







导读
目标错误泛化指AI系统的能力成功泛化但其目标没有按预期泛化,因此系统有能力追求错误的目标。
上篇介绍的一种方法是对抗训练。而本篇介绍另一种方法是开发可解释性技术,旨在深入了解深度神经网络是如何或为何起作用的。有两种不同的方法来解释神经网络:一是建立一个内在可解释的模型,二是给定一个已经训练好的模型生成事后解释。虽然前者是高风险领域的重要方法,但它可能并不总是可行,我们希望能理解的性能最高的模型通常可能不是具备内在可解释性架构的。在这种情况下,我们必须依赖事后可解释性方法。
我们将介绍事后可解释性其中的两种方法:一是机制可解释性,旨在理解单个神经元水平的网络[1-3];二是基于概念的可解释性,侧重于自动探测并可能修改存储在神经网络中的人类可解释概念的技术[4-7]。这些在第13篇Christiano的分类中属于“透明度”(transparency)。但需说明的是,可解释性技术可广泛促进更安全和对齐的技术,不限于应对目标错误泛化。
1. 机制可解释性 (Mechanistic interpretability)
核心思想:
机制可解释性是对神经网络进行逆向工程的研究,它试图理解在每一层实现的精确算法及其产生的表示,以了解它们的工作原理。
其主要动机是:把深度学习当作自然科学来理解[1]。
这种方法的早期工作侧重于使用矩阵分解和特征可视化方法来理解视觉网络中间层的表示[8-9]。新近的工作集中在多模态网络的表示[10],以及神经网络算法的通路级理解[1][11]。这些方法表明网络学习的表征和人类可理解的概念之间存在一定程度的一致性。
机制可解释性是一个较新的领域,因其能帮助我们了解AI系统的工作原理并识别潜在问题,有可能在开发安全且对齐的AI方面发挥重要作用。Anthropic将其作为AI安全研究的主要方向之一[12]。
相关工作:
(1) Feature visualization,特征可视化 (Olah et al., 2017)[13]
Anthropic联合创始人、前OpenAI研究员Chris Olah等提出的特征可视化是一组用于对网络中不同神经元的不同神经元进行定性的理解的技术。它旨在通过生成单个神经元或层学习到的特征的可视化来揭示这些网络在处理数据时“看到”或“学习”了什么。
这种方法允许我们稍微“站在神经网络内部”,看到神经网络在某一具体时刻如何决策,及其如何影响最终输出。例如,我们可以看到神经网络如何检测耷拉的耳朵,以提高其判断一张图像是“拉布拉多犬”还是“比格犬”的概率。
文章演示了CNN中的单个神经元可以学习检测各种特征,例如简单的边缘、纹理或更复杂的模式。随着深入网络,神经元倾向于在简单特征的基础上学习更抽象和高级的特征。
特征可视化也有其局限性,它需要手动搜索才能找到有趣的神经元,并且只能说明非常复杂的网络的一小部分,需要其他方法来更系统地理解神经网络学习和计算。

特征可视化通过生成示例来回答相关网络正在寻找什么的问题

归因通过研究示例的哪一部分负责以特定方式激活网络
(2) Zoom in: An introduction to circuits,探索神经通路从低层特征中构建高层特征的表征 (Olah et al., 2020)[1]
Chris Olah等介绍了人工神经网络中通路(circuits)的概念。在图像识别等任务中,通路是网络中执行特定任务或计算的功能单元。通过理解这些通路,研究人员可以深入了解神经网络的工作原理以及如何提高其性能。
传统显微镜让人类看到细胞,由此产生了细胞生物学,以一种新的研究方式为理解复杂生物体提供基础。作者用显微镜的类比来说明如何通过通路来实现不同层次的理解。低倍率提供了更广阔的神经网络视野,而高倍率则可以更深入地了解特定通路的内部工作原理。
为了演示这一概念,作者分析了广泛用于图像识别任务的CNN架构,如何由多层神经元组成,每个神经元都具有特定功能,例如特征检测、池化和归一化。推荐读者阅读原文网页,能对这些概念获取更直观的理解。
可解释性领域在定义、方法和评估标准方面缺乏共识。通过研究通路如何实现功能可以带来更多的科学严谨性。但是通路仅限于小的子图,整体网络行为非常复杂。

通过研究神经元之间的联系,可以在神经网络的权重中找到有意义的算法
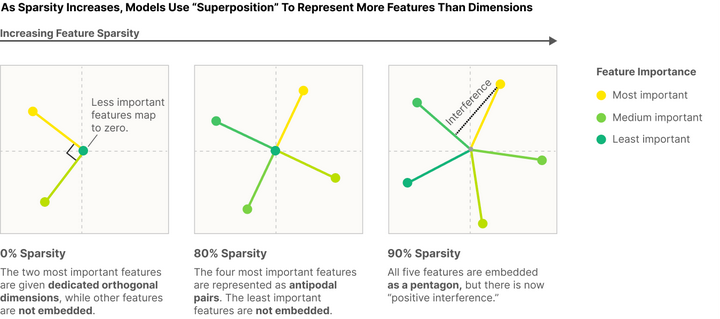
(3) The Superposition Hypothesis,“叠加假设”与神经元的多义性 (Elhage et al., 2022)[14]
Anthropic研究员Nelson Elhage等试图理解为什么某些神经元存在多义性,即一个神经元可能代表多种人类可理解的概念,通过简化的Transformer“玩具模型”(用于学习和研究的简单模型或任务)进行了研究。
关于多义神经元的成因,作者认为是由“叠加”效应引起的,通路在一个神经元中存储了多个特征,大概是为了将更多特征打包到其有限可用的神经元中。
关键的见解是,虽然单个神经元组建具有模棱两可的表示,但它们可以通过多个模棱两可的表示的组合来实现明确定义的逻辑功能。 网络本身并不“理解”人类意义上的逻辑,但其分布式激活模式在物理上实现了相应的逻辑关系。
作者的初步证据表明叠加效应可能与对抗样本和顿悟现象(grokking)有关,并且可能还提出了专家混合模型性能的理论。

神经元 4e:55 对猫脸、汽车前部和猫腿做出反应
神经元 4e:55 对猫脸、汽车前部和猫腿做出反应
2. 基于概念的可解释性 (Concept-based interpretability)
核心思想:
事后可解释性的另一种方法建立在网络探针的思想之上,侧重于使用人类可理解的概念来解释用户能够理解的神经网络决策[15-17]。
其主要动机是:探究人类能从复杂的神经网络中具体学到什么。这个问题既有科学意义,又有实际意义。如果强大神经网络与人类可理解的概念没有关联,那么我们理解其决策的真实解释的能力将受到限制,最终限制了我们可以通过神经网络的可解释性所能实现的目标[18]。
如果用户是领域专家,他们可以指定复杂的特定领域概念,从而帮助他们更详细地探测网络运作和理解网络决策。基于概念的可解释性已成功应用于复杂的科学、医学和国际象棋等领域。
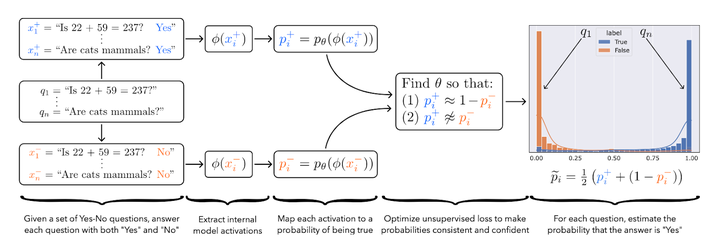
(1) Discovering latent knowledge,无需真实数据即可识别模型判断陈述是真是假 (Burns et al., 2022)[6]
在一般情况下,我们不只希望语言模型提供最可能的输出,还希望是实际上真实的输出。
但语言模型输出可能与真相不符:如果通过模仿来学习训练模型,即使模型实际上知道正确的答案是什么,它也会倾向于重复人类的错误,这是一个不对齐的例子;如果训练其生成人类评价高的文本,它们可能会输出人类评估者无法检测到的错误。
加州大学伯克利分校博士生Collin Burns等人的解决方案将是查看模型的潜在表征,通过以纯粹无监督的方式直接在语言模型的内部激活中寻找潜在知识来规避这个问题。
他们设计了一种对比-一致性搜索(contrast-consistent search)算法,利用模型的真实陈述必须满足逻辑一致性的要求来解决这个问题,例如一个陈述及其否定应具有相反的值。
CCS:对比-一致性搜索
(2) Linear classifier probes,线性探针是基于概念的可解释性的重要工具 (Alain et al., 2016)[19]
MILA研究员Guillaume Alain等通过在神经网络中添加线性分类器“探针”,来理解深度网络层次之间信息量的变化。
该方法监测模型每一层的特征,并衡量它们对分类的适合程度,这有助于我们更好地理解中间层的作用和动态。
探针完全独立于模型本身进行训练,可以将它们想象成用于同时测量许多不同位置温度的温度计。其核心思想是,如果我们允许“测量仪器”有自己的可训练参数,我们可以根据许多独立层的特征报告一些有趣的指标。
作者将此技术应用于Inception v3和Resnet-50模型,并展示了如何使用它们来表征不同层、调试不良模型,或者了解在一个表现良好的模型中训练是如何进行的。
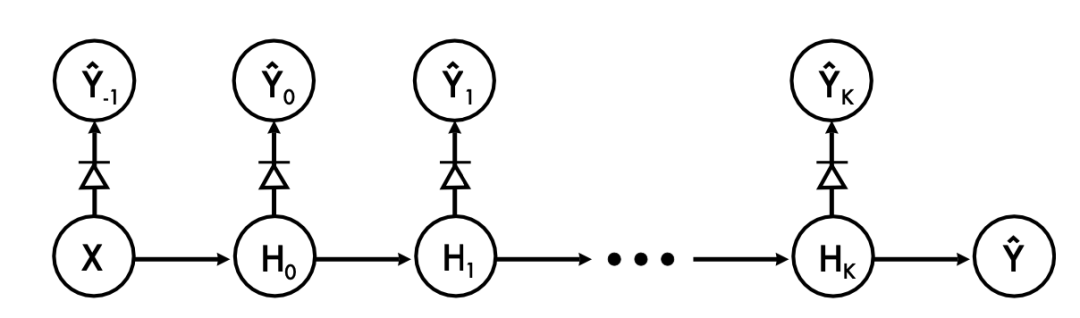
探针被添加到模型的每一层。这些额外的探针不应该改变模型的训练,作者通过带箭头的二极管符号来代表梯度不会通过这些连接反向传播
(3)Acquisition of chess knowledge,理解AlphaZero对人类国际象棋概念发展的案例研究(McGrath et al., 2021)[18]
DeepMind使用基于概念的可解释性技术来理解AlphaZero对人类国际象棋概念的发展。
为了有效测试是否出现了人类可理解概念的,理想情况是找到一个在不使用人类标记数据的情况下表现出优异性能的领域。因AlphaZero通过自我对弈进行训练,且在国际象棋、围棋和将棋3个领域中都表现出超越人类的水平,正好满足这两个要求,提供了一个难得的机会来研究一个在复杂领域中表现超人水平的系统。
在本项目中合作的国际象棋特级大师Vladimir Kramnik一同证明了在AlphaZero的神经网络中存在复杂的人类可理解的概念,这为进一步研究AlphaZero网络奠定了坚实的基础。
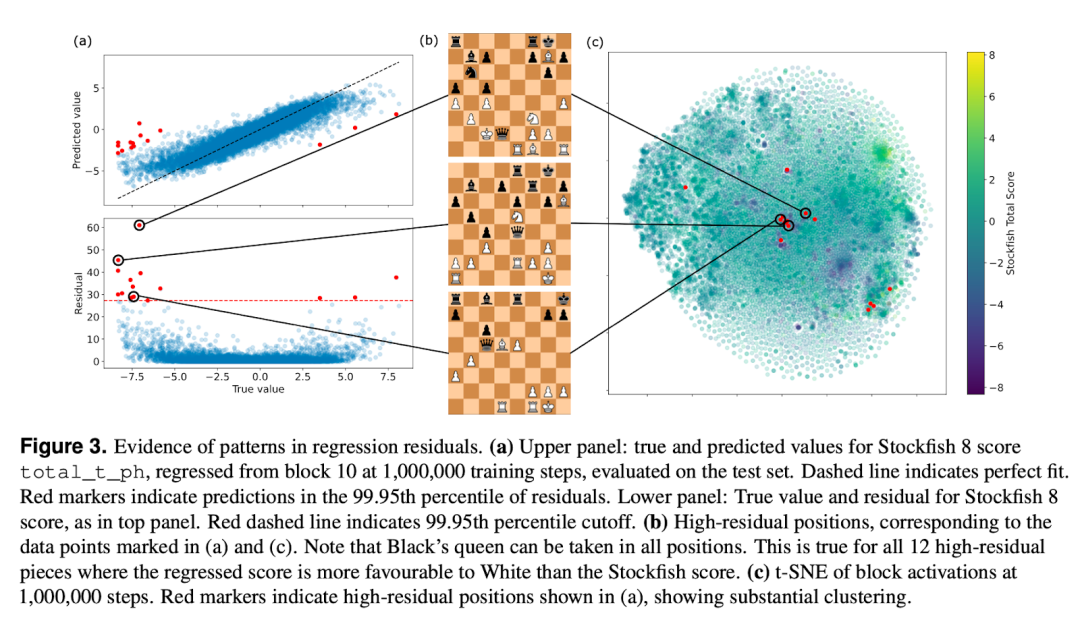
回归残差中的模式证据
(4) Locating and Editing Factual Associations in GPT,语言模型内的事实知识可被修改(Meng et al., 2022)[7]
GPT等自回归语言模型里存储着大量的事实知识,例如语言模型可以正确的预测埃菲尔铁塔所在的城市是巴黎市。一个自然的问题是,这些知识存储在何处?是否可被修改?
MIT研究生Kevin Meng等展示了如何基于概念的可解释性以语义上有意义的方式修改神经的权重。他们发现GPT中的事实知识对应于可以直接编辑的局部计算。通过对GPT的一小部分参数进行小的改变就可以修改其内部的知识,以教它反事实“埃菲尔铁塔在罗马”。
具体方法分两步:1)定位:提出因果追踪(Casual Tracing)方法,衡量每个神经元对这条事实知识的影响,筛选出储存了这条知识的神经元;2)编辑:引入ROME(Rank-One Model Editing)方法,将MLP视为简单的键值(key-value)存储,关联主题与知识,通过检索与键对应的值来调用关联,直接写入新的键值对,即可为模型注入新的知识。
这种方法间接探索了神经网络的可解释性,但步骤相对繁琐,一次只能编辑一个事实知识。后续的工作中,作者开发了一种改进的直接编辑方法(MEMIT),并将其扩展到可以同时更新数千个记忆,比以前的方法提高了几个数量级[20]。

回归残差中的模式证据
更多阅读:
机制可解释性方面,前Anthropic研究员Neel Nanda整理了入门知识[21]和200个具体的开放性问题[22]。
基于概念的可解释性方面,谷歌大脑研究科学家Been Kim等引入特征归因之外的可解释性[16],使用概念归因向量进行定量测试。
Redwood Research研究团队提出因果清理(causal scrubbing)[23],一种严格测试可解释性假设的方法。
更具推测性的议题方面,Paul Christiano提出了阐释潜在知识(Eliciting latent knowledge)[24],此问题可以被视为可解释性研究的长期目标。
参考资料:
[1] Zoom In: An Introduction to Circuits. (Olah et al., 2020)
https://distill.pub/2020/circuits/zoom-in/
[2] A mathematical framework for transformer circuits. Transformer Circuits Thread (Elhage et al., 2021)
https://transformer-circuits.pub/2021/framework/index.html
[3] Interpretability in the wild: a circuit for indirect object identification in gpt-2 small (Wang et al., 2022)
https://arxiv.org/abs/2211.00593
[4] Towards automatic concept-based explanations (Ghorbani et al., 2019), NeurIPS 2019
https://arxiv.org/abs/1902.03129
[5] Towards robust interpretability with self-explaining neural networks (Melis et al., 2018), NeurIPS 2018
https://arxiv.org/abs/1806.07538
[6] Discovering latent knowledge in language models without supervision (Burns et al., 2022)
https://arxiv.org/abs/2212.03827
[7] Locating and Editing Factual Associations in GPT (Meng et al., 2022), NeurIPS 2022
http://arxiv.org/abs/2202.05262
[8] The building blocks of interpretability (Olah et al., 2018)
https://distill.pub/2018/building-blocks/
[9] Activation atlas (Carter et al., 2019)
https://distill.pub/2019/activation-atlas/
[10] Multimodal neurons in artificial neural networks (Goh et al., 2021)
https://distill.pub/2021/multimodal-neurons
[11] Thread: Circuits (Cammarata et al., 2020)
https://distill.pub/2020/circuits
[12] Core Views on AI Safety: When, Why, What, and How (Anthropic, 2023)
https://www.anthropic.com/index/core-views-on-ai-safety
[13] Feature visualization (Olah et al., 2017) https://distill.pub/2017/feature-visualization/
[14] Toy models of superposition (Elhage et al., 2022)
https://transformer-circuits.pub/2022/toy_model/index.html#motivation
[15] Network dissection: Quantifying interpretability of deep visual representations (Bau, 2017), CVPR 2017
https://arxiv.org/abs/1704.05796
[16] Quantitative testing with concept activation vectors (TCAV) (Kim et al., 2018)
https://arxiv.org/abs/1711.11279
[17] Concept bottleneck models (Koh et al., 2020), ICML 2020
https://arxiv.org/abs/2007.04612
[18] Acquisition of chess knowledge in AlphaZero (McGrath et al., 2021), PNAS 2022
https://arxiv.org/abs/2111.09259
[19] Understanding intermediate layers using linear classifier probes (Alain and Bengio, 2016), ICLR 2017
https://arxiv.org/abs/1610.01644
[20] Mass Editing Memory in a Transformer(Meng et al., 2022), ICLR 2023
https://arxiv.org/abs/2210.07229
[21] Concrete Steps to Get Started in Transformer Mechanistic Interpretability (Nanda, 2022)
https://www.neelnanda.io/mechanistic-interpretability/getting-started
[22] 200 Concrete Open Problems in Mechanistic Interpretability (Nanda, 2022)
https://www.neelnanda.io/concrete-open-problems
[23] Causal Scrubbing: a method for rigorously testing interpretability hypotheses (Redwood Research, 2022)
https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/causal-scrubbing-a-method-for-rigorously-testing
[24] Eliciting latent knowledge (Christiano, 2021)
https://ai-alignment.com/eliciting-latent-knowledge-f977478608fc

关于安远AI
安远AI是一家专注AI安全和治理的咨询机构。我们的使命是引领人机关系走向安全、可信、可靠的未来。
我们面向大模型和通用人工智能安全和对齐问题进行风险研判、建立技术社区、开展治理研究、提供战略咨询以及推动国际交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









