







 本文探讨了基于管道化和事件驱动模型的Web请求处理,包括业务架构设计、流程与角色说明、问题及解决方案。通过两种基础管道体系设计,详细阐述了任务的创建、执行和管理过程,旨在解决传统HTTP请求生命周期管理问题,提高处理效率。
本文探讨了基于管道化和事件驱动模型的Web请求处理,包括业务架构设计、流程与角色说明、问题及解决方案。通过两种基础管道体系设计,详细阐述了任务的创建、执行和管理过程,旨在解决传统HTTP请求生命周期管理问题,提高处理效率。
Author:放翁(文初)
Date: 2010/11/25
Email:fangweng@taobao.com
mblog: http://t.sina.com.cn/fangweng
blog: http://blog.csdn.net/cenwenchu79/
这篇文章将会从问题,技术背景,设计实现,代码范例这些角度去谈基于管道化和事件驱动模型的Web请求处理。建议从头看,能够从概念上更多的去理解和碰撞,其中的一些描述和例子也许不是很恰当,也希望得到更多的反馈。
业务架构设计:
基于上述问题,通过两步走来解决。首先采用支持打破传统http request生命周期管理的Web容器(很多人说可以自己写,其实Web容器写起来并不是最麻烦的,如何做好兼容和照顾好每一个细节才是漫长发展的道路)。其次在容器新的线程生命周期管理基础上封装业务框架,为开发者屏蔽底层异步化和事件驱动模式带来的复杂流程管理内容。

Pipe Service Framework:
基础管道体系:
很多时候设计和实现都会有很多细节上的差异,而这些差异往往是在事实验证后对体系的一种修订,也许修订后的结构不如修订前的清晰和优雅,但是确实在性能和结构上找到了平衡点,下面就看看两个基础管道体系的设计,后一个是前一个的演进。
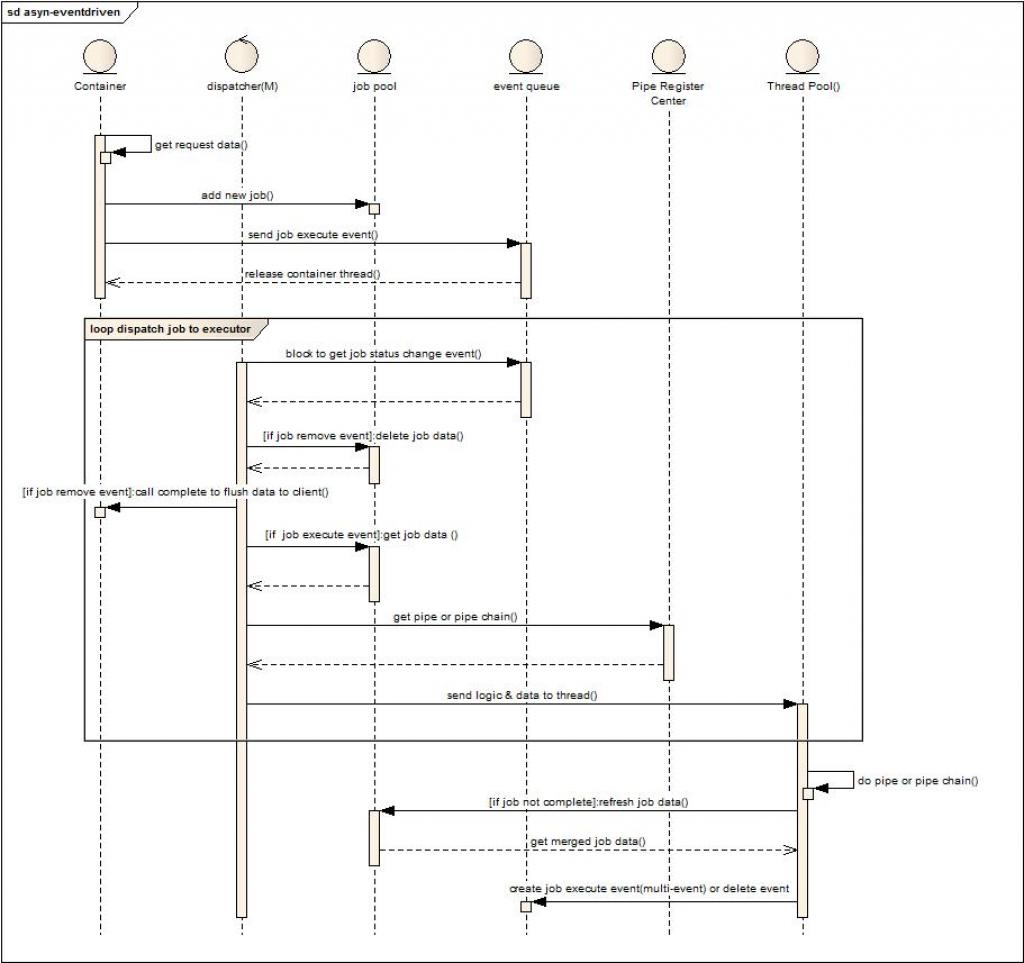
流程与角色说明:
角色分成:Container(传统的容器),dispatcher(任务派发线程数量根据性能要求可以是1-m个),job pool(存储任务数据的本地缓存),event queue(任务状态发生变化的事件存储队列),pipe register center(管道链注册中心,根据job的自描述信息给出相关处理的单个管道或者管道链),thread pool(用于处理业务请求的线程池)
流程描述如下:
1. 容器解析请求数据。
2. 创建任务并存储到job pool。
3. 发送job执行消息到消息队列。
4. 释放容器线程,挂起请求资源。
5. Dispatcher阻塞方式的从event queue获取事件消息。
6. 如果是删除任务事件消息,则将剩余未发送数据flush到客户端,结束本次Http会话。(删除任务消息是在任务走完所有管道或者任务执行超时或者任务执行失败产生)
7. 如果是执行任务消息事件,则从job pool获取任务数据。
8. 根据任务信息去pipe register center获取pipe或者pipe chain。
9. 将任务数据和管道信息发送给线程池。
10. 线程池分配线程执行任务,如果当前pipe chain执行后并没有完成job,则将job
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9228
9228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









