









简介
Towards Real-Time Multi-Object Tracking是一个online的多目标跟踪(MOT)算法,基于TBD(Traking-by-Detection)的策略,在之前的MOT算法中惯用的策略就是先检测,得到视频中目标bbox,然后再考虑前后帧的匹配策略,为了更好的匹配效果,一般匹配中都会加入Re-ID,文章中把Re-ID等同于embedding,即一般方法中,detection model和embedding model是分开,独立的。而《Towards Real-Time Multi-Object Tracking》中将detection model和embedding model整合为一个模型,即Joint Detection and Embedding (JDE) model,所以我们用JDE作为《Towards Real-Time Multi-Object Tracking》的简称。
《Towards Real-Time Multi-Object Tracking》原理
contributions
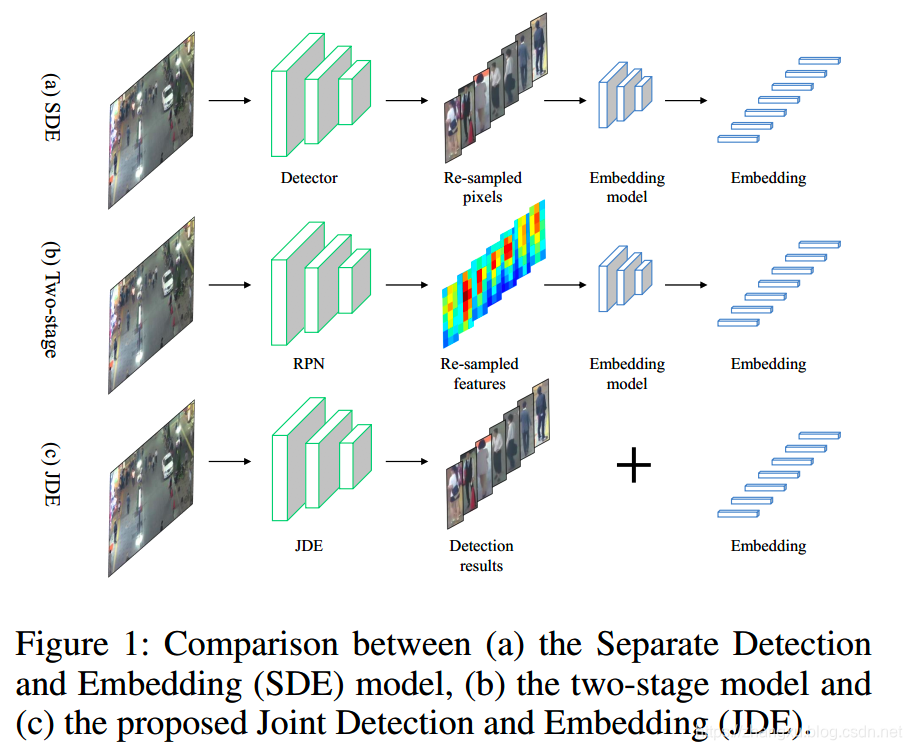
JDE核心思想是一种联合检测和嵌入向量的模型,即Joint Detection and Embedding model,既然是tracking by detection的策略,那么检测模型是必不可少的,剩下的embedding在前后帧的ID匹配过程中起到关键的作用,而JDE提出了这两部分共享一个模型,与之对应的就是Separate Detection and Embedding (SDE) model,即检测和后续的Embedding是分开的,独立的两个部分,后续ID匹配的过程只需要检测模型提供bbox就可以,和检测模型本身并没有任何关系,SDE model的典型代表就是DeepSort。
除此之外,JDE的contributions有:
- Joint Detection and Embedding model,与之对应的训练策略;
- 实验对比JDE相比于SDE方法的优势,尤其在速度上;
- 在MOT-16 上,JDE接近state-of-the-art。
Forwaord
Joint Detection and Embedding
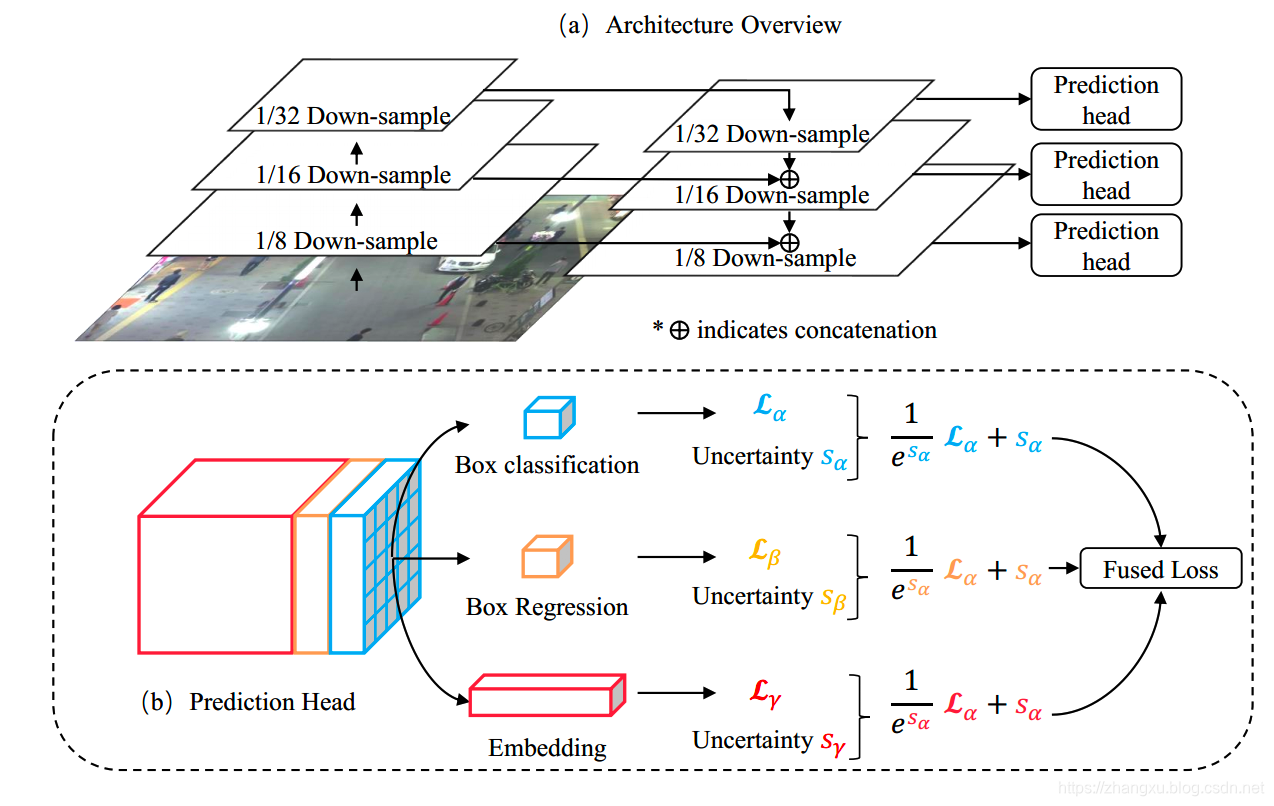
JDE的基础检测模型,用了FPN结构,一共有三层,分别做
1
32
\frac{1}{32}
321,
1
16
\frac{1}{16}
161和
1
8
\frac{1}{8}
81的下采样,每一层都会接出预测头(Predicion Head),而预测头除了常规的分类和定位分支外,会加上一个Embedding分支,这个分支后续用来做Re-ID。三个分支的Shape分别是:
- classification results : 2 A × H × W 2A\times H\times W 2A×H×W
- regression coefficients: 4 A × H × W 4A\times H\times W 4A×H×W
- dense embedding map:
D
×
H
×
W
D\times H\times W
D×H×W
其中A是anchor的数量,embedding特征图的厚度是D。这种分支的形式就联合了检测模型和Re-ID模型,将两者合并为一个。Embedding分支的思路非常像 CornerNet,CornerNet中需要用Embedding判断哪两个点应该属于一个object,而JDE中则是判断哪两个object是一个ID,只不过,这两个相同的ID一定在前后帧上。
Post-processing
既然是前后帧的匹配,前一帧的输出信息需要被保留下来,当前帧同样输出三个分支信息后,根据Embedding结果进行匹配,Embedding layer输出为
D
×
H
×
W
D\times H\times W
D×H×W,特征图宽高的维度和检测输出的特征图是一致的,特征图中每一个位置都是一个潜在的object,这也就意味着,每一个object的embedding vector的维度都是D,在源码中这个
D
=
512
D=512
D=512,而具体是不是目标,以及目标的位置就由另外两个分支决定了。
得到了前一帧后当前帧的所有目标,以及embedding vector后,依照下面的过程进行匹配,假设前一帧的目标数量为
m
m
m,当前帧的目标数量为
n
n
n:
- 根据检测的信息,拿到Embedding feature map上对应的embedding vector,当前帧 f c f_{c} fc有 n n n个目标,维度为 D D D;
- 前一帧 f c − 1 f_{c-1} fc−1有 m m m个目标,需要注意的是,处理短暂的object lost已经是现在MOT方法的标配,也就是说如果检测器不准,或者目标出现遮挡,在某一帧中目标没有被检测出来,但是之后几帧又回再次出现,此时跟踪算法不应该出现ID switch,所以 f c − 1 f_{c-1} fc−1帧的 m m m个目标中,要加上 f c − 1 f_{c-1} fc−1帧之前ID losted的情况,假设有 k k k个,所以总的ID数量就是 m + k m+k m+k;
- f c − 1 f_{c-1} fc−1帧得到 m + k m+k m+k个目标,当前帧 n n n个目标的embedding vector两两计算余弦距离,并与0比较较大值,生成一个 ( m + k ) × n (m+k)\times n (m+k)×n的距离矩阵:cost_matrix;
- 根据卡尔曼估计更新cost_matrix,具体做法为:估计前一帧的object在下一帧的位置,这个位置由和当前帧检测到的实际位置计算距离,显然这个距离矩阵又是 ( m + k ) × n (m+k)\times n (m+k)×n的,而这个距离大于一个设定阈值的话,cost_matrix中对应位置将被置为正无穷,即绝对不可能是同一个ID。这一点和DeepSort很相似;
- 在cost_matrix中卡阈值,选择小于阈值的距离,这就是为什么上一步中会选择置为无穷大;
- 二次关联,使用的是IOU距离,不过计算IOU的bbox是由两次检测得到的,而不是卡尔曼滤波器估计得到的,然后再次卡阈值;
- new ID and lost ID,如果 f c f_{c} fc帧 n n n个目标有一个bbox没有和之前的任何ID匹配上,那只能创建一个新的ID,相对应的,如果 f c − 1 f_{c-1} fc−1帧中有ID没有匹配到 f c f_{c} fc帧,那么就继续作为ID lost,留作下次更新;
- 更新状态,卡尔曼估计是非常不准的,所以卡尔曼滤波器的状态要一直根据检测结果做更新,让它每次都只预测下一帧;
- 更新ID losted,保留先前丢失ID的做法可以有效改善ID switch,但是如果跟踪一直做,那么ID losted就越来越多,时间越久就越不可能被找回来,并且加重了计算的负担,所以ID losted需要根据已经丢失的帧数做清理,清理之后,就没有任何再找回来的可能了。
实验结果
定量结果
| Method | Det | Emb | #box | #id | MOTA | IDF1 | MT | ML | IDs | FPSD | FPSA | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepSORT 2 | FRCNN | WRN | 429K | 1.2k | 61.4 | 62.2 | 32.8 | 18.2 | 781 | <15∗ | 17.4 | <8.1 |
| RAR16wVGG | FRCNN | Inception | 429K | - | 63.0 | 63.8 | 39.9 | 22.1 | 482 | <15∗ | 1.6 | <1.5 |
| TAP | FRCNN | MRCNN | 429K | - | 64.8 | 73.5 | 40.6 | 22.0 | 794 | <15∗ | 18.2 | <8.2 |
| CNNMTT | FRCNN | 5-Layer | 429K | 0.2K | 65.2 | 62.2 | 32.4 | 21.3 | 946 | <15∗ | 11.2 | <6.4 |
| POI | FRCNN | QAN | 429K | 16K | 66.1 | 65.1 | 34.0 | 21.3 | 805 | <15∗ | 9.9 | <6 |
| JDE-864(ours) | JDE | - | 270K | 8.7K | 62.1 | 56.9 | 34.4 | 16.7 | 1,608 | 34.3 | 81.0 | 24.1 |
| JDE-1088(ours) | JDE | - | 270K | 8.7K | 64.4 | 55.8 | 35.4 | 20.0 | 1,544 | 24.5 | 81.5 | 18.8 |
从上表中可以看出:
- JDE的速度要比SDE快很多,就是网络结果决定的,SDE的方法在做Re-ID时,受限于目标数量的;
- JDE的IDs控制的并不好,可能由于联合的Re-ID效果不如单独的Re-ID。
总结
JDE合并检测和Re-ID模块可以有效的提高效率,避免受限于目标数量的Re-ID的特征提取耗时,但是带来的是检测模型和Re-ID模型的高度耦合,检测和匹配不再是独立的两个部分,如果想要改变其中一个,另一个也必须要变。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









