







文章目录
一、基本概念
1) 方差和偏差
- 偏差:偏差度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力。
- 方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即刻画了数据扰动所造成的影响。
我们总是希望选择低偏差和低方差的模型,但是偏差和方差在一定程度上是矛盾的。如果偏差降低,那方差可能会相应的升高,如果方差降低,那偏差可能相应升高。所以我们是尽量的寻求偏差和方差的一个平衡点。
下图比较形象的表达偏差和方差的含义:

可以看到,偏差越大,点集整体越脱离靶心;而方差越大,点集整体越离散。
2) 欠拟合与过拟合
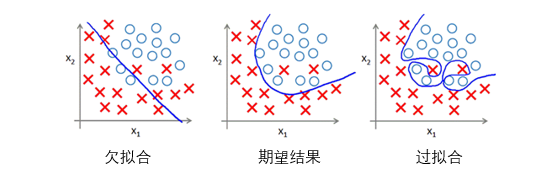
- 欠拟合(Underfit):也被称为high bias,模型的经验误差大,模型太简单,在训练的过程中基本没学到有价值的内容,说明模型欠拟合。
- 过拟合(Overfit):也被称为high viarance,模型学习了太多的训练样本的“个性”(经验误差小),但是对于未知的样本泛化能力差(泛化误差大),说明过拟合。
下图比较形象的表达欠拟合和过拟合的含义:
也可以通过学习曲线来识别模型是否发生了欠拟合、过拟合。
如下图所示:横轴为训练样本数量,纵轴为误差

模型欠拟合时,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大;模型过拟合时,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。模型正常时,在训练集以及测试集上,同时具有相对较低的偏差以及方差。
可以发现:当模型欠拟合的时候,我们发现增大训练集,偏差无法降低,无法解决欠拟合问题;当模型过拟合的时候,我们发现增大训练集,方差减小,可以解决过拟合问题。
3) 经验风险和结构风险
- 经验误差:模型关于训练样本集的平均误差(也称经验风险)。
- 结构风险:结构风险在经验风险的基础上加上表示模型复杂度的正则化项。
虽然可以使用经验损失近似估计期望风险,但是大数定理的前提是N无穷大,实际上,我们的训练集一般不会特别大,此时就需要对经验风险做出适当调整才能近似估计。因此引入结构风险。
结构化风险是为了缓解数据集过小而导致的过拟合现象,其等价于正则化,本质上反应的是模型的复杂度。认为经验风险越小,参数越多,模型越复杂,因此引入对模型复杂度的惩罚机制。公式如下:
R ( f ) = 1 n ∑ i = 1 n L ( y i ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









