合中,
equal_range函数将返回一个std::pair对象,其中两个迭代器都等于集合末尾的迭代器,表示未找到匹配的元素。
- 如果指定的值存在于集合中,
-
对于
std::multiset:equal_range函数始终返回一个std::pair对象,其中两个迭代器分别指向集合中第一个等于给定值的元素和最后一个等于给定值的元素之后的位置。即使指定的值在集合中不存在,equal_range也会返回一个合法的范围,其中两个迭代器相等且都等于集合末尾的迭代器。
下面是使用 equal_range 函数的示例:
#include <iostream>
#include <set>
int main() {
std::multiset<int> mySet = {10, 20, 30, 30, 40, 50};
int value1 = 30;
int value2 = 60;
auto range1 = mySet.equal_range(value1);
auto range2 = mySet.equal_range(value2);
std::cout << "Elements equal to " << value1 << " in the set: ";
for (auto it = range1.first; it != range1.second; ++it) {
std::cout << *it << " "; // 输出结果为 30 30
}
std::cout << std::endl;
std::cout << "Elements equal to " << value2 << " in the set: ";
for (auto it = range2.first; it != range2.second; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
在上述示例中,range1 是一个 std::pair 对象,其中 range1.first 指向值为 30 的第一个元素,而 range1.second 指向值为 30 的最后一个元素之后的位置。因为在集合中存在两个值为 30 的元素,所以输出结果为 30 30。而 range2 也是一个 std::pair 对象,其中的两个迭代器都等于集合末尾的迭代器,表示集合中不存在值为 60 的元素。
总结起来,equal_range 函数用于在有序关联容器中查找某个特定值的范围。对于 std::set,返回的范围只有在指定值存在时才是有效的;而对于 std::multiset,无论指定值是否存在,都会返回一个合法的范围。
👉🏻map
map官方文档:map
map 是 C++ 标准库中的一个关联式容器,提供了一种将键和值相关联的映射关系。每个元素都包含一个键和一个值,通常使用键来快速访问对应的值。
与数组不同,map 中的键不必是连续的数字。键可以是任何可比较类型,例如整数、字符串或自定义类型。map 中的元素是按照键进行排序的。
在 map 中,每个键只能对应一个值。如果插入一个已经存在的键,则会覆盖原有的值。
map默认以key进行字典序排序
map 的声明如下:
template < class Key, class T, class Compare = less<Key>, class Allocator = allocator<pair<const Key, T>> > class map;
其中,Key 是键的类型,T 是值的类型,Compare 是用于比较键的函数对象类型,默认为 std::less<Key>,表示使用 < 运算符进行比较。Allocator 是分配器类型,用于分配内存空间,默认为 std::allocator<std::pair<const Key, T>>。
map 提供了多种操作方法,包括插入、删除、查找等。下面是一些常见操作的示例:
#include <iostream>
#include <map>
int main() {
// 创建一个 map 对象
std::map<std::string, int> myMap;
// 插入元素
myMap.insert(std::make_pair("Alice", 23));
myMap.insert(std::make_pair("Bob", 25));
myMap.insert(std::make_pair("Charlie", 27));
// 查找元素
auto it = myMap.find("Alice");
if (it != myMap.end()) {
std::cout << "Found Alice, age is " << it->second << std::endl;
}
// 使用下标访问元素
std::cout << "Bob's age is " << myMap["Bob"] << std::endl;
// 删除元素
myMap.erase("Charlie");
// 遍历所有元素
for (const auto& item : myMap) {
std::cout << item.first << ": " << item.second << std::endl;
}
return 0;
}
在上述示例中,我们首先创建了一个 map 对象 myMap,并通过 insert 函数向其中插入三个元素。然后使用 find 函数查找键为 "Alice" 的元素,并输出其值。接着使用下标运算符访问键为 "Bob" 的元素的值,并输出到控制台。最后使用 erase 函数删除键为 "Charlie" 的元素,并使用范围 for 循环遍历所有元素并输出键和值。
总结一下,map 是一个非常有用的关联式容器,用于将键和值相关联形成映射关系。它提供了多种操作方法,包括插入、删除、查找等。
insert

the return value of single element:
The single element versions (1) return a pair, with its member pair::first set to an iterator pointing to either the newly inserted element or to the element with an equivalent key in the map. The pair::second element in the pair is set to true if a new element was inserted or false if an equivalent key already existed.
即返回一个pair类型,pair的first是一个新插入元素的迭代器,如果在map中该key值已经存在,不能插入,则返回该key值在map中的位置。
即插入不成功,insert可以起到一个查找的作用。
operator[]
map 的 operator[] 用于访问特定键对应的值。它的使用方式类似于数组下标运算符 [],但是可以指定任意类型的键,而不仅仅是数字索引。如果指定的键不存在,则会自动插入一个默认值,并返回该默认值的引用。
下面是 map 的 operator[] 的简单示例:
#include <iostream>
#include <map>
int main() {
std::map<std::string, int> myMap;
// 使用 operator[] 进行赋值和访问
myMap["Alice"] = 23;
myMap["Bob"] = 25;
myMap["Charlie"] = 27;
// 输出所有元素
for (const auto& item : myMap) {
std::cout << item.first << " : " << item.second << std::endl;
}
// 访问不存在的键
std::cout << "David's age is " << myMap["David"] << std::endl;
return 0;
}
在上述示例中,我们首先创建了一个 map 对象 myMap,并使用 operator[] 方法向其中插入三个键值对。然后使用范围 for 循环输出所有元素。接着使用 operator[] 访问一个不存在的键 "David",此时会自动插入一个默认值 0,并返回其引用。
map 的 operator[] 实现原理是通过使用 find 函数查找指定键是否存在,如果存在则返回对应的值的引用,如果不存在则插入一个默认值,并返回该默认值的引用。这种实现方式的时间复杂度为
O
(
log
n
)
O(\log n)
O(logn),与 find 函数相同,但是比较方便使用。
需要注意的是,使用 operator[] 访问一个不存在的键时,会自动插入一个默认值。如果不需要自动插入,则应该使用 find 或 at 方法进行访问,避免不必要的插入操作。
总结一下,map 的 operator[] 用于访问特定键对应的值,实现原理是通过使用 find 函数查找指定键是否存在,如果不存在则插入一个默认值,并返回该默认值的引用。它的使用方式类似于数组下标运算符,但可以指定任意类型的键。需要注意的是,访问不存在的键时会自动插入一个默认值。希望这个解释对你有所帮助!如果还有其他问题,请继续提问。
test
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include<map>
using namespace std;
void test1()
{
map<string, string> dict;
dict.insert(pair<string, string>("world", "世界"));
dict.insert(make_pair("hello", "你好"));//make_pair更方便
for (auto& e : dict)//这里加上引用,是因为e的值是pair类型,若每次迭代访问都要拷贝构造消耗太大,所以用引用就可以不用拷贝构造
{
cout << e.first << " ";
cout << e.second << endl;
}
}
void test2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
map<string, int> countMap;
for (auto str : arr)
{
map<string, int>::iterator ret = countMap.find(str);//这里类型觉得冗长可以用auto
if (ret == countMap.end())
{
//找不到插入
countMap.insert(make_pair(str, 1));
}
else
{
(*ret).second++;//ret->second也可以
}
}
//实际上,上述操作用countMap[str]++就可以完成
for (auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
}
int main()
{
test2();
return 0;
}
👉🏻multiset
multiset官方文档:multiset
概念:
- multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
- 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成
的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器
中进行修改(因为元素总是const的),但可以从容器中插入或删除。 - 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则
进行排序。 - multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭
代器遍历时会得到一个有序序列。 - multiset底层结构为二叉搜索树(红黑树)。
注意:
- multiset中再底层中存储的是<value, value>的键值对
- mtltiset的插入接口中只需要插入即可
- 与set的区别是,multiset中的元素可以重复,set是中value是唯一的
- 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
- multiset中的元素不能修改
- 在multiset中找某个元素,时间复杂度为 O ( l o g 2 N ) O(log_2 N) O(log2N)
- multiset的作用:可以对元素进行排序
👉🏻multimap
multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以
重复的。
- multimap中的key是可以重复的。
- multimap中的元素默认将key按照小于来比较
- multimap中没有重载operator[]操作:因为一个key,可能对应多个val值。
- 使用时与map包含的头文件相同
👉🏻OJ题目
前K个高频单词
原题链接:前K个高频单词
将单词出现频率由高到低排序:使用std::sort,并自定义对比方法
class Solution {
public:
struct compare
{
bool operator()(const pair<string,int>& p1,const pair<string,int>& p2)
{
return p1.second>p2.second||(p1.second==p2.second&&p1.first<p2.first);//||后面的是为了稳定排序,使得map已经用字典序排序排好的序列位置不发生变化,依然按照从小到大
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
//用map进行先进行存储
map<string,int> dict;
for(auto& str:words)
{
dict[str]++;
}
//排序
vector<pair<string,int>> sortV(dict.begin(),dict.end());
sort(sortV.begin(),sortV.end(),compare());
vector<string> v(k);
for(int i = 0;i<k;i++)
{
v[i] = sortV[i].first;
}
return v;
}
};
这边不能直接用sort对map类型直接排序原因:

sort支持随机迭代器
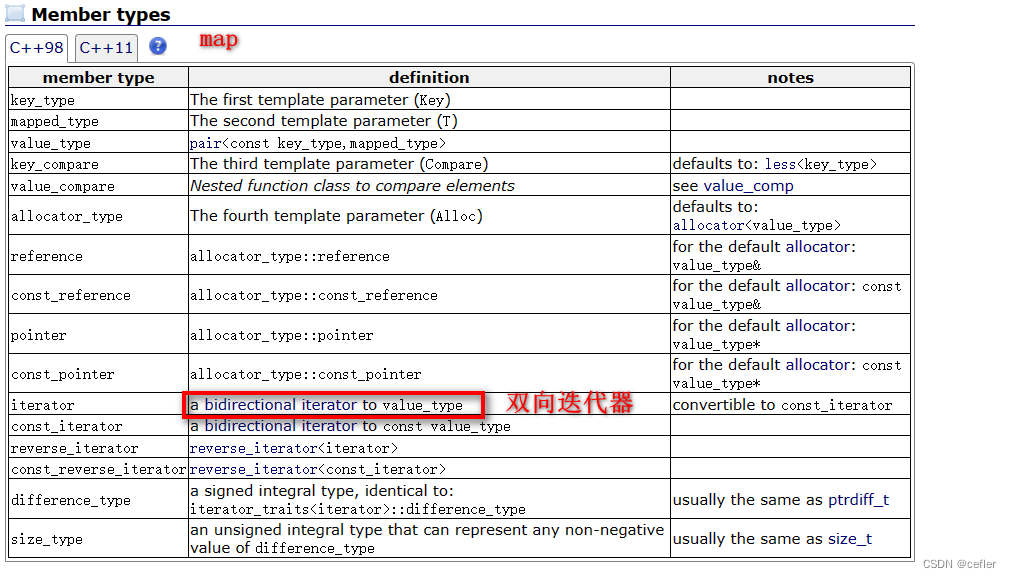
map的迭代器是双向迭代器,而只有vector的迭代器才能符合sort的迭代器。
关于单向迭代器,双向迭代器,随机迭代器。
迭代器的需求越来越多,但是遵循:一个迭代器的接口是否能够使用,取决于你传进来的迭代器功能是否满足接口的迭代器的所有功能。比如,接口迭代器为随机,传单向不行,因为单向只具备++,没有–/+/-功能,但随机传给单向可以,因为我功能齐全。

两个数组的交集
原题链接:两个数组的交集
先分别去重
1.取交集,双指针:相等++,不相等,小的++,因为小的必然不是交集
2.找差集,双指针:相等++,小的++,小的是差集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> set1,set2;
for(auto e:nums1)
{
set1.insert(e);
}
for(auto e:nums2)
{
set2.insert(e);
}
//双指针找交集
set<int>::iterator it1 = set1.begin(),it2 = set2.begin();
vector<int> common;
while(it1!=set1.end()&&it2!=set2.end())
{
if(*it1<*it2)
{
it1++;
}
else if(*it2<*it1)
{
it2++;
}
else
{
common.push_back(*it1);
it1++;
it2++;
}
}
return common;
}
};
如上便是本期的所有内容了,如果喜欢并觉得有帮助的话,希望可以博个点赞+收藏+关注🌹🌹🌹❤️ 🧡 💛,学海无涯苦作舟,愿与君一起共勉成长</font

















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









