







1.C4.5算法与决策树算法
C4.5算法是决策树算法的一种。决策树是一种基于特征对实例进行分类或回归的过程。罗斯昆(J Ross Quinlan)在ID3算法的基础上进行了优化,提出了C4.5算法。 C4.5算法与ID3算法的最大变化在于,引入了信息增益比作为特征分裂的依据。如此,类似于将信息增益进行了“正则化”处理,减轻“过拟合”的风险(这里仅是打个比方。越是简单的规律,越有可能泛化。)。
ID3算法可参见:ID3算法原理详解_blinkyou001的博客-CSDN博客
2.C4.5算法原理
此部分先讲解一下信息熵(经验熵、条件熵)、信息增益、信息增益比,然后讲解一下算法的步骤。部分内容在ID3算法的文章中有详细讲解,此处只简述。
2.1 信息熵
信息熵是描述信息源各可能事件发生的不确定性。其公式为:
其中,表示第
个类别的概率。
由此衍生出两个概念:经验熵、条件熵。
1)经验熵
特征的经验熵为:
2)条件熵
设特征有
个属性
。
属性的信息熵为
, 其中,
表示该属性的第
个类别,
表示该属性中第
个类别的概率。
属性的权重为
,其中
表示
对应的样本数量,
表示特征
对应的样本数量。
则特征的条件熵为:
2.2 信息增益
特征的信息增益:
2.3 信息增益比
按特征的
个属性将数据集
划分为
,
表示数据集
的样本数量,
特征的分裂信息:
特征的信息增益比:
从信息增益的计算过程可以看出,当特征的属性较多时,条件熵的值倾向于越小,信息增益越大。从信息增益比的公式可以看出,当两特征的信息增益相同时, 分裂信息越小的(“混沌”程度越低)特征的信息增益比越大。
2.4 C4.5算法步骤
C4.5算法步骤与ID3算法步骤类似。
2.4.1 输入与输出
输入:训练数据集,特征集
,信息增益分裂阈值
。其中训练数据集
中包括分类值(可以类似理解为目标值、被解释变量等),分裂阈值
是为了判断是否进一步分裂的条件。
输出:决策树
2.4.2 算法过程
1、节点预判断
1)若该节点的数据集中所有实例都属于同一类
, 则以
作为此节点的分类,此节点分裂结束;
2)若该节点的数据集中所有实例无任何特征或无可用于分裂的属性,以
中实例类别数量最多的
作为此节点的实例分类,此节点分裂结束。
否则进入下一步。
2、选择分裂特征
在该分裂的样本集下,计算每一个特征的信息增益比,以信息增益比最大的特征为该节点的分裂特征,进入下一步。
若多个特征的信息增益比相等,随机选择一个特征作为分裂特征;若所有特征最大的信息增益比<,则该节点分裂停止,以该节点数据集中实例类别数量最多的
作为该节点的实例分类。
3、节点分类
按该特征的属性分裂产生子节点,以各属性中实例类别数量最多的作为各子节点的类别。
4、继续分裂
对上一步产生的各子节点,返回第1步循环(递归调用)。直至所有节点分裂结束。
3.C4.5算法演示
本部分算法演示选择与ID3算法原理详解_blinkyou001的博客-CSDN博客文中相同的例子进行演示。
以客户的申请信息来判断是否给予贷款。涉及的特征有年龄、性别、收入、房产、信用表现、审批结果,前5个特征分别记为。以此数据集为样本,记为
。
3.1 数据集
| 序号 | 年龄 | 性别 | 收入 | 房产 | 信用表现 | 审批结果 |
| 1 | 青年 | 男 | 高 | 有 | 优秀 | 通过 |
| 2 | 青年 | 男 | 中 | 无 | 一般 | 通过 |
| 3 | 青年 | 男 | 低 | 无 | 差 | 拒绝 |
| 4 | 青年 | 女 | 中 | 有 | 优秀 | 通过 |
| 5 | 青年 | 女 | 低 | 无 | 一般 | 通过 |
| 6 | 中年 | 男 | 高 | 有 | 一般 | 拒绝 |
| 7 | 中年 | 男 | 中 | 无 | 差 | 拒绝 |
| 8 | 中年 | 女 | 高 | 有 | 优秀 | 通过 |
| 9 | 中年 | 女 | 中 | 有 | 优秀 | 通过 |
| 10 | 中年 | 女 | 低 | 无 | 一般 | 拒绝 |
| 11 | 老年 | 男 | 高 | 有 | 优秀 | 通过 |
| 12 | 老年 | 男 | 低 | 有 | 差 | 通过 |
| 13 | 老年 | 男 | 低 | 无 | 差 | 拒绝 |
| 14 | 老年 | 女 | 中 | 无 | 一般 | 通过 |
| 15 | 老年 | 女 | 高 | 有 | 差 | 拒绝 |
3.2 算法步骤
1)第一层分裂
样本数据的分类,即“审批结果”有两个类别:通过、拒绝,并非同一类,需要分裂。
为选择分裂特征,需要计算各特征的信息增益。为计算信息增益,先计算经验熵和条件熵。
经验熵:
年龄的条件熵:
| 人数 | 通过 | 拒绝 | ||
| 年龄 | 青年 | 5 | 4 | 1 |
| 中年 | 5 | 2 | 3 | |
| 老年 | 5 | 3 | 2 |
青年、中年、老年的权重分别为:
青年的信息熵:
中年的信息熵:
老年的信息熵:
计算年龄特征的条件熵:
年龄特征的信息增益:
年龄的分裂信息:
年龄特征的信息增益比:
类似可以计算其它特征的信息增益:
| 人数 | 通过 | 拒绝 | ||
| 性别 | 男 | 8 | 4 | 4 |
| 女 | 7 | 5 | 2 |
| 人数 | 通过 | 拒绝 | ||
| 收入 | 高 | 5 | 3 | 2 |
| 中 | 5 | 4 | 1 | |
| 低 | 5 | 2 | 3 |
| 人数 | 通过 | 拒绝 | ||
| 房产 | 有 | 8 | 6 | 2 |
| 无 | 7 | 3 | 4 |
| 人数 | 通过 | 拒绝 | ||
| 信用表现 | 优秀 | 5 | 5 | 0 |
| 一般 | 5 | 3 | 2 | |
| 差 | 5 | 1 | 4 |
| 特征 | 经验熵 | 条件熵 | 信息熵 | 分裂信息 | 信息增益比 |
| 年龄 | 0.971 | 0.8879 | 0.0831 | 1.585 | 0.0524 |
| 性别 | 0.971 | 0.9361 | 0.0349 | 0.9968 | 0.035 |
| 收入 | 0.971 | 0.8879 | 0.0831 | 1.585 | 0.0524 |
| 房产 | 0.971 | 0.8925 | 0.0785 | 0.9968 | 0.0788 |
| 信用表现 | 0.971 | 0.5643 | 0.4067 | 1.585 | 0.2566 |
从上表可以看出,信用表现的信息增益比最高。若最大信息增益的特征有多个,可以随机选择一个。其属性有优秀、一般、差。特征选择完毕。
该节点的分类。“优秀”属性中,类别最多的为“通过”,该属性归类为“通过”;“一般”属性中,类别最多的为“通过”,该属性归类为“通过”;“差”属性中,类别最多的为“拒绝”,该属性归类为“拒绝”。
2)第二层分裂
分别对信用表现特征的三个属性作为预判断,再决定是否继续分裂。
a)优秀
该节点下的数据都属于“通过”一类。无需再分裂。
b)一般
样本数据的分类,即“审批结果”有两个类别:通过、拒绝,并非同一类,需要分裂。
| 序号 | 年龄 | 性别 | 收入 | 房产 | 审批结果 |
| 2 | 青年 | 男 | 中 | 无 | 通过 |
| 5 | 青年 | 女 | 低 | 无 | 通过 |
| 6 | 中年 | 男 | 高 | 有 | 拒绝 |
| 10 | 中年 | 女 | 低 | 无 | 拒绝 |
| 14 | 老年 | 女 | 中 | 无 | 通过 |
先计算其经验熵:
,其中
表示第二层分裂、第5个特征(信用表现)的第2个属性(一般)的熵。
类似计算得到:
| 特征 | 经验熵 | 条件熵 | 信息熵 | 分裂信息 | 信息增益比 |
| 年龄 | 0.971 | 0 | 0.971 | 1.5219 | 0.638 |
| 性别 | 0.971 | 0.951 | 0.02 | 0.971 | 0.0206 |
| 收入 | 0.971 | 0.4 | 0.571 | 1.5219 | 0.3752 |
| 房产 | 0.971 | 0.649 | 0.322 | 0.7219 | 0.446 |
年龄的信息增益比最大,选择年龄作为进一步分裂的特征。年龄的属性有:青年、中年、老年。
继续分裂:
青年分类均为“通过”,中年分类均为“拒绝”,老年分类均为“通过”。本节点分裂结束。
c)差
样本数据的分类,即“审批结果”有两个类别:通过、拒绝,并非同一类,需要分裂。
| 序号 | 年龄 | 性别 | 收入 | 房产 | 审批结果 |
| 3 | 青年 | 男 | 低 | 无 | 拒绝 |
| 7 | 中年 | 男 | 中 | 无 | 拒绝 |
| 12 | 老年 | 男 | 低 | 有 | 通过 |
| 13 | 老年 | 男 | 低 | 无 | 拒绝 |
| 15 | 老年 | 女 | 高 | 有 | 拒绝 |
先计算其经验熵:
,其中
表示第二层分裂、第5个特征(信用表现)的第1个属性(差)的熵。
条件熵与信息增益比:
| 特征 | 经验熵 | 条件熵 | 信息熵 | 分裂信息 | 信息增益比 |
| 年龄 | 0.7219 | 0.551 | 0.1709 | 1.371 | 0.1247 |
| 性别 | 0.7219 | 0.649 | 0.0729 | 0.7219 | 0.101 |
| 收入 | 0.7219 | 0.551 | 0.1709 | 1.371 | 0.1247 |
| 房产 | 0.7219 | 0.4 | 0.3219 | 0.971 | 0.3315 |
房产的信息增益最大,选择房产作为进一步分裂的特征。房产的属性有:有,无。
该节点的分类。“有”属性中,两类别数量相同,不妨将该属性归类为“拒绝”;“无”属性中,均为“拒绝”,该属性归类为“拒绝”。
3)第三层分裂
在第二层中,信用表现中的属性“差”尚需进一步分裂。 已经选择出房产作为下一步分裂的特征。
分别对房产特征的两个属性作为预判断,再决定是否继续分裂。
a)有
该属性2个实例分属两类,需要继续分裂。
| 序号 | 年龄 | 性别 | 收入 | 审批结果 |
| 11 | 老年 | 男 | 低 | 通过 |
| 14 | 老年 | 女 | 高 | 拒绝 |
该节点的经验熵为:
,其中,
表示第三层分裂、第4个特征(房产)的第1个属性(有)的熵。
其中,年龄特征只剩1个属性,已无法再分裂。剩余性别、收入再进行分裂。
如前文计算该节点的信息增益比:
| 特征 | 经验熵 | 条件熵 | 信息熵 | 分裂信息 | 信息增益比 |
| 性别 | 1 | 0 | 1 | 1 | 1 |
| 收入 | 1 | 0 | 1 | 1 | 1 |
性别和收入的信息增益比均为1,不妨选择性别作为进一步分裂特征。性别的属性有:男,女。
该节点的分类。“男”属性中,类别均为“通过”,该属性归类为“通过”;“女”属性中,类别均为“拒绝”,该属性归类为“拒绝”。
以上属性中,分类唯一,无需要进一步分裂。本节点分裂结束。
b)无
该属性分类均为“拒绝”,仅有1个分类。无需进一步分裂。
至此,所有节点均无需再进一步分裂(单一类别),分裂结束。
3.3 分裂图示
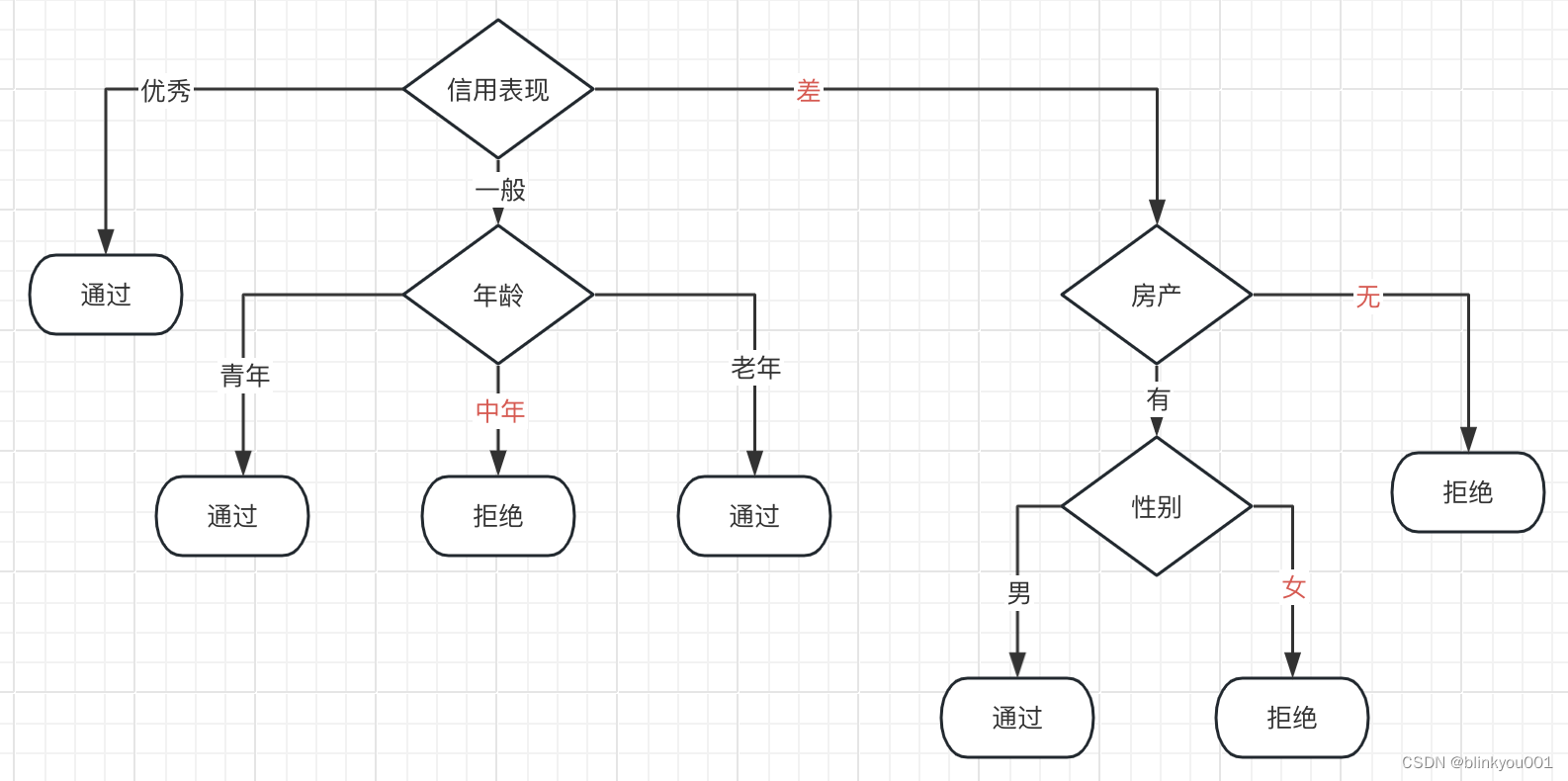
注:属性颜色,黑色表示进一步分裂前的分类--“通过”,红色表示进一步分裂前的分类--“拒绝”。
4.C4.5算法的总结
C4.5算法作为基础的决策树算法之一,是在ID3算法基础上改进而来:
1)是决策树算法的一种,通过信息增益比来决定分裂特征与分裂节点的选择;
在算法实现细节上,C4.5算法作了相应的处理,使得:
2)能够处理连续特征:将连续特征进行离散化;
3)能够处理缺失值;
4)C4.5算法使用了后剪枝,降低了过拟合的风险。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









