







来源:AI 科技大本营(ID:rgznai100)
2024 年,人工智能领域迎来一个历史性时刻:深度学习先驱 Geoffrey Hinton 与 John Hopfield 共同斩获诺贝尔物理学奖,这是 AI 研究首次获得物理学最高荣誉,标志着计算科学与物理学的历史性融合。
近日,Meta 首席 AI 科学家、图灵奖得主杨立昆(Yann LeCun)接受了加州大学圣地亚哥分校杰出物理学教授 Brian Keating 的专访。由于是和物理学专家的对话,所以与前段时间对话知名记者 Kara Swisher 明显不同,LeCun 的许多回答直指 AI 技术前沿,面对物理学家大秀了一番自己在物理方面的造诣。
当 Keating 以宇宙学家的视角,用爱因斯坦 1907 年的自由落体思想实验挑战 AI 的创造力时,对话瞬间升温:“没有物理实体的AI系统,如何才能像爱因斯坦那样构建新的物理定律?”作为西蒙斯天文台首席研究员、著名的宇宙微波背景辐射(CMB)专家,Keating 带来的不仅是关于宇宙起源的思考,更是对 AI 本质的深层拷问。
采访中,LeCun 给出了许多总结性的观点:
“我认为这将是未来几年 AI 领域的重大挑战:如何超越自回归式大语言模型架构,发展能够理解真实世界、获得某种常识的架构。”
“强化学习效率如此之低,以至于它不可能解释我们在人类和动物身上观察到的那种高效学习。因为我们学习的大部分内容都不是被教导的,而是自己悟出来的。”
“我避免使用 AGI 这个词的原因,并不是因为我不相信 AI 系统最终会变得和人类一样聪明。”
“要达到让大众认可的人类级智能,就算是在最理想情况下——比如 JEPA 架构和其他设想都成功实现,我也看不到 5-6 年内能够实现。”
“在未来两年内可能发生的是:普通人越来越难找到最新的聊天机器人无法回答的问题。聊天机器人确实越来越厉害了,那请问家用机器人在哪里?完全自动驾驶的汽车在哪里?能在 20 小时练习中学会开车而不会撞车的自动驾驶汽车在哪里?”
“认为高智能必然导致统治欲望的想法是错误的。这种行为源于物种的生存需求,而不是智能水平。”
“寻找可证明安全的 AI 系统,是不可能的。”
“智能是社会最缺乏也最宝贵的资源。AI 增强人类智能的影响力可能堪比 15 世纪的印刷术。”
“人类水平的 AI 是个产品需求,一旦实现就会产生巨大影响。”
以下为对话全文:

AI 还是不如猫
主持人:LeCun,欢迎来到我的播客节目。你戴的这副智能眼镜是我最喜欢的科技产品,我现在已经用上第二代了。说起智能眼镜,我之前也买过 Apple Vision Pro,虽然对一个公立大学教授的工资来说这确实有点奢侈,不过最后我还是在退货期内退掉了。
杨立昆:我头上这副已经是我的第三副雷朋(Ray-Ban)智能眼镜了。第一代用过一段时间,第二代是去航海的时候因为船翻了进水坏掉的。因为那会儿还是早期产品,我就把它寄回给我们的同事,让他们分析一下到底是哪里出了问题,后来他们又给我寄来了一副新的。
主持人:说实话,我觉得这种智能眼镜真的代表着未来的方向。我用过 Apple Vision,也体验过 Meta Quest,玩游戏的时候感觉还不错,我家孩子们都很喜欢跟我抢着玩。但这些眼镜都有一个共同的问题:太重了。从人类的生物本能来说,我们并不喜欢视野受到限制,因为这样可能会让捕食者有机可乘。相比之下,我特别喜欢这种眼镜的增强现实体验,显示质量也很棒。虽然这听起来像在给 Meta 做广告,但我确实觉得苹果在这方面应该能做得更好,他们现在这个产品恐怕很难持续下去。
不过今天我们主要还是要聊物理学。我想请你跟我们的听众解释一下——镜头里,我背后墙上的这句“打开舱门”(Open the Pod Bay Doors)对你来说意味着什么?

杨立昆:这句话来自《2001 太空漫游》这部经典电影。这部电影对我的影响特别深远。我是在 9 岁时看的首映,当时被电影中探讨的各种主题深深吸引:宇宙、太空旅行、智能是如何产生的。虽然那时候年纪还小,但已经对智能计算机这样的概念着迷不已。
主持人:很多人可能不知道,我们现在经常说的“播客”(podcast)这个词就来源于这部电影。在你们的竞争对手苹果公司,有位工程师叫 Vinnie Chieco(旧金山独立撰稿人,iPod 的命名者),他和你一样也是受到了 HAL 9000 的启发。当他看到电影里那个闪亮的白色小型设备原型时,提议把自己的产品命名为 iPod,这就是“podcast”这个词的由来。说起来,这部电影里描述的人工智能现在可能会让一些研究者感到担忧,比如最近刚获得诺贝尔奖的 Geoffrey Hinton(“AI 教父”,图灵奖得主)。
我想从你今年 10 月在《华尔街日报》上的一段话开始我们的对话,这段话引起了我的兴趣,也很有挑战性。你说“AI 的智能水平勉强赶上猫”——你可能还没见过我家的猫,它会故意把水杯打翻在我的笔记本电脑上,还会玩弄死老鼠取乐——我实在想象不出 AI 会做这种事,除非在元宇宙的每个房间都装上激光笔。所以,你说这句话是想表达什么?这样说是想让我们感到安心吗?
杨立昆:我的意思是,即使是现在最先进的大语言模型,虽然在语言处理方面表现惊人,但它们对物理世界基本上没有任何理解,因为它们完全是通过文本训练的。它们获得的世界图景完全来自人类的表述,这种表述首先是符号化的,而且是近似的、简化的、离散的。真实世界要比这复杂得多。我们的 AI 系统完全无法处理真实世界。这就是为什么我们有能通过律师资格考试的大语言模型,却还没造出 10 岁孩童水平的机器人——比方说,有些任务对一个10岁的孩子来说轻而易举,甚至不需要花什么脑力就能一次性学会。
而猫就可以轻松完成这些任务。猫如果想跳到某个感兴趣的物体上时,它会先坐下来,转动脑袋规划路线,然后一跃一跃地精确到达目标。它们是怎么做到的?很显然,这些举动说明猫能够规划,能够推理,理解物理世界,对自身的动态特性和很多事物的直觉物理学都有极其出色的认知。这些都是我们现在的计算机还无法复制的能力。

理解世界的本质,探索智能的核心
主持人:对这些技术的乐观和悲观态度都让我觉得很有意思。我想到了所谓的“修昔底德陷阱”,就是当一个新兴力量崛起时,尽管它还很弱小,但已经主导力量却会把全部注意力都集中在它身上。这有点类似于沉没成本谬误。
我想听听你的看法:在物理科学领域,我们是不是正在把自己推向一个死胡同?这种基于 GPU 和大语言模型的方法似乎正在吸走这个领域的所有资源和注意力。从消费者的角度来看,这种趋势推动 NVIDIA 市值达到 3 万亿美元。我们现在是不是已经完全投入到 GPU 加大语言模型这条路上去了?这会不会扼杀物理学等领域的真正创新?
杨立昆:这个问题的答案既是肯定的也是否定的。确实,如果我们一直沉迷于大语言模型,让它吸走其他所有的资源和注意力,目前的情况看起来确实有点这种趋势。大语言模型就像是一把锤子,现在所有东西看起来都像钉子——这其实是一个错误。这也是我一直在强调的观点:大语言模型并不是 AI 的全部。考虑到它们在概念上的简单性,它们的能力确实令人惊讶。但有很多事情它们做不到,其中之一就是表达和理解物理世界,更不用说在物理世界中规划行动了。
我认为这将是未来几年 AI 领域的重大挑战:如何超越自回归式大语言模型架构,发展能够理解真实世界、获得某种常识的架构。
对于需要深思熟虑的复杂任务,我们的智能运作方式是这样的:我们会建立一个关于世界运作方式的心智模型,让它想象我们的行动会产生什么结果,然后优化这些行动序列来实现特定目标——这就是当猫站着观察并思考跳跃轨迹时在做的事情,这就是规划。它们对自己有心智模型,对要跳过的物体也有心智模型。我们经常在不知不觉中做这样的事情。这对物理学家来说应该很有意思,如果你感兴趣,我们接下来可以详细讨论这个话题。
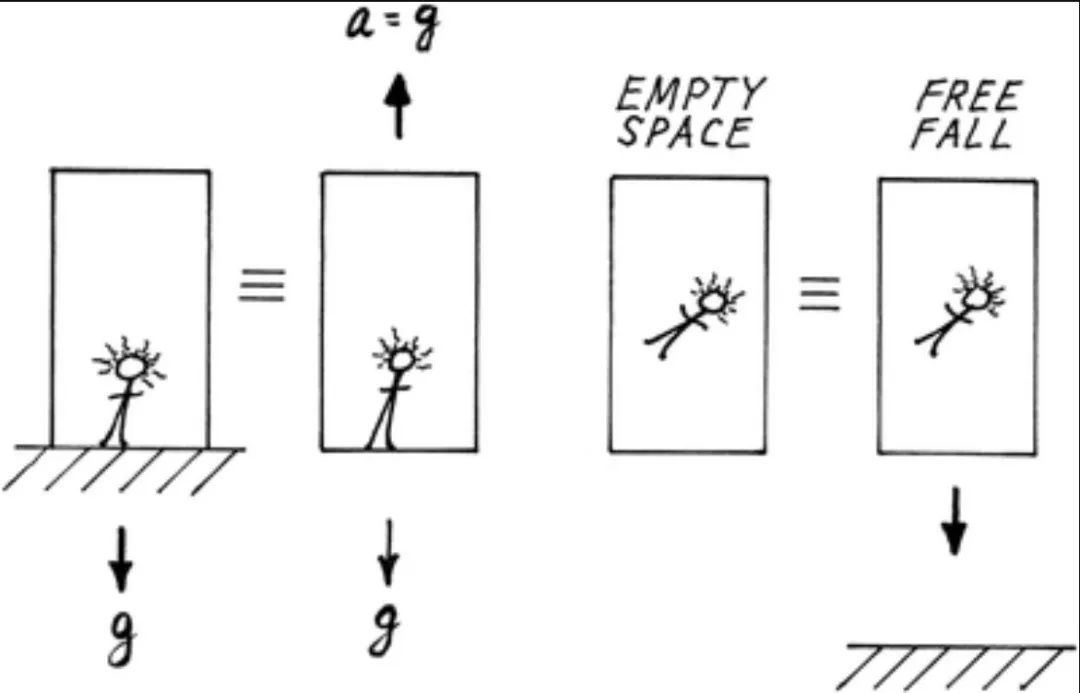
主持人:可以。1907 年,爱因斯坦做了一个思想实验,他设想了一个自由落体的电梯里的观察者——假设电梯的钢缆突然断裂,电梯开始下坠,那么这个人就不会感受到重力场的存在。他把这称为“一生中最快乐的想法”。
关于这一点,我想请教你两个问题:第一,计算机有可能产生快乐的想法吗?第二,如果没有身体或者说实体,没有那种我们坐过山车或电梯突然移动时都能感受到的本能反应,一个计算机系统怎么可能像爱因斯坦那样构建新的物理定律呢?
杨立昆:简单来说,现在的 AI 系统还无法产生这种直觉。虽然目前应用于科学发现的 AI 系统都是专门化的模型,比如用来预测蛋白质结构、预测两个分子之间的相互作用或者材料性质的模型。你不能用大语言模型来做这类工作,它们只会重复它们在训练中学到的内容,不会产生新的东西。
当然,这些专门的模型在某些方面很强大,它们能预测从未尝试过的化学反应,预测从未制造过的材料的性质。所以它们确实能在一定程度上超越已知领域,比大语言模型更能走出已知的范围,因为大语言模型基本上只是索引现有知识的方式。但它们还不能产生爱因斯坦那样的洞见。目前还不行,但我们希望有朝一日能做到。这也是我最关心的科学问题,就是如何实现这一点。我们人类,还有动物,是通过什么样的过程来构建对真实世界的模型的?
一个关键问题是,如何找到合适的表征方式和相关变量,以及如何为我们感兴趣的系统找到合适的抽象层次。举个例子,你我都知道,我们可以收集关于木星的无限多的数据,我们确实已经掌握了大量关于木星的数据,包括它的天气、密度、成分、温度等等所有信息。但谁能想到,要预测木星未来几个世纪的轨道,你只需要六个数字就够了——三个位置坐标和三个速度值,就这么简单。你甚至不需要知道密度、成分、自转等任何其他信息。就只需要六个数字。所以,要能做出预测,最困难的步骤就是找到对现实的合适表征,并且排除所有无关的信息。过去几年我一直在研究一种我认为能够做到这一点的架构,我们称之为 JEPA。如果你感兴趣的话,我可以详细解释一下。
主持人:洗耳恭听。
杨立昆:大语言模型有一个特点,或者说一个技巧,我很早就一直在提倡,叫做自监督学习。什么是自监督学习呢?基本上就是你拿一个输入,可以是一个序列或者其他任何东西,比如一张图像。你以某种方式破坏它,然后训练系统从被破坏的输入中恢复完整的输入。在语言和大语言模型的背景下,在当前这批大语言模型出现之前,有几种自然语言理解系统,但其中唯一成功的方法是:你拿一段文本,通过删除一些单词,用黑色标记替换它们,或者替换一些单词来破坏它。然后你训练一个巨大的神经网络来预测缺失或错误的单词。在这个过程中,系统学会了对文本的一个很好的内部表征,这个表征可以用于各种潜在的应用,比如作为翻译系统的输入,或者用于情感分析、摘要等等。
现在的大语言模型是这种方法的一个特例,它们的架构设计成这样:为了预测一个词,系统只能看到它左边的词。也就是说,它只能看到前面的词来预测某个特定的词。这样你就不需要进行破坏处理了,因为架构本身就通过限制系统只能看到左边的内容来实现了这种破坏。你输入内容,然后训练系统在输出端重现输入。这就是自监督的,因为没有明确的任务要求系统完成,也没有输入和输出的区分。所有东西既是输出也是输入。这就是自监督学习。
这种方法在语言领域效果惊人,对 DNA 序列和很多其他类型的数据也很有效。但它只对离散序列有效,比如语言。因为语言只有有限个词在字典里。你永远无法准确预测一个词序列后面会跟什么词,但你可以预测所有可能词的概率分布,就是一个由 0 到 1 之间的数字组成的大向量,总和为 1。
但对于自然数据呢?比如从传感器,比如相机获取的数据,你可以尝试同样的方法:拿一张图像,通过遮罩部分内容来破坏它,然后训练神经网络重建完整的图像。这叫做遮罩自编码器(MAE)。但这种方法效果并不是很好。实际上,有各种方法可以训练系统从部分视图重建,这些都叫做自编码器,但有各种不同的训练方法。遮罩技术只是其中之一,但这些方法都不是特别有效。顺便说一下,这些技术中很多都受到统计物理学的启发。比如有一种特定的方法叫做变分自编码器,这里的“变分”就来自变分自由能,用的是和统计物理学一样的数学原理。
主持人:它是在早期就失败了吗?是因为缺少某些边界条件或初始条件吗?就像三体问题那样?我去年对本科生问了这样一个问题:如果我们有水星过去 10000 年的轨道数据,给定这些数据,你能预测出牛顿力学中缺少了什么吗?换句话说,你能推导出需要用一个新的变分方法,也就是变分爱因斯坦拉格朗日量来增补它吗?然而,即便能预测到水星轨道存在一些异常进动,你也不可能推导出方程。我们基本上不得不通过输入爱因斯坦方程的类似形式来强行引导它。
所以,这让我想到另一个问题:如果 1899 年就有大语言模型,我们能预测出爱因斯坦的广义相对论吗?至少用我们现在使用的这种机器学习模型,我们做不到。这是不是就是它失败的原因?是不是因为它缺少了爱因斯坦天才般的洞察力?还是有其他原因?
杨立昆:不,是另外的原因。说起来很普通,但问题在于要预测一个高维的连续信号,比如图像或视频,很难表示所有可能图像的概率分布。还记得我们刚才说的预测单词的情况吗?
主持人:对,如果是真实语言的话,它不会输出无意义的内容,对吧?
杨立昆:没错。比如如果有一个动词,后面很可能会跟一个补语,诸如此类的规律。但对视频来说,你做不到这一点。如果你训练一个系统来预测视频中会发生什么,你给它看一段视频,然后停下来,让它预测接下来会发生什么。然后当然你会给它看实际发生了什么,训练它去预测这个。
但这种方法效果并不好。我在过去 15 年里一直在研究这个问题,确实效果不理想。原因是,如果你训练一个系统做单一预测,它能做的最好的事情就是预测所有可能发生的未来的平均值。这基本上就会得到一个模糊的图像。因为即使是我们现在的视频对话,我可能说这个词也可能说那个词,我可能把头转向这边也可能转向那边,我可能用这种方式移动手也可能用那种方式——如果系统必须做出一个预测,而我们训练它最小化预测误差,它就只会预测所有可能发生的事情的平均值。在这种情况下,它会生成我的手、头和嘴巴都特别模糊的图像,这显然不是一个好的预测。所以这种方法行不通。基本上通过重建或预测来进行自监督学习对自然信号是不起作用的。
接下来再让我们聊聊 JEPA。JEPA 是 Joint Embedding Predictive Architecture(联合嵌入预测架构)的缩写。什么是嵌入?嵌入是对信号的一种表征。你拿一张图像,你并不关心所有像素的具体值。你关心的是某种表征,这种表征是一系列数字,一个向量,它表示了图像的内容,但不表示所有细节。这就是嵌入。而联合嵌入是指,如果你拿一张图像和它的破损版本,或者说稍微变换过的版本,比如不同视角,图像的内容并没有改变,那么嵌入应该是相同的。所以联合嵌入架构就是一个大型神经网络,你训练它使得当你给它看同一个图像的两个版本时,它会产生相同的嵌入,你强制它产生相同的输出。
然后说到“P”,也就是预测(Predictive)这部分,比如说图像的一个版本是视频中的一帧,而破损版本是前一帧。这样你需要做的就是从前一帧预测下一帧,或者预测接下来的几帧。这就是 JEPA。所以联合嵌入预测架构有两个嵌入,一个处理视频的未来,一个处理过去,然后你有一个预测器试图从视频过去的表征预测未来的表征。当你用这种架构来训练系统学习图像的表征时,效果非常好。
过去几年里,我和我的同事们以及很多其他人已经开发出了许多不同的技术来实现这一点。效果确实很好。我们可以学习到图像的良好表征。我们也开始获得视频的良好表征,但这是很最近的进展。但你可以想象,现在我们回到之前讨论木星的例子,你有关于木星或水星的数据,然后你要求系统找到所有数据的良好表征,去除所有你无法预测的东西,这样你就能在表征空间中做出预测。也就是说,去除所有你无法预测的东素,比如木星上的天气,所有那些你真的无法预测的细节,只保留那些能让你在一定时间范围内做出预测的表征。
在我看来,这是在理解世界的本质,也正是你在研究物理时所做的事情。你试图找到一个现象的模型,去除所有无关的东素,然后找到一组相关变量来做出预测。这就是科学的本质。
主持人:这里面是否涉及主观的类比?比如说你提到了模型的温度时,是否仍然需要指定这样的参数?
杨立昆:在这个上下文中并不特别需要,因为当你有这种架构时,至少是我描述的这种简单架构,你消除了预测中的随机性——用一个希腊术语来说就是“stochasticity”。基本上,当系统被训练做这件事时,它会同时训练自己找到输入的良好表征,这个表征要尽可能保留输入的信息,同时还要保持可预测性。所以如果输入中有一些现象是不可预测的,比如混沌行为,随机事件,或者由热涨落引起的粒子个体运动等等,这些你根本无法预测的信息,系统就不会保留这些信息。它会去除这些,只保留对预测有用的相关输入部分。
比如说,让我们考虑一个充满气体的容器,我们可以测量很多东西,包括所有粒子的位置,这是海量的信息,但你无法预测,因为你需要知道每个粒子是如何与壁面和热库相互作用的。所以你真的无法做出任何预测。系统可能会告诉你:“我无法预测每个粒子的轨迹,但我可以测量压力、体积、可能还有粒子数和温度。当我压缩时,热量上升。”其中涉及了 PV=nRT 之类的规律,而在我看来这真的就是机器学习与科学,特别是物理学联系的本质。
这里还有另一个我认为很迷人的方面,因为这是个相对新的概念,我们还没有充分探索,那就是表征的抽象层次的概念。科学家们在物理学和其他科学领域已经在这样做了。理论上,我们可以用量子场论来解释我们之间现在发生的一切,对吧?
主持人:是的,我想是这样。
杨立昆:人类意识的主观性可能会起作用。但从根本上说,这只是粒子的相互作用,对吧?所以理论上,这一切都可以归结为量子场论。但显然,这完全不实用,因为你需要处理的信息量简直是天文数字。我们使用不同的抽象层次来表示现象,再次强调,这是为了去除细节。
我们有量子场论,在它之上是基本粒子理论,原子理论,分子理论,材料科学,然后你可以往上走,可以走得很高,然后是生物学,物体之间的相互作用,再往上可能是心理学。所以找到好的抽象表征,找到表征的层次,让你能够理解发生了什么,同时去除所有无关的细节,这正是智能的核心,我是这么认为的。

再议强化学习
主持人:我在五月份和 Peter Thiel(Paypal 创始人)讨论过一道问题,即“我们是否能从大语言模型中推断出什么”。它们确实有一些涌现性的特征,但目前它们缺少的东西,不清楚仅仅通过训练数据就能让它们达到“人工爱因斯坦”的水平。基本上,大语言模型有 20 万亿个 token,但一个四岁的孩子获得的数据量要大一个数量级,也许它们最终能获得那 10 倍的数据量。
但我总是说,阻止我们提出广义相对论类似理论或万物理论的,难道是因为 AI 现在还不知道《角斗士 2》的剧情吗?我不这么认为。换句话说,可以有无限多的训练数据以 token 的形式提供,但这里面有一些很不一样的东西。爱因斯坦不需要看《速度与激情 1》就能提出广义相对论,提出洛伦兹不变性原理。
说到庞加莱,在你看来,发现新物理学最有可能的途径是什么?是 JEPA 这种类型的视觉数据和基于观察现象的建模、在两者之间建立预测性桥梁的方法,还是像符号回归这样完全不同的方法?后者在我看来确实需要只有人类才能提供的某种监督。关键是,它是否需要只有人类才能提供的某种监督?
杨立昆:就目前来说,我觉得有一些技术专家已经研究了一段时间,在短期内可能会有很大的实用价值。比如符号回归这样的技术,这类工作可以追溯到几十年前,但那时候因为计算机能力不够强大等原因,效果不是很好。现在已经有了很大的进展。但我不认为这种方法能够产生我们谈论的那种洞察力,就是爱因斯坦那样的洞察力,或者像费曼那样的物理学家的洞察力,当然更不用说仅仅依靠这种方法就能产生万物理论了。
我认为缺少的东西更加根本。就是构建世界心智模型的能力,一个系统能在心智中操作这个模型,并使用极端情况。这就是我们之前谈到的爱因斯坦擅长的那种思想实验——在心智中建立某种模型,提出假设,然后把这个模型推向极端情况看看会发生什么。或者像人们经常用来解释相对运动时间收缩的思想实验:如果你观察一个在火车上的人,他让光在两面镜子之间上下反射,对那个人来说,光就是在车厢高度的垂直距离内上下运动。但对外部观察者来说,光是在沿对角线运动,所以实际上走了更长的距离,但仍然是以光速运动。所以时间一定是在收缩。
现在看来这实验很简单,但我们必须做出一个巨大的假设,就是光速对每个人来说都是一样的。这就涉及到你谈到的训练数据的问题。你需要看过《角斗士》才能提出相对论吗?当然不需要。有趣的是,科学史学家似乎说爱因斯坦并不了解凯斯西储大学的实验——他们试图证明以太的存在,却失败了。他们认为是自己的实验有缺陷。据历史学家说,爱因斯坦似乎并不知道这个实验。至少历史学家是这么说的。所以即使在没有实验证据支持他的假设的情况下,他也能提出这个概念。这确实很了不起。
主持人:虽然我们才认识 40 分钟,但我觉得你其实是个深藏不露的物理学家。
杨立昆:我确实是。
主持人:你最近说过一句让我特别感兴趣的话,因为这正好是我的研究领域。你把自监督学习比作 AI 领域的暗物质。就像物理学中的暗物质一样,它是必不可少的。我们知道它存在,或者说我们认为它存在——比方说,微子是暗物质的一种形式,但它们不足以解释观测到的缺失物质的数量。但你的比喻又是什么意思?你为什么说自监督学习类似于暗物质?
杨立昆:这个说法其实是八年前的了。我在一次主题演讲中提出这个观点时,台下坐着我的前同事 Kyle Cranmer,他是纽约大学的高能物理学家,现在在威斯康星大学。他说我不应该用暗物质作为类比,应该用暗能量,因为那才是宇宙中质量的主要部分。
我当时想要解释的类比是这样的:我们学习的大部分内容,并不是通过被告知答案或者通过试错来学习的。我们只是通过自监督学习来学习我们感知输入的结构。好吧,或者说类似的东西。我们实际上并不知道人类和动物使用什么方法,但它肯定更像是自监督学习,而不是监督学习或强化学习。
监督学习是这样一种情况:你有明确的输入和明确的输出,你训练系统将输入映射到输出。比如给系统看一张大象的图片,告诉它这是大象。如果它说这是猫,就调整参数让输出更接近“大象”,对吧?这就是监督学习。而强化学习是你给它看一张大象的图片,等它给出答案,然后只告诉它答案是对是错。你不告诉它正确答案是什么,只告诉它是对还是错。也许会给一个分数。这样系统就必须在所有可能的答案中搜索正确的那个。如果答案的可能性是无限的,这种方法就极其低效。
强化学习效率如此之低,以至于它不可能解释我们在人类和动物身上观察到的那种高效学习。因为我们学习的大部分内容都不是被教导的,而是自己悟出来的。动物也是如此,有很多动物物种变得非常聪明,却从未见过它们的父母。章鱼就是一个很好的例子,在鸟类和其他物种中也有很多例子。所以它们学到了很多关于世界的知识,却从未被任何人教导过。
自监督学习,才是真正的学习主要发生的地方。大语言模型的成功真正展示了自监督学习的力量。我当时用了一个比喻,我展示了一个巧克力蛋糕的图片,然后说蛋糕的主体部分,也就是蛋糕胚,就是自监督学习。糖霜是监督学习,蛋糕上的樱桃是强化学习。如果你想量化不同学习模式的相对重要性,这就是正确的类比。
当我在 2016 年说这些的时候,整个世界都完全专注于强化学习。强化学习被认为是通向人类水平 AI 的道路。我从来不相信这一点。所以当时这种观点很有争议。现在不再有争议了。然后我说,在蛋糕胚的主体部分有巧克力,那就是暗物质,是我们必须弄清楚如何做到的东西。这就像我们和物理学家处在同样尴尬的处境,我们知道如何做强化学习和监督学习,但我们并不真正知道如何做这个占主要部分的自监督学习。
主持人:继续谈谈暗物质的话题。上周我和你的一位同行 Stephen Wolfram(细胞自动机的提出者,计算机科学家)谈话,他对暗物质有一个非传统的想法,他认为宇宙是一个超图,按照他的说法,这个超图通过纯计算规则演化,而时间是由超图的更新率产生的。他提出,由于时间和温度通过热力学定律中的熵相关联,他实际上在暗示暗物质就是他所说的“时空热”。
我不是要你具体评论这个观点。说实话我自己也不完全理解。我们辩论此事是因为我提出了一个问题——我们暗物质的存在,却不知道它到底是什么。它可能是像轴子这样的奇异新粒子,也可能是我们不理解的某种新力场。但有些暗物质我们确实完全知道,比如 WIMPs(弱相互作用大质量粒子)。那么时空热能解释现在宇宙中温度约 1.9 开尔文的中微子吗?我们就这样争论了一番。但总的来说,关于宇宙是纯粹计算的这个超图想法,作为一个研究者,你对这个想法有什么看法?
杨立昆:具体关于超图的想法我不太了解,但我可以告诉你,物理学和计算之间的联系一直让我着迷。1988 年我在贝尔实验室开始职业生涯时,我所有的同事都是物理学家。那个实验室是物理实验室。我是唯一一个非物理学家——我不想说自己是计算机科学家,因为我的本科学位实际上是电气工程,而且我学过很多物理。但我所有的同事都是物理学家。
我有一位才华横溢的同事叫 John Denker(量子物理学家),他的办公室就在我隔壁。我们两个都对物理学中的一些基本问题以及它们与计算的联系非常感兴趣。1991 年左右,我们参加了圣塔菲研究所的几个研讨会,其中一个是由 Wojciech Zurek(量子理论权威)组织的。当时参加的人包括 Seth Lloyd(提出世界上第一个技术上可行的量子计算机设计),他那时候刚刚完成博士学位。还有 Murray Gell-Mann(1969 年诺贝尔物理学奖得主)和 John Wheeler(物理学巨擘,黑洞概念领军者)这样的人物。John Wheeler 当时做了一个演讲,题目是“比特造物”(It from Bit)。这也是他的一系列讲座的标题。
他说:“从根本上说,一切都是信息。我们必须找出如何用信息处理的方式来表达所有的物理学。”我觉得这个概念非常吸引人。我对这个想法思考了很长时间,虽然还不够具体到可以写成论文,但有一些有趣的想法。这方面的一个联系是可逆计算的概念,这个概念现在因为量子计算变得很重要,但在 90 年代早期并不那么流行。

AMI
主持人:说到物理学家,我们这次采访也从你的朋友 Max Tegmark(点击回顾这篇文章)那里收集了两个问题给你。第一个是:“你预计什么时候会出现 AGI?这里定义 AGI 为能完成几乎所有空间工作的 AI。”
杨立昆:我避免使用 AGI 这个词的原因,并不是因为我不相信 AI 系统最终会变得和人类一样聪明。我完全相信在未来某个时候,我们会有机器在人类智能的所有领域都能达到人类的水平。这毫无疑问会发生。这只是时间问题。但把这称为 AGI 完全没有意义,因为人类的智能是极其专门化的。这就是我不喜欢这个术语的原因。
我一直使用的术语是“人类水平的 AI”或“AMI”(高级机器智能,Advanced Machine Intelligence)。这是我们在 Meta 内部使用的术语——
主持人:朋友。(法语的“朋友”这个单词叫 Ami)
杨立昆:对,我们内部有很多法国人。在法语中正好也是这个意思。但概念是一样的。关于实现通用人工智能的时间表,这是个连扎克伯格这样打算投入数百亿建设 AI 训练基础设施的人都在关心的问题。
我的看法是这样的:如果在几年内,你能戴上智能眼镜,获得一位超越你智慧的 AI 助手,这不应该令人感到威胁,因为就像有个聪明的同事随时可以请教。
但要达到让大众认可的人类级智能,就算是在最理想情况下——比如 JEPA 架构和其他设想都成功实现,我也看不到 5-6 年内能够实现。而且历史告诉我们,人们总是低估了 AI 发展的难度,我现在可能也在犯同样的错误。
这个 5-6 年的预期是建立在不会遇到意外障碍的基础上。它需要我们的所有尝试都成功,需要技术能够扩展,需要计算能力提升,需要诸多条件完美契合。所以这已经是最理想情况了,别期待明年就能实现——哪怕你可能从其他人那里听说过。
主持人:比如 Sam Altman。
杨立昆:对,Sam Altman,Elon Musk,还有其他一些人。比如 Dario Amodei。他们经常说这会在未来两年内发生之类的。
然而,在未来两年内可能发生的是:普通人越来越难找到最新的聊天机器人无法回答的问题。聊天机器人确实越来越厉害了,那请问家用机器人在哪里?完全自动驾驶的汽车在哪里?能在 20 小时练习中学会开车而不会撞车的自动驾驶汽车在哪里?
主持人:作为一个对 AI 着迷并从中受益的普通人,我很好奇你的看法。比如现在我可以让 Meta 给孩子们读故事——虽然我没这么做,但道德上这和读别人写的书没什么区别。
但我觉得我们现在的讨论有点像德雷克方程。这个方程用来估算外星文明数量,给出一系列确定的参数,却忽略了不确定性。作为科学家,我们都知道系统误差容易处理,而统计误差才是难点——这才是物理学的精髓,需要直觉和技巧。但在这类问题上,你要么得出宇宙中有数十亿文明,要么一个都没有,完全取决于你选择的误差范围。
AGI 可能也是如此模糊。如果不用图灵测试,而用德雷克方程会怎样?图灵测试在一百年前很实用,但德雷克方程是关于“谁在和我们说话”,而图灵测试是关于“谁在听我们说话”。你觉得什么样的测试更合适?
杨立昆:坏消息是,我认为不存在任何单一的测试可以奏效。因为在任何特定领域,都可能出现超越人类的专门解决方案。计算机科学的历史已经证明了这点——从基础运算到多语言翻译,从一个 30 美元的象棋设备到 GPS 导航的路径算法,这些都是相对简单的技术,却能在特定任务上超越人类。
人们对大语言模型的语言操控能力印象深刻,但事实证明这比我们想象的简单得多。从进化角度看,语言能力仅在最近几十万年才出现,人类和黑猩猩基因组的差异可能只有几兆字节。大脑中的语言处理也只需要布洛卡区和韦尼克区这两个小区域。
这些系统表面上看起来具有一般智能,实则相当肤浅。当我们尝试构建能完成简单物理任务的系统时就能发现,这些任务极其复杂。尽管机器学习推动了机器人技术的进步,但我们离目标还很远。

可证明安全的 AI 系统是不可能的
主持人:再让我们回到 Max Tegmark 的第二个问题,你可能已经猜到了,“Yann,你有什么计划来防止更智能的 AGI 失控?”
杨立昆:这个问题我与 Max 和 Hinton 都有分歧。虽然我们是好朋友,但观点不同。首先,认为高智能必然导致统治欲望的想法是错误的。看看人类社会就知道,最聪明的人并不一定想当领导者,看看刚结束的大选。
主持人:确实,但我们就不谈政治了。
杨立昆:要产生统治行为,需要实体内部硬编码的资源竞争驱动力。这种统治-服从关系是社会性物种的特征,比如狒狒、黑猩猩、狼群。而在人类社会中,还存在通过威望获得影响力的方式——就像我们学者。相比之下,独居的猩猩就没有统治欲望,因为它们不需要。
现在的关键是如何确保 AI 系统的目标与人类价值观一致,避免它们有意或无意地伤害我们。大语言模型某种程度上确实不安全,因为它们是通过自回归方式逐个生成 token,而不是通过优化目标来产生输出。
主持人:为什么说不安全?就像小孩一样,没有实际力量也没有网络控制权,即使行为可能看起来很随机。
杨立昆:小孩可能会在你电脑前随机敲键盘,破坏文件系统。但就像你说的,不会发动核战争。AI 系统也一样,除非我们在设计上犯重大错误。
孩子们有进化赋予的硬编码驱动力,有些是为了探索和学习世界,有些则很具体——比如一岁左右想要站立,这是学习走路的本能。还有些更基础的硬编码行为,比如触碰婴儿嘴唇会引发吸吮反应。但自然只给了目标,不会告诉你如何实现——就像进食,你需要在父母帮助下自己学会找食物。
主持人:我不认为有什么是完全不可能的,但 Max 似乎在试图证明一些可能无法证明的东西。让你证明系统安全,这不就像在证明一个否定命题吗?
杨立昆:就像 Stuart Russell(欢迎回顾 CSDN 和这位教授的独家采访)在寻找可证明安全的 AI 系统一样,这就像试图证明涡轮发动机是绝对安全的——这是不可能的。但我们仍然可以制造出非常可靠的涡轮发动机,让双发飞机安全地带你飞越半个地球。
AI 也会如此。不会有什么神奇的数学证明,但我们可以通过工程手段构建安全系统。我的方案是构建目标驱动 AI。这种系统不是简单地逐个生成输出,而是通过优化来实现目标。系统会建立环境的心智模型,预测行动序列的结果,然后检查是否满足目标和护栏条件。
这些护栏就像约束条件——比如禁止伤害他人或过度消耗资源。系统会在行动空间中搜索最优解,同时遵守这些限制。除非你从根本上破坏系统,否则它无法绕过这些护栏。这和我们对人类行为的管理方式类似——通过法律设置边界。
主持人:对 AI 来说就像烧毁 GPU 电路一样致命。
杨立昆:没错,人类可以选择违法,但目标驱动的 AI 从设计上就必须遵守这些护栏。
主持人:我把这称为“间隙中的 AGI”。关键是 AGI 不会突然出现,这是个渐进过程。就像我们看到的 Waymo——它们不会在人行道上行驶,即使那是最短路径。我们能在早期版本就看到这些护栏的效果。就像第一个操作系统不是用操作系统构建的,第一台计算机不是用计算机设计的一样。第一个真正的 AGI 也不会是由 AGI 制造的,所以不可能出现那种递归式的失控。

人类水平的 AI 是个产品需求
主持人:你对 AGI 还有什么其他想法?
杨立昆:我持乐观态度。智能是社会最缺乏也最宝贵的资源。AI 增强人类智能的影响力可能堪比 15 世纪的印刷术——它推动了知识传播、启蒙运动、科学发展和民主。虽然也曾带来短期的负面影响,比如欧洲 200 年的宗教战争,但最终推翻了封建制度,引发了美国和法国革命。如果我们能做好,AI 将同样具有变革性影响。
主持人:所以你认为 AI 实际上会比 Facebook 早期的“戳一下”功能对人类更有变革性?说到 Facebook,你如何看待自己的身份?是教授、科学家、还是全球顶尖公司的员工?如果一个超级智能 AI 问你是谁,你会如何回答?
杨立昆:我首先是个科学家,也是教育者——不仅因为我是大学教授,更因为我致力于向公众传播科学知识。我的职业生涯在工业界和学术界各占一半。我在贝尔实验室开始职业生涯,后来去了 AT&T 实验室和 NEC 研究所。四十多岁才成为教授,此前从未任教。
我在纽约大学专职教授十年后加入了 Facebook,创建了 FAIR。我管理 FAIR 四年,同时保持教授职位——大约三分之二时间在 Meta,三分之一在纽约大学。现在我是 Meta 首席 AI 科学家,专注于个人贡献而非管理工作。说实话,我不擅长管理,那四年对我来说是种折磨。我更感兴趣的是智力影响力。
我在 Meta 的使命是为实现人类级智能铺路。这既是我毕生的科学追求,也是产品愿景——在智能眼镜中植入人类级智能助手。这是少有的例子,宏大目标与商业价值完美契合。
主持人:有个小技巧,你知道飞机上可以免费用 WhatsApp AI 和 Meta AI 连网吗?不用付那 19 美元的 WiFi 费用。
杨立昆:是的,通过 Meta AI 确实可以访问互联网。不过别说太大声,免得航空公司发现。
主持人:扎克伯格对这些技术的兴趣是什么?不可能只是为了改进滤镜吧?作为非科班出身,他对未来的愿景一定不只关乎消费,对吧?他的使命是什么?
杨立昆:他的核心使命是连接人类——这就是 Meta 的全部意义。但连接不仅指人与人之间,还包括人与知识的连接,以及改善人们的日常生活。
就像电影《她》展现的那样,未来每个人都可能随身携带超智能助手,通过眼镜、耳机或带摄像头的设备。这就像现在的商界领袖、政治家或学者都有智囊团一样。我个人也倾向于雇佣比我更聪明的人,这是好事。人们应该为这样的未来感到充满力量。如果要实现这个愿景,就需要人类水平的 AI。这是个产品需求,一旦实现就会产生巨大影响。我们已经在印度农村测试了雷朋眼镜,农民们非常喜欢它。
主持人:他们用它做什么?
杨立昆:他们可以询问植物病症、虫害防治、收获时机、天气预报等问题。最重要的是,他们可以用自己的当地语言交流。
主持人:是用印地语吗?
杨立昆:印地语只是官方语言之一。印度有 700 多种方言,20-30 种官方语言。大多数人其实不会说印地语。这种技术能让他们用自己最熟悉的语言获取知识和帮助。

AI 会取代教授吗?
主持人:在结束前,我有两个问题。首先谈谈我们的职业身份。我认为自己首先是父亲和丈夫,然后是科学家和教育者。想到我的偶像伽利略——他既是教授也是科学家,但也要谋生。他制造望远镜,编写说明手册如《星际信使》和《对话》来获取收入。
我们这个被称为“第二古老的职业”的教授工作,从博洛尼亚到牛津再到萨拉曼卡,已有千年历史。你认为 AI 会如何改变它?为什么学生还要跟我学习宇宙学和广义相对论,而不是直接向“AI 版爱因斯坦”请教?作为教授,你如何看待这个既是威胁也是机遇的局面?
杨立昆:显然,知识传递领域将经历深刻变革。我们需要为研究、科学和学术找到新的运作模式。但导师与学生之间类似绝地武士与学徒的关系仍将存在,因为这不仅关乎知识传授。我们可能从学生那里学到的跟他们从我们这里学到的一样多,只是学习和交流的方式不同。互动的重要性在于传递行为规范、伦理价值、研究方向和科学实践。在未来,每个人都会成为虚拟团队的一员,包括商界领袖、教授以及所有人。我们与学生的互动将是与学生本人及其 AI 系统的互动。
主持人:这是一个很棒的观点。我不觉得受到威胁。即使研究宇宙大爆炸时,我也保持着对它的热忱。我们正处在 AI 发展的起步阶段,有人说现在是 AI 最差的时期,未来只会更好。
杨立昆:确实如此。
主持人:是的。我能做的事情越来越多。某些任务仍需监督,但最重要的是这个过程多么令人愉悦。通过眼镜与 AI 交谈、询问物理问题并互动学习,特别是随着新的 Llama 模型在几乎每个学科都达到了 120 的智商水平,这些都让我感到非常兴奋。
最后一个问题。亚瑟·克拉克曾说,知道可能性极限的唯一方法就是超越它们。他还提到,每位专家都有一个持相反意见的专家;当一位杰出的科学家认为某事可能时,他很可能正确;但当他断言某事不可能时,他往往错了。Yann,在什么事情上你改变过看法?
杨立昆:确实有很多。比如在神经网络早期,1987 年我在 Geoffery Hinton 那里做博士后时,我对无监督学习持否定态度,认为这个概念定义模糊。而 Geoff 却坚信这是最有意思的方向,并因此获得了广泛认可。虽然现在没有人用玻尔兹曼机器了,但他的观点影响深远。他坚信学习必须是无监督的,事实证明他是对的。我到了 2000 年代初才认同这一点,并在 2010 年代开始明确倡导。这证明我之前的判断确实是错的。
对了,说到望远镜,虽然我不制造它们,但我业余时间做天体摄影。虽然不是科研,但我拍摄了一些漂亮的照片。
主持人:我很想看看。我在 Twitter 和 Instagram 上关注你,希望能看到这些作品。世界上最早的天体摄影师之一就是伽利略,他不仅记录观测结果,还描绘出他对宇宙的感悟。杨立昆,感谢这次精彩的对话。期待在西蒙斯基金会或弗拉特伦研究所再次相遇。
参考:
https://www.youtube.com/watch?v=u7e0YUcZYbE
阅读最新前沿科技趋势报告,请访问欧米伽研究所的“未来知识库”
https://wx.zsxq.com/group/454854145828

未来知识库是“欧米伽未来研究所”建立的在线知识库平台,收藏的资料范围包括人工智能、脑科学、互联网、超级智能,数智大脑、能源、军事、经济、人类风险等等领域的前沿进展与未来趋势。目前拥有超过8000篇重要资料。每周更新不少于100篇世界范围最新研究资料。欢迎扫描二维码或访问https://wx.zsxq.com/group/454854145828 进入。

截止到12月25日 ”未来知识库”精选的100部前沿科技趋势报告
2024 美国众议院人工智能报告:指导原则、前瞻性建议和政策提案
未来今日研究所:2024 技术趋势报告 - 移动性,机器人与无人机篇
Deepmind:AI 加速科学创新发现的黄金时代报告
Continental 大陆集团:2024 未来出行趋势调研报告
埃森哲:未来生活趋势 2025
国际原子能机构 2024 聚变关键要素报告 - 聚变能发展的共同愿景
哈尔滨工业大学:2024 具身大模型关键技术与应用报告
爱思唯尔(Elsevier):洞察 2024:科研人员对人工智能的态度报告
李飞飞、谢赛宁新作「空间智能」 等探索多模态大模型性能
欧洲议会:2024 欧盟人工智能伦理指南:背景和实施
通往人工超智能的道路:超级对齐的全面综述
清华大学:理解世界还是预测未来?世界模型综合综述
Transformer 发明人最新论文:利用基础模型自动搜索人工生命
兰德公司:新兴技术监督框架发展的现状和未来趋势的技术监督报告
麦肯锡全球研究院:2024 年全球前沿动态(数据)图表呈现
兰德公司:新兴技术领域的全球态势综述
前瞻:2025 年人形机器人产业发展蓝皮书 - 人形机器人量产及商业化关键挑战
美国国家标准技术研究院(NIST):2024 年度美国制造业统计数据报告(英文版)
罗戈研究:2024 决策智能:值得关注的决策革命研究报告
美国航空航天专家委员会:2024 十字路口的 NASA 研究报告
中国电子技术标准化研究院 2024 扩展现实 XR 产业和标准化研究报告
GenAI 引领全球科技变革关注 AI 应用的持续探索
国家低空经济融创中心中国上市及新三板挂牌公司低空经济发展报告
2025 年计算机行业年度策略从 Infra 到 AgentAI 创新的无尽前沿
多模态可解释人工智能综述:过去、现在与未来
【斯坦福博士论文】探索自监督学习中对比学习的理论基础
《机器智能体的混合认知模型》最新 128 页
Open AI 管理 AI 智能体的实践
未来生命研究院 FLI2024 年 AI 安全指数报告 英文版
兰德公司 2024 人工智能项目失败的五大根本原因及其成功之道 - 避免 AI 的反模式 英文版
Linux 基金会 2024 去中心化与人工智能报告 英文版
脑机接口报告脑机接口机器人中的人机交换
联合国贸发会议 2024 年全球科技创新合作促发展研究报告 英文版
Linux 基金会 2024 年世界开源大会报告塑造人工智能安全和数字公共产品合作的未来 英文版
Gartner2025 年重要战略技术趋势报告 英文版
Fastdata 极数 2024 全球人工智能简史
中电科:低空航行系统白皮书,拥抱低空经济
迈向科学发现的生成式人工智能研究报告:进展、机遇与挑战
哈佛博士论文:构建深度学习的理论基础:实证研究方法
Science 论文:面对 “镜像生物” 的风险
镜面细菌技术报告:可行性和风险
Neurocomputing 不受限制地超越人类智能的人工智能可能性
166 页 - 麦肯锡:中国与世界 - 理解变化中的经济联系(完整版)
未来生命研究所:《2024 人工智能安全指数报告》
德勤:2025 技术趋势报告 空间计算、人工智能、IT 升级。
2024 世界智能产业大脑演化趋势报告(12 月上)公开版
联邦学习中的成员推断攻击与防御:综述
兰德公司 2024 人工智能和机器学习在太空领域感知中的应用 - 基于两项人工智能案例英文版
Wavestone2024 年法国工业 4.0 晴雨表市场趋势与经验反馈 英文版
Salesforce2024 年制造业趋势报告 - 来自全球 800 多位行业决策者对运营和数字化转型的洞察 英文版
MicrosoftAzure2024 推动应用创新的九大 AI 趋势报告
DeepMind:Gemini,一个高性能多模态模型家族分析报告
模仿、探索和自我提升:慢思维推理系统的复现报告
自我发现:大型语言模型自我组成推理结构
2025 年 101 项将 (或不会) 塑造未来的技术趋势白皮书
《自然杂志》2024 年 10 大科学人物推荐报告
量子位智库:2024 年度 AI 十大趋势报告
华为:鸿蒙 2030 愿景白皮书(更新版)
电子行业专题报告:2025 年万物 AI 面临的十大待解难题 - 241209
中国信通院《人工智能发展报告(2024 年)》
美国安全与新兴技术中心:《追踪美国人工智能并购案》报告
Nature 研究报告:AI 革命的数据正在枯竭,研究人员该怎么办?
NeurIPS 2024 论文:智能体不够聪明怎么办?让它像学徒一样持续学习
LangChain 人工智能代理(AI agent)现状报告
普华永道:2024 半导体行业状况报告发展趋势与驱动因素
觅途咨询:2024 全球人形机器人企业画像与能力评估报告
美国化学会 (ACS):2024 年纳米材料领域新兴趋势与研发进展报告
GWEC:2024 年全球风能报告英文版
Chainalysis:2024 年加密货币地理报告加密货币采用的区域趋势分析
2024 光刻机产业竞争格局国产替代空间及产业链相关公司分析报告
世界经济论坛:智能时代,各国对未来制造业和供应链的准备程度
兰德:《保护人工智能模型权重:防止盗窃和滥用前沿模型》-128 页报告
经合组织 成年人是否具备在不断变化的世界中生存所需的技能 199 页报告
医学应用中的可解释人工智能:综述
复旦最新《智能体模拟社会》综述
《全球导航卫星系统(GNSS)软件定义无线电:历史、当前发展和标准化工作》最新综述
《基础研究,致命影响:军事人工智能研究资助》报告
欧洲科学的未来 - 100 亿地平线研究计划
Nature:欧盟正在形成一项科学大型计划
Nature 欧洲科学的未来
欧盟科学 —— 下一个 1000 亿欧元
欧盟向世界呼吁 加入我们价值 1000 亿欧元的研究计划
DARPA 主动社会工程防御计划(ASED)《防止删除信息和捕捉有害行为者(PIRANHA)》技术报告
兰德《人工智能和机器学习用于太空域感知》72 页报告
构建通用机器人生成范式:基础设施、扩展性与策略学习(CMU 博士论文)
世界贸易组织 2024 智能贸易报告 AI 和贸易活动如何双向塑造 英文版
人工智能行业应用建设发展参考架构
波士顿咨询 2024 年欧洲天使投资状况报告 英文版
2024 美国制造业计划战略规划
【新书】大规模语言模型的隐私与安全
人工智能行业海外市场寻找 2025 爆款 AI 应用 - 241204
美国环保署 EPA2024 年版汽车趋势报告英文版
经济学人智库 EIU2025 年行业展望报告 6 大行业的挑战机遇与发展趋势 英文版
华为 2024 迈向智能世界系列工业网络全连接研究报告
华为迈向智能世界白皮书 2024 - 计算
华为迈向智能世界白皮书 2024 - 全光网络
华为迈向智能世界白皮书 2024 - 数据通信
华为迈向智能世界白皮书 2024 - 无线网络
安全牛 AI 时代深度伪造和合成媒体的安全威胁与对策 2024 版
2024 人形机器人在工业领域发展机遇行业壁垒及国产替代空间分析报告
《2024 年 AI 现状分析报告》2-1-3 页.zip
万物智能演化理论,智能科学基础理论的新探索 - newv2
世界经济论坛 智能时代的食物和水系统研究报告
生成式 AI 时代的深伪媒体生成与检测:综述与展望
科尔尼 2024 年全球人工智能评估 AIA 报告追求更高层次的成熟度规模化和影响力英文版
计算机行业专题报告 AI 操作系统时代已至 - 241201
Nature 人工智能距离人类水平智能有多近?
Nature 开放的人工智能系统实际上是封闭的
斯坦福《统计学与信息论》讲义,668 页 pdf
国家信息中心华为城市一张网 2.0 研究报告 2024 年
国际清算银行 2024 生成式 AI 的崛起对美国劳动力市场的影响分析报告 渗透度替代效应及对不平等状况英文版
大模型如何判决?从生成到判决:大型语言模型作为裁判的机遇与挑战
毕马威 2024 年全球半导体行业展望报告
MR 行业专题报告 AIMR 空间计算定义新一代超级个人终端 - 241119
DeepMind 36 页 AI4Science 报告:全球实验室被「AI 科学家」指数级接管
《人工智能和机器学习对网络安全的影响》最新 273 页
2024 量子计算与人工智能无声的革命报告
未来今日研究所:2024 技术趋势报告 - 广义计算篇
科睿唯安中国科学院 2024 研究前沿热度指数报告
文本到图像合成:十年回顾
《以人为中心的大型语言模型(LLM)研究综述》
经合组织 2024 年数字经济展望报告加强连通性创新与信任第二版
波士顿咨询 2024 全球经济体 AI 成熟度矩阵报告 英文版
理解世界还是预测未来?世界模型的综合综述
GoogleCloudCSA2024AI 与安全状况调研报告 英文版
英国制造商组织 MakeUK2024 英国工业战略愿景报告从概念到实施
花旗银行 CitiGPS2024 自然环境可持续发展新前沿研究报告
国际可再生能源署 IRENA2024 年全球气候行动报告
Cell: 物理学和化学 、人工智能知识领域的融合
智次方 2025 中国 5G 产业全景图谱报告
上下滑动查看更多


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









