






背景
OLAP数据库是大数据场景下用于进行数据分析不可或缺的系统,早期主要有Oracle、Vertica、HANA等商业数据库占据市场份额,后来出现了GreenPlum、Impala、Presto、Kylin等开源的OLAP系统,字节跳动带火了ClickHouse,Snowflake的出现和上市使OLAP进入了云原生时代,之后从百度Palo发展而来的StarRocks和Doris相继进入Linux和Aapche基金会并进行商业化。
公司内部有部分业务已尝试使用Doris和StarRocks,如有道和邮箱等。在我们跟内部业务的日常交流中,有些业务开发也会咨询是否有提供Doris或StarRocks服务。在与外部商业化客户接触时,也会被问起NDH产品是否支持Doris或StarRocks。由于Doris和StarRocks是两个相似度很高的系统,如果有必要提供Doris或StarRocks服务的话,那么应该选择哪个系统。基于上述的现状,我们希望能够对业务的Doris和StarRocks需求做深入地了解,并分析这些需求是否能够通过Impala或ClickHouse满足。
调研对象
公司内部的互联网类业务,DBA同事,外部的金融类客户,销售和售前同事。此外,我们还跟了Doris/SelectDB和StarRocks团队进行了线下面对面交流。
信息收集与分析
- 为什么会关注Doris或StarRocks?
两家公司持续的宣传是引起关注的重要原因,包括高密度的新特性发布、benchmark数据和大量的用户实践案例。由于具备较全面的能力,而且均兼容MySQL协议,考虑到MySQL在OLTP领域统治性的地位,其对业务开发的亲近感较高。
“StarRocks ...。同时它对于 MySQL 协议的全兼容,很大程度上方便了业务开发,可以直接使用 MySQL Client 或者 JDBC 的驱动来开发对接。”
再加上持续宣传带来的高存在感和本土开源软件天然具备的语言优势。使得业务开发人员有较高的意愿尝试将Doris或StarRocks用到业务场景中。
- 有哪些需求/痛点?
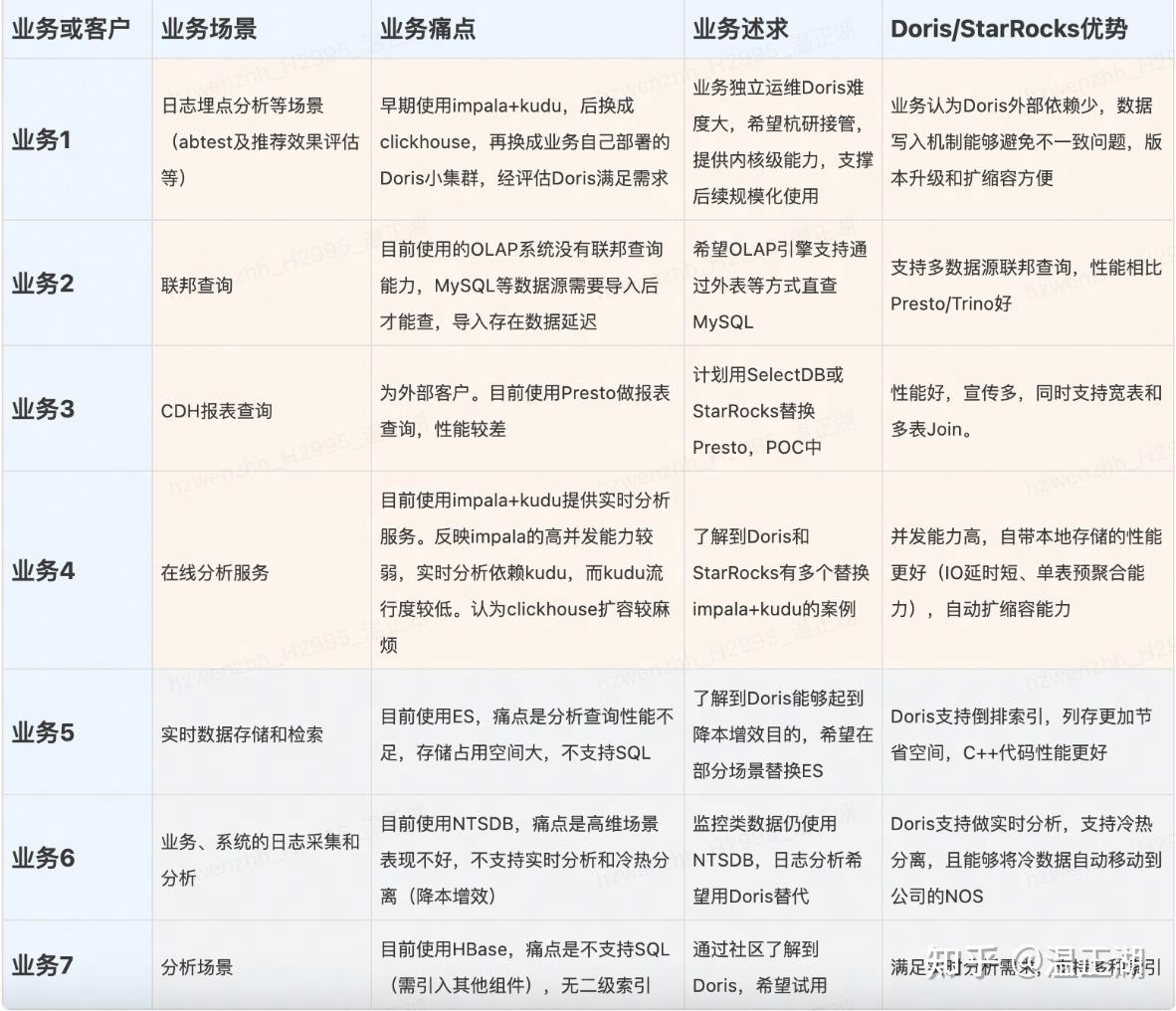
分析上述需求,可以大致分为两类:一类是为了简化系统架构,希望单个OLAP引擎能够提供较全面的能力,即支持实时数据分析,又支持Hive表、MySQL表和数据湖表格式等多数据源的查询和Join能力。如下面为严选业务的分享内容:
“离线数据大部分存储在 Hive 中,小部分存储在 Hbase(主要用于基础标签的查询)。实时数据一部分存储在 Hbase 中用于基础标签的查询,部分双写到 KUDU 和 ES 中,用于实时分组圈选和数据查询。离线圈选的数据通过 impala 计算出来缓存在 Redis 中。 这一版本的缺点包括:存储引擎过多。双写有数据质量隐患,可能一方成功一方失败,导致数据不一致。项目复杂,可维护性较差。为了减少引擎和存储的使用量,提高项目可维护性,在版本一的基础上改进实现了 版本二。”
另一类是为了降低存储成本、提高使用体验。比如通过冷热分离(冷数据转对象存储)或依靠列存的高压缩特点等降低存储成本,或者是通过标准的SQL来降低使用难度。
存在的价值
笔者认为Doris和StarRocks最大的价值在于其全面的分析能力,一个引擎能够解决大部分业务需求,不需要部署多个系统来分别满足不同的业务需求。下面引用网易邮箱团队的一次分享作为佐证:
“网易邮箱从 21 年开始接触 StarRocks,到现在一年多的时间里,作为一个刚刚崭露头角的 OLAP 系统,StarRocks 在各方面的表现都很不错,它在功能、性能以及覆盖的场景方面的表现,都让我们相当满意,甚至超出了我们当初的预期。”
在这种情况下,业务只需要专研一个系统,这样能够大大减小业务的学习成本、降低系统运维复杂度、减少不必要的数据副本、避免数据跨系统拷贝导致的数据延迟和任务开销。如下面为严选业务的分享内容:
" 存储架构 版本二引入了 Apache Doris,离线数据主要存储在 Hive 中,同时将基础标签导入到 Doris,实时数据也存储在 Doris,基于 Spark 做 Hive 加 Doris 的 联合查询,并将计算出来的结果存储在 Redis 中。经过此版改进后,实时离线引擎存储得到了统一,性能损失在可容忍范围内(Hbase 的查询性能比 Doris 好一些,能控制在 10ms 以内,Doris 目前是 1.0 版本,p99,查询性能能控制在 20ms 以内,p999,能控制在 50ms 以内); 项目简化,降低了运维成本。"
有一个专有名词来表示符合这样要求的系统,那就是LakeHouse,Doris和StarRocks是国内目前最接近LakeHouse要求的OLAP引擎。
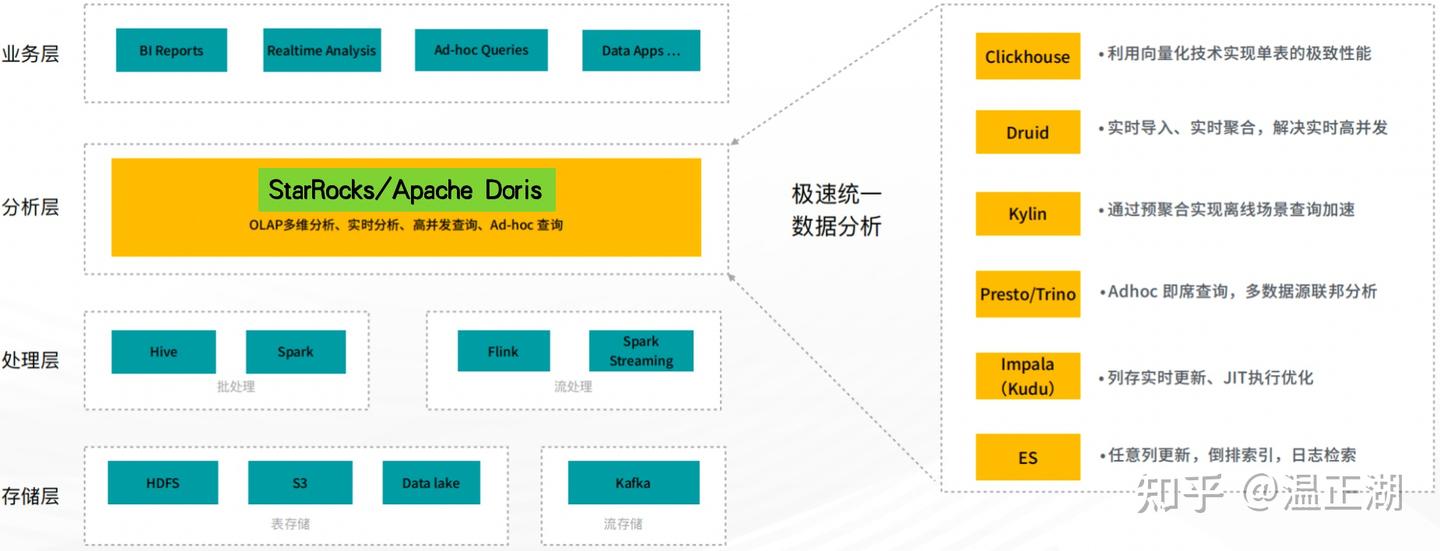
(图片来自StarRocks,做了小改)
Doris vs StarRocks
不讨论Doris和StarRocks是否能够完全取代其他OLAP引擎,凭借目前已经具备的全面能力以及还在高速发展的现实,可以确定的是他们至少能够在数据湖仓分析场景占有重要的一席之地。下面梳理下他们的发展脉络:
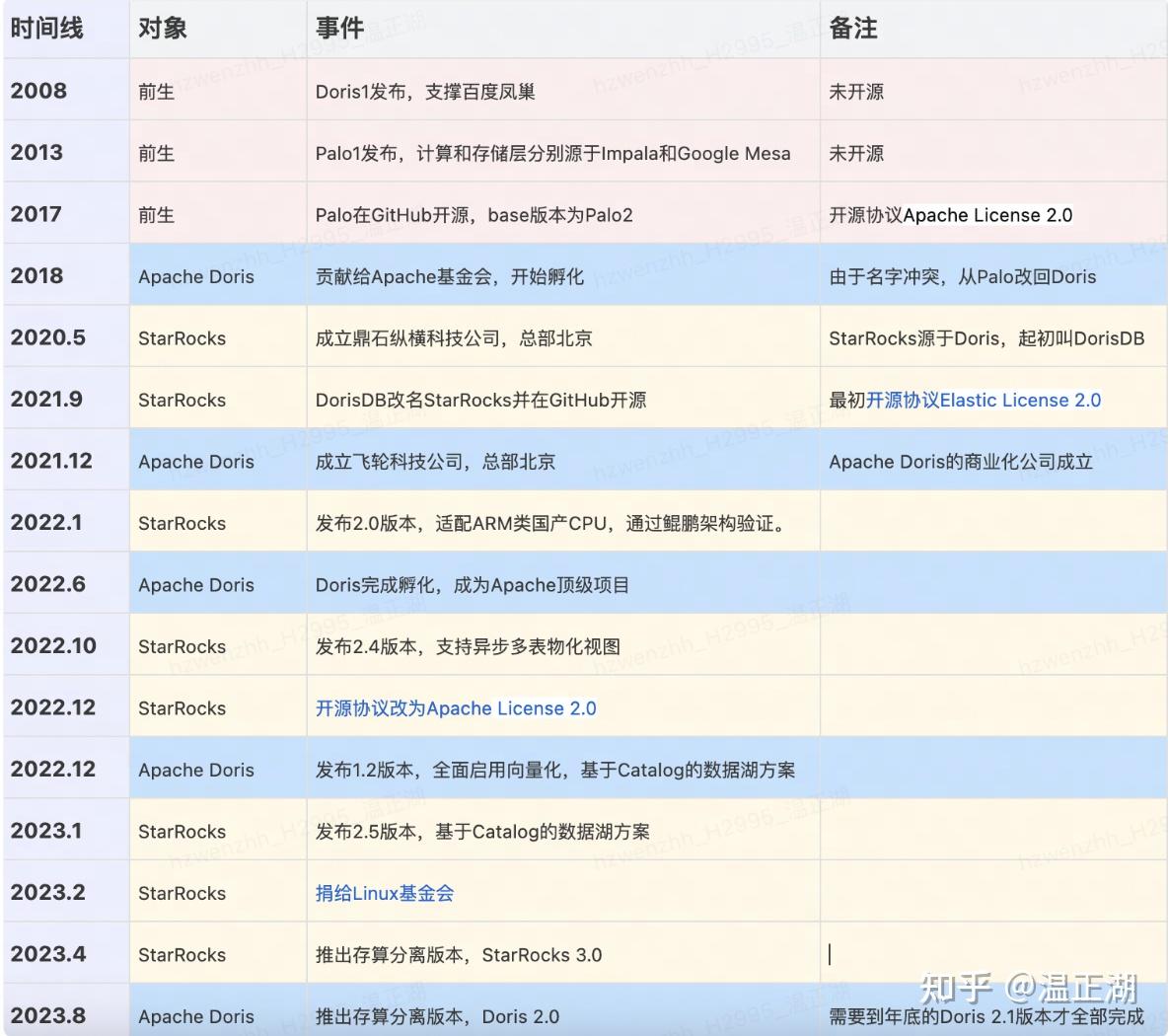
由于两者相同的出身,且目前所支持的功能上也属于你追我赶的状态,两者的相似度很高,那么他们是否能够长期共存,哪个引擎能够笑到最后呢?本文尝试从功能丰富度、开源社区、云平台支持度、市场与融资、信创建设、内部需求等维度来进行比较。
功能多角度对比

总的来说,Doris和StarRocks在功能特性上没有太大差别,就算某些特性暂时领先,也不代表短期内不会发生变化。但相对来说,笔者认为在数据湖分析(多表Join等)和存算分离场景,StarRocks相对领先,其多表物化视图能力及使用愿景,很吸引人,更多内容详见智能的物化视图。在传统的OLAP查询分析场景,Doris具备一定的优势,包括高并发点查优化、倒排索引能力等,StarRocks虽然也宣传支持倒排索引,但看官方介绍是基于bitmap索引实现,能力不如Doris。
开源社区
开源协议
两者均为Apache License 2.0,只不过加入的开源组织不一样,Doris加入了Apache基金会,StarRocks加入了Linux基金会。在大数据领域,Apache基金会的接受度更高一些,社区权力更大些。
社区建设
从关注度数据来看,Doris领先。具体数据如下:
- StarRocks:5.7k stars、133 watching、1.2k forks
- Doris: 9.9k stars、265 watching、2.8k forks
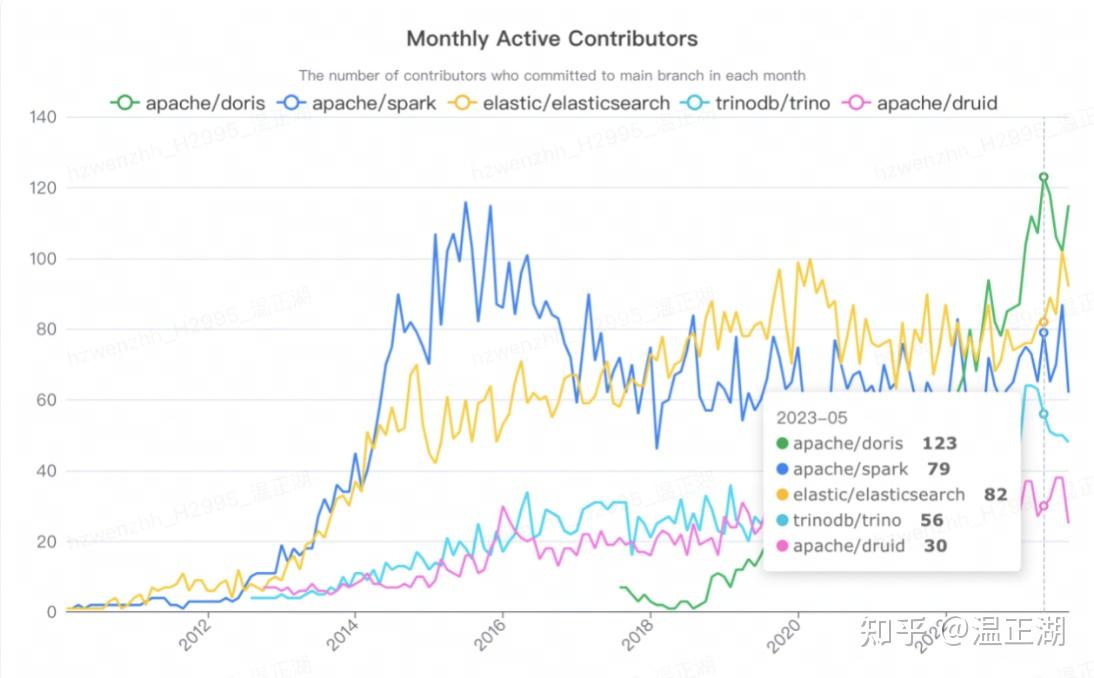
再看看实际活跃度,相对来说,还是Doris领先,从Contributions to main图可以看出,项目主要是商背后的商业化公司在主导,可以看到从2022开始,Doris的数据快速爬坡,追到与StarRocks同个水平。具体数据如下:
- StarRocks:
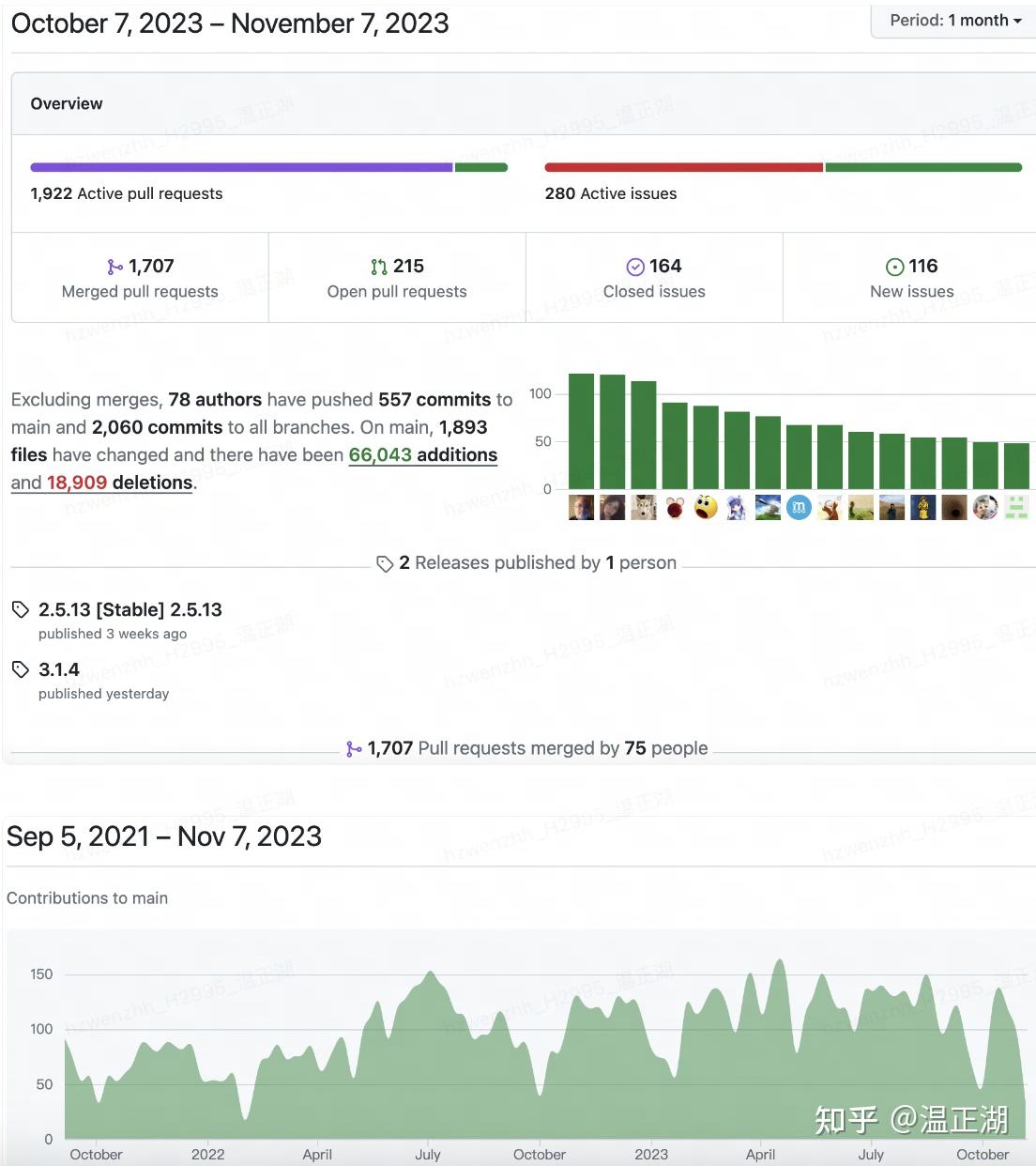
- Doris:
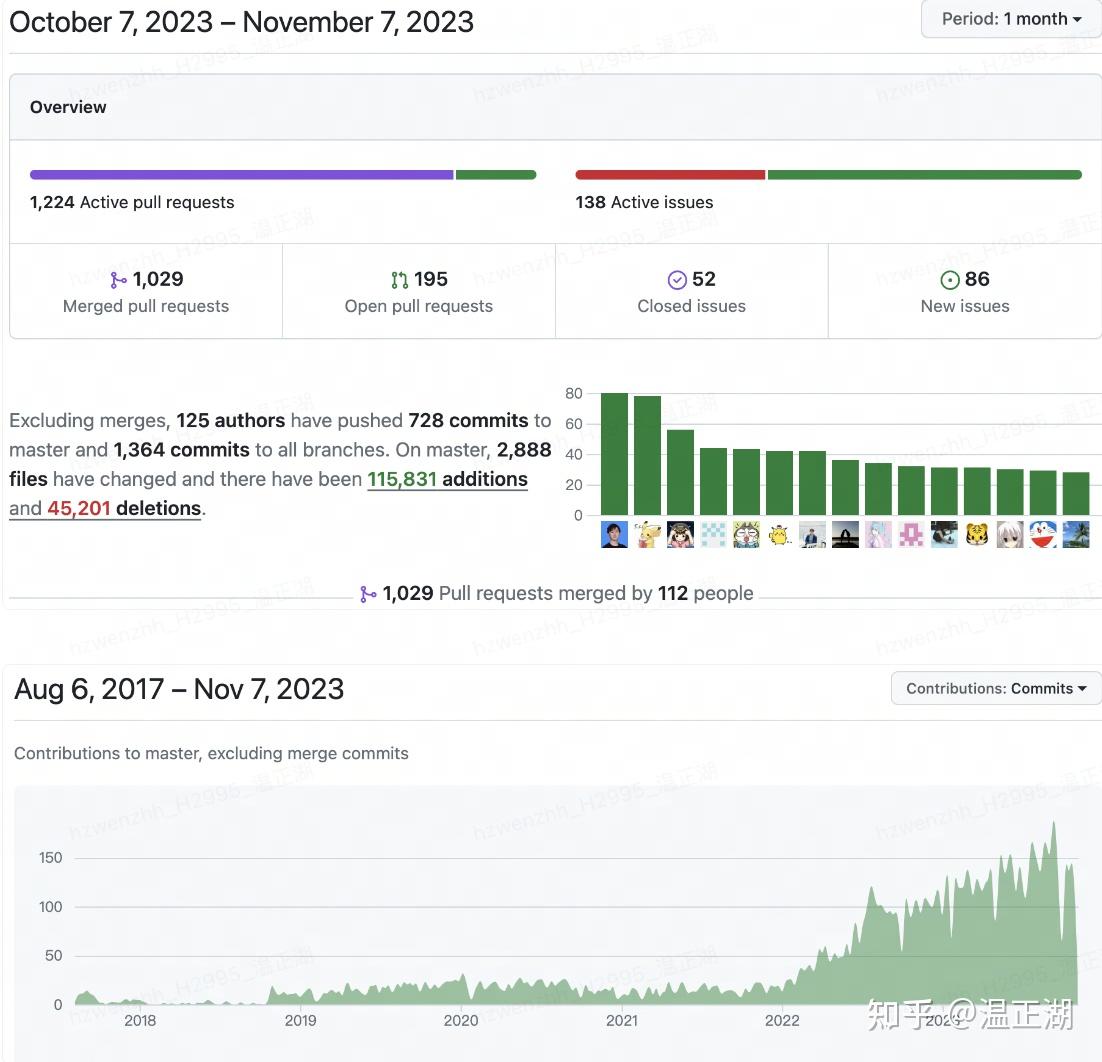
总的来说,笔者认为Doris在开源社区这块领先于StarRocks。根据Doris提供的数据,目前活跃贡献者规模在开源大数据项目中居全球第一。
云平台支持度
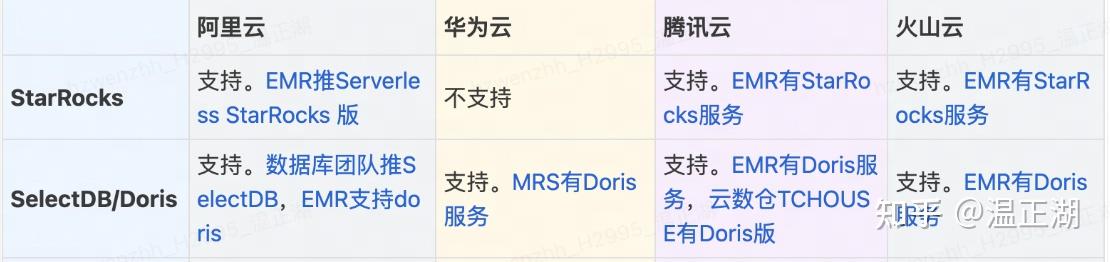
可以看出,在公有云平台支持度上,Doris似乎领先于StarRocks。
市场开拓
Apache Doris号称在全球范围的用户规模已经超过了 4000 家。而StarRocks表示当前全球超过 300 家市值 70 亿元以上的头部企业都在基于 StarRocks 构建新一代数据分析能力。这块无法详细对比。
融资金额
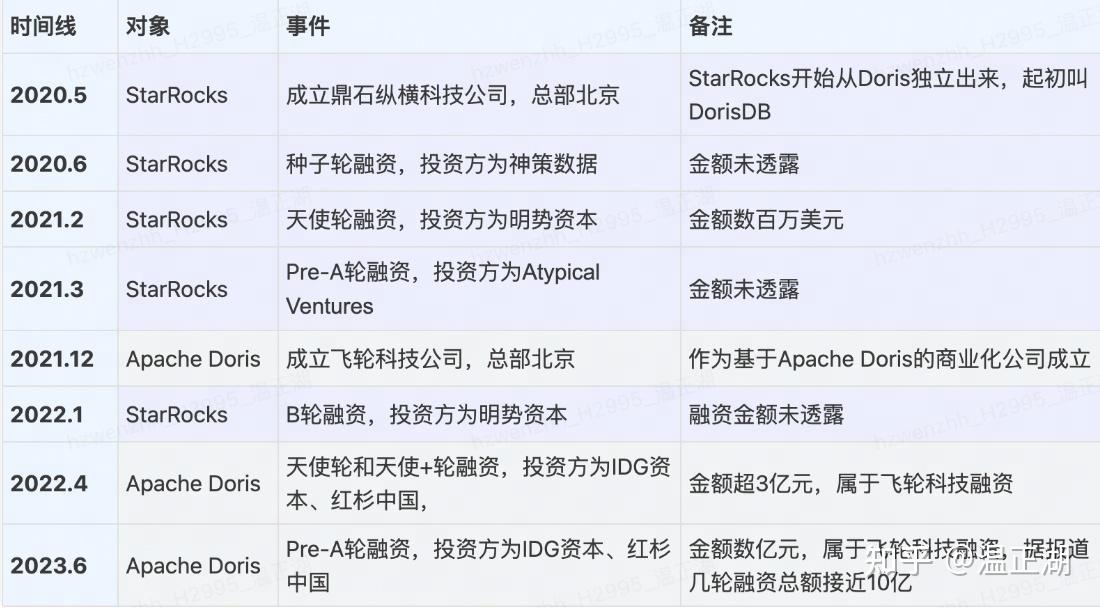
2020年5月成立鼎石纵横科技,B轮,目前的投资方包括神策数据、明势资本和Atypical Ventures。SelectDB于2021年12月作为基于Apache Doris的商业化公司成立,Pre-A轮融资,总融资近10亿元,投资方包括IDG资本、红杉中国等,相对来说,SelectDB的投资方更有名。关键事件汇总如下:
信创建设
均通过可信数据库认证
- StarRocks:2022年1月发布的2.0版本,适配了ARM类国产CPU,通过鲲鹏架构验证
- SelectDB:2023年2月,与兆芯、飞腾、海光信息、统信软件、中科可控、麒麟软件共计6家生态企业完成了产品兼容互认证。支持ARM CPU架构
汇总分析
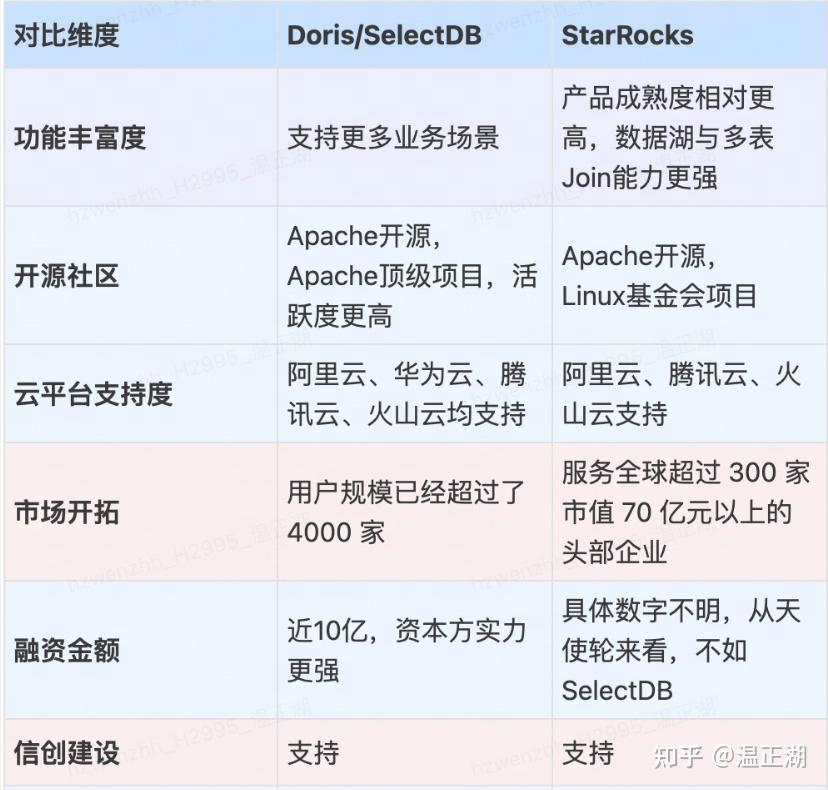
Apache Doris/SelectDB开始商业化的时间较晚,在部分产品特性的成熟度相比StarRocks低(主要是数据湖和存算分离方向),但考虑到Apache Doris全球Top级别的社区活跃度、较大规模的研发团队和较多的融资储备,以及相比StarRocks没有明显的缺陷。目前存在的劣势也不见得就无法在未来一两年时间逐渐消除。
如果要在线上服务上使用Doris或StarRocks,需要经过一段时间试用,可能需要在可用性、安全性和稳定性上做一些妥协。比如要用作数据湖查询,那么Hive表元数据缓存同步机制上还不够完善,需要较长时间打磨才能满足生产环境要求,可能需要做些手动的同步操作。再比如查询中间结果溢出(spill to disk),Doris还在发展中,StarRocks也是最新版才加入,还不够成熟。需要有一定时间打磨快速开发的大量功能特性。
总的来说,两者都还在高速发展中,站在目前这个阶段就分出孰优孰劣很难,鹿死谁手犹未可知。至于大家该选择谁,主要取决于对比测试情况,商务情况以及团队自身的好恶。或许目前的选择可能都是暂时的,不存在一朝选错,无法挽回的情况。持续保持关注!!


















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









