







额外知识点
飘号和去重
- 飘号:
用来区分关键字和字段名
==举例说明:==假如此时你需要从一个表中选取一个名为“select”的字段列,而该字段列与关键字select重名,所以此时为了让系统知道字段名是字段名则需要为该字段名加上飘号,如下:
SELECT `select`
from 表名
去重(distinct):
举例说明
例子:查询所有有员工的部门的部门号
如果按照此代码写则最后结果会出现重复的部门号,如下:
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL;

为了让其不重复显示则加上distinct,如下:
SELECT DISTINCT department_id
FROM employees
WHERE department_id IS NOT NULL;

“=” 和 IS的区别
在 SQL 中,使用 = 和 IS 都可以进行条件过滤。但它们的使用方式和意义是不同的。当需要比较两个确定的值时,应该使用 =,而当需要判断一个值是否为 NULL 时,应该使用 IS。
函数
单行函数
定义:进去一条函数出来一条函数
大小写控制函数
LOWER('SQL'):将字符串内容全部变为小写
UPPER('SQL'):将字符串内容全部变为大写
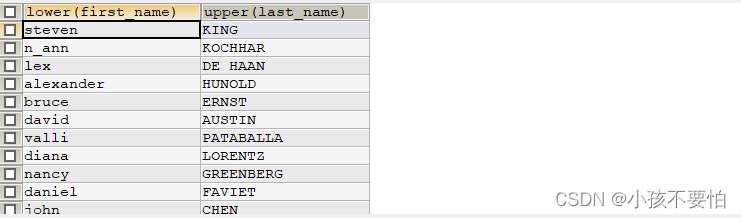
例题1:将员工的first_name全部变为小写字母,将last_name全部变为大写字母
SELECT LOWER(first_name), UPPER(last_name)
FROM employees;
字符控制函数
CONCAT('HELLO', 'WORLD')—字符串拼接。结果:HELLOWORLD
SUBSTR('HELLOWORLD', 1, 5)—显示出从第1个位置开始长度为5的字符串。结果:HELLO
LENGTH('HELLOWORLD')—显示内容的长度。结果:10
INSTR('HELLOWORLD', 'W')—显示某个字符在字符串中首次出现的位置,结果:6
LPAD(salary, 10, '*')—向右对齐,若内容长度不够10用*补 RPAD(salary, 10, '*')—向左对齐,若内容长度不够10用*补
TRIM('H' FROM 'HELLOWORLD')—去除字符串两端指定的字符。结果:ELLOWORLD
REPLACE('abcd', 'b', 'm')—将字符串中所有的b替换为m
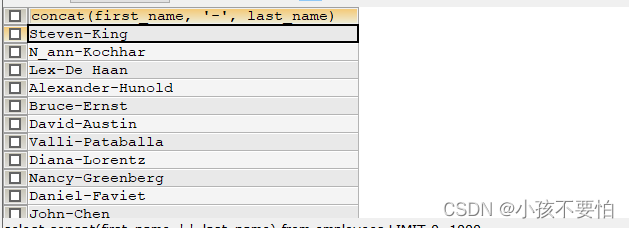
例题1:将员工的first_nam e和last_name拼接起来
SELECT CONCAT(first_name, '-', last_name)
FROM employees;
例题2:显示出”asdfghjkl“的”ghj“
SELECT SUBSTR('asdfghjkl', 5, 3);

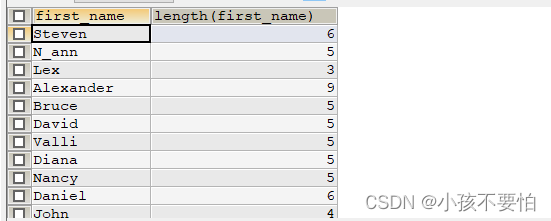
例题3:显示所有员工first_name的长度
SELECT first_name,LENGTH(first_name)
FROM employees;
例题4:将员工薪水分别向左对齐和向右对齐,内容长度为10,若内容长度不够则用*补充
SELECT LPAD(salary, 10, '*'), RPAD(salary, 10, '*')
FROM employees;

例题5:TRIM
SELECT TRIM('H' FROM 'HHHHHHHHAHHHBHHHHH');

通用函数
IFNULL(字段名,默认值):若字段的内容为null,则用默认值替换
例题1:#查询所有员工的工资(工资+奖金)
SELECT salary + IFNULL(commission_pct, 0) * salary 工资
FROM employees;
case表达式
方式一
case表达式
case 字段名
when 值1 then 返回值1
when 值2 then 返回值2
when 值3 then 返回值3
else 返回值4
end
/*解释
当字段名的值是值1时返回返回值1
当字段名的值是值2时返回返回值2
当字段名的值是值3时返回返回值3
若都不满足则返回返回值4
*/
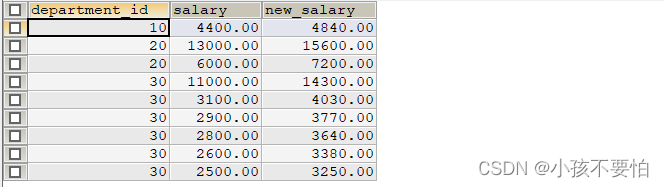
例题1:查询部门号为10,20,30的员工信息,若部门号为10,则打印其工资的1.1倍;20号部门则打印其工资的1.2倍;30号部门则打印其工资的1.3倍
SELECT department_id, salary,
CASE(department_id)
WHEN 10 THEN salary * 1.1
WHEN 20 THEN salary * 1.2
WHEN 30 THEN salary * 1.3
ELSE salary
END new_salary
FROM employees
WHERE department_id IN(10, 20, 30);
方式二
CASE
WHEN 表达式1 THEN 返回值1
WHEN 表达式2 THEN 返回值2
WHEN 表达式3 THEN 返回值3
ELSE 返回值4
END
/*解释:
表达式可以是条件句
*/
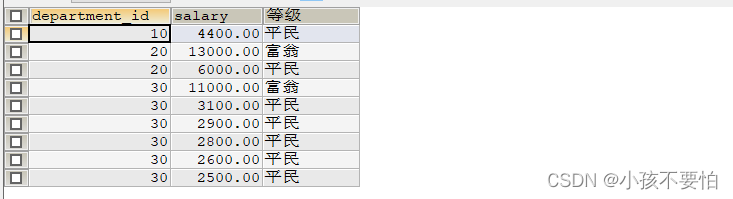
例题2:查询所有员工的薪水,如果大于10000则显示富翁,如果小于10000则显示平民,如果等于10000则显示好家伙
SELECT department_id, salary,
CASE
WHEN salary > 10000 THEN "富翁"
WHEN salary < 10000 THEN "平民"
ELSE "好家伙"
END AS 等级
FROM employees
WHERE department_id IN(10, 20, 30);
分组函数
SELECT 字段名1, 字段名2, ...
FROM 表名
WHERE 过滤条件------分组前的过滤条件,WHERE后不可使用组函数
GROUP BY 字段名1, 字段名2, ...
HAVING 过滤条件------分组后的过滤条件,HAVING后可使用组函数, 且HAVING一般不单独用,常和GROUP BY一起使用
ORDER BY 字段名1 ASC/DESC, 字段名2 ASC/DESC, ...;
解释:
GROUP BY 字段名1, 字段名2, ...先根据字段名1进行分组,然后再按照字段名2进行分组
==注意:==WHERE 语句要写在GROUP BY 之前,否则会报错
分组函数的分类
AVG():求平均值
注意:求平均值时不包括该列的null。举例说明:假如一个字段名列的共有20个数据,其中5个null。该字段名总和为sum,则平均值为sum/(20-15)
-
SUM():求和 -
MAX():求最大值 -
MIN():求最小值
例题1:求所有员工薪水的最大值、最小值、平均值、总和
SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees;

count(字段名):统计该字段中非空数值(即不是null)的数量
count(*):统计查询的结果有多少条数据.也就是说统计表中共有多少条数据
count(数值):和COUNT(*)作用一样
SELECT COUNT(commission_pct), COUNT(*), COUNT(1)
FROM employees;

注意事项
1.
AVG()和SUM()两个函数只能对数值类型做运算2.select后面出现组函数后将不能在出现其他字段,除非该字段出现在group by的后面。如下:
错误写法
SELECT first_name, AVG(salary) FROM employees; /*错误原因: select后同时出现在字段和组函数 */正确写法
例题2:查询各部门的最高薪水
SELECT department_id,MAX(salary) FROM employees WHERE department_id IS NOT NULL GROUP BY department_id;3.在WHERE后面不允许出现组函数否则会报错,如下图所示,正确详见例题4
例题3:查询各部门中不同的工种的最低薪水是多少
SELECT department_id, job_id, MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id, job_id;
==注意:==在WHERE后面不允许出现组函数
例题4:查询在10,20,30号三个部门中,平均薪水大于5000的部门
SELECT department_id, AVG(salary)
FROM employees
WHERE department_id IN(10,20,30)
GROUP BY department_id
HAVING AVG(salary) > 5000;
/*
WHERE------分组前的过滤条件,WHERE后不可使用组函数
HAVING------分组后的过滤条件,HAVING后可使用组函数,且HAVING一般不单独用,常和GROUP BY一起使用
*/
解释:由于要查找分完组之后的平均薪资大于5000的部门,所以需要把薪资大于5000的条件卸载写在HAVING后面
子查询(嵌套查询)
定义:
子查询指的是在 SQL 语句中嵌套使用的查询语句,也称为嵌套查询。子查询通常被用作一个表达式,用于从一个查询的结果集中提取另一个子集。
子查询可以嵌套在 SELECT、FROM、WHERE 或 HAVING 子句中,用于执行更复杂的查询操作
子查询分类
单行子查询
定义:
子查询的结果只有一条,即嵌套到里面的儿子代码的结果只有一条
单行子查询使用的运算符:> < >= <= <> =
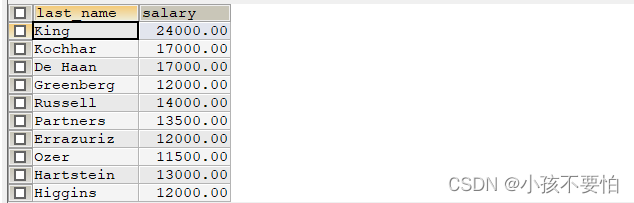
例题1:查询谁的工资比last_name = 'Abel’的高
方法一:自连接(内连接)
SELECT e1.`last_name`, e1.`salary`
FROM employees e1 JOIN employees e2
ON e1.`salary` > e2.`salary` AND e2.`last_name` = 'Abel';
方式二:子查询
SELECT last_name, salary
FROM employees
WHERE salary > (SELECT salary
FROM employees
WHERE last_name = 'Abel');
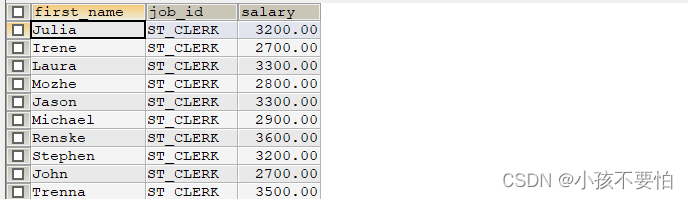
例题2:返回job_id与141号员工相同,salary比143号员工多的员工姓名、job_id和工资
SELECT first_name, job_id, salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id = 141
) AND salary > (
SELECT salary
FROM employees
WHERE employee_id = 143
);
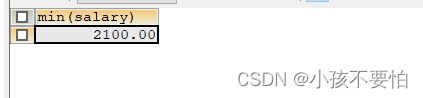
例题3:返回工资最少的员工的last_name,job_id和salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
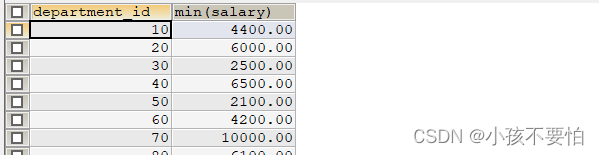
例题4:查询最低工资大于50号部门最低工资的部门id和其他最低工资
SELECT department_id, MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id;
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
);
多行子查询
定义:
子查询的结果有多条,即嵌套到里面的儿子代码的结果有多条
举例说明
如下子查询代码的返回结果不止一行则会报错
SELECT first_name, salary
FROM employees
WHERE salary = (
SELECT salary
FROM employees
);

==多行子查询使用的运算符:==in any all
| 运算符 | 举例 | 举例 | |
|---|---|---|---|
| in | in(子代码结果) | 代表可取子查询的多个结果 | salary in (1000,2000,3000) |
| any | any(子代码结果) | 代表any中的任何一个。注意:any前要有> < >= <= <>等符号的任一个,当为=时,其与in意思一样 | salary>any(1000,2000,3000) |
| all | all(子代码结果) | 代表all中的所有。注意:all前要有> < >= <= <> =等符号的任一个 | salary > all(1000,2000,3000) |
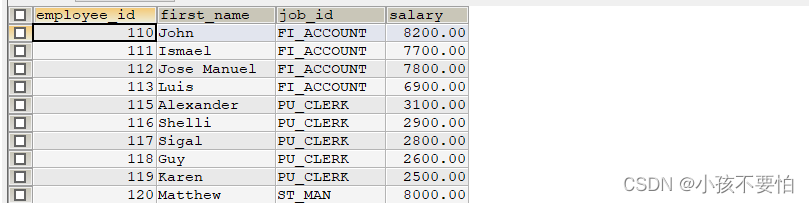
例题1:返回其它部门中比job_id = 'IT PROG’部门任意一个工资低的员工的员工号、姓名、job_id、salary
SELECT employee_id, first_name, job_id, salary
FROM employees
WHERE salary < ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id <> 'IT_PROG';
#DISTINCT作用是去重,去除薪水一样的行
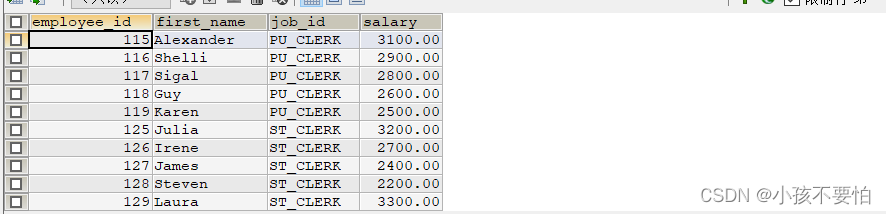
例题2:返回其它部门中比job_id = 'IT PROG’部门的所有工资低的员工的员工号、姓名、job_id、salary
SELECT employee_id, first_name, job_id, salary
FROM employees
WHERE salary < ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id <> 'IT_PROG';
















 2152
2152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











