







决策树之C4.5
本系列分享由三篇博客组成,建议从前往后阅读学习。
0.引言
前一节中讲到了决策树的算法ID3,而C4.5是在ID3的基础上发展而来的。
我们先回忆一下ID3算法有哪些缺陷:
1)ID3算法只能解决特征值是离散的问题,当特征值是连续值时将无能为力。
2)同样ID3算法只讨论了输出为离散值的问题,输出值为离散值时则无能为力。(只能做分类,不能做回归)
3)没有考虑存在缺失值的情况。
4)当使用信息增益来进行特征选择时,往往偏向于选择特征取值较多的特征。原因是当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,划分之后的熵更低。
5)对于过拟合问题无能为力。
在C4.5中,解决了上述ID3的1、3、4、5的问题。我们依旧从“决策树的生成原理”、“过拟合问题的解决”这两方面来讲述C4.5。
1.决策树的生成原理
1.1 连续型变量的处理
之前讲到了ID3算法输入的特征必须是离散的,在C4.5中解决了这个问题,C4.5允许输入的特征是连续的。
C4.5处理连续型变量的方法是将连续型变量转换为离散型变量。假设该特征有个值,将它从小到大排序之后,那么我们有
种方式将它分成两个部分,划分点取相邻两个点的均值
如下图:
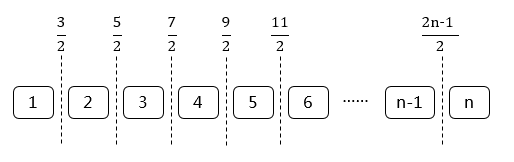
假设特征A是连续变量,A的值排序之后为1.01,1.22,1.36一共有三个值,那么我们有两种方式将A切成两个部分,分别是“A≥1.115,A<1.115”和“A≥1.29,A<1.29”。
这样我们就把连续变量转换为了离散变量。
在分枝进行特征选择时,比较每个特征得到的信息增益大小选出信息增益最大的特征就可以了。在计算连续变量的信息增益时注意要计算种情况下的信息增益,选出最大的作为该特征的信息增益,之后该连续变量用对应的间隔点进行划分。
1.2 分枝依据的修正
ID3的缺陷中提到了ID3算法更偏向于选择特征值较多的特征,因此C4.5算法针对这个缺陷进行了改进。分枝的依据不再采用信息增益,而是采用信息增益比,信息增益比是信息增益与特征熵的比值,信息增益比的表达式如下:
其中表示样本个数,
表示特征
的第
个类别对应的样本数。
我们可以把信息增益比看作信息增益乘上一个惩罚系数,特征
的特征值越多,惩罚系数的值越小,信息增益的调整比例越大。
1.3 缺失值的处理
对于存在缺失值的情况有两件事情需要考虑,一是存在缺失值时信息增益比怎么计算。二是选择了分类特征之后怎样将有缺失值的样本进行分类。
在谈缺失值时一般引入权值,初始状态每个样本的权值均为1。
对于第一个问题:怎么计算信息增益比。很简单,只考虑没有缺失值的样本,计算出信息增益比,再乘上特征没有缺失值的样本的比例(也相当于一种惩罚)就得到了该分类过程的信息增益比。比较各个特征的信息增益比,将最高的信息增益比对应的特征作为分类特征。表达式为:
其中为特征A没有缺失值的样本集合,
为特征
没有缺失值的样本数量。这样就解决了第一个问题。
对于第二个问题:怎么将特征存在缺失值的样本进行分类。假设只有一个缺失样本,但有多个分枝,这个样本该分到哪一类中去呢?我们可以将这个样本拆成多份分到多个分枝中,这就相当于每个分枝中都有这个样本,而这个样本在各个分枝中的权值都小于1,那么问题又来了,权值该怎么确定呢?是不是应该某一个分枝多分一点,另外的分枝少分一点呢?这个取决于原本各个分枝样本加总的权值,原来分枝中样本加总的权值越多,则分到该分枝的权值就越大。例如:1个权值为1样本要分到两个分枝中,原本两个分枝的权值之比为2:1。则分到两个分枝的权值分别为
,
。
上面对样本进行分类的方法我个人认为是有一定的缺陷的。假设在分类之后得到两个熵为0的集合,那么在对这个按照分枝权值的方法进行划分的话对熵的影响比较大。因此我认为权值采用贝叶斯概率进行划分比较合适。(这个没有查阅相关资料,也许之前已经有人想到了)
1.4 C4.5生成树的算法流程
C4.5生成树的过程与ID3几乎相同。但也有以下几点不同:
(1)采用信息增益比的划分标准。
(2)计算信息增益比时连续值的计算过程稍复杂,需要算多个分割点的信息增益比。
(3)每次划分进行划分时考虑到了缺失值。
2.过拟合问题的解决
在生成决策树之后常常会产生过拟合的现象。
我们通常通过剪枝的方式解决过拟合的问题。剪枝分为预剪枝和后剪枝。
预剪枝包括:
(1)控制信息增益比的阈值。
(2)控制树的最大层数。
(3)控制结点最少样本数量。
后剪枝也有几种方式,这里只介绍其中的一种。
所谓后剪枝就是在生成决策树之后再对其进行剪枝。剪枝会遇到几个问题,这里该不该剪?先剪哪里后剪哪里?
是否剪枝我们采用损失函数进行度量。对于任意一个子树,其损失函数为:
其中,为正则化参数,
为当前子树的结点个数,
为样本的误差(以该子树的根结点为总样本,只看该子树最终的分类结果),这里用熵来表示样本误差(后面会讲到在CART中,离散情况用基尼系数表示,连续情况用均方根误差来表示)。
注意,现在我们考虑的是一颗子树,对于这颗子树我们概不该剪呢?我们只要比较一下剪之前和和剪之后的误差就可以了,剪之前的误差即为上式。剪之后,该子树仅剩一个根结点,误差表示为:
当时,表示剪了之后误差更大,因此选择不剪。此时
。
当时,表示剪了之后误差更小,因此选择进行剪枝。此时
。
当时,表示误差相同,剪不剪都无所谓。此时
。
因此,我们现在可以判断一个子树是否需要修剪,但我们还需要确定先剪哪个再剪哪个。
当时,所有的子树都会选择不进行修剪。随着
的不断的扩大,陆续有一些子树选择进行修剪,最后,整棵树就只剩下根结点。
因此的大小决定了子树是否被修剪,并且可以看出修剪子树的临界值
的大小与该子树的重要程度有关。
因此,在修剪之前,计算出每个子树的修剪临界的值。
但是还有一个问题需要解决,什么时候停止修剪?
我们采用的方法存储每一次剪枝之后的结果,之后去比较哪一次剪枝之后的效果最好。这里可以通过比较每棵树的总体的信息增益比。(有的地方说可以通过交叉验证的方式进行比较,我不太清楚其中的原理,有知道的大佬可以留个言,万分感谢)
之后,后剪枝的算法流程如下:
1)初始化, 最优子树集合
。
2)从叶子节点开始自下而上计算各内部节点t的训练误差损失函数(回归树为均方根误差,分类树为基尼系数\信息增益比), 叶子节点数
,以及正则化阈值
, 更新
。
3) 得到所有节点的值的集合
。
4)从中选择最小的值
,自上而下的访问整个树,
时,进行剪枝,并决定叶节点t的值。如果是分类树,则是概率最高的类别,如果是回归树,则是所有样本输出的均值。这样得到
对应的最优子树
。
5)最优子树集合,
。
6) 如果不为空,则回到步骤4。否则就已经得到了所有的可选最优子树集合
。
7) 在选择最优子树
。
3.C4.5的缺陷
1)C4.5依旧不能解决回归的问题。
2)C4.5需要进行多个对数计算,效率比较低。
3)对于离散型变量中变量值较多的情况只能生成多叉树。
以上是我对C4.5的理解,如有不到位的地方,还请指正。
在接下来的CART算法中,对C4.5做出了改进。















 3719
3719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









