








特别喜欢一句话:不是因为看到了希望才去坚持,而是因为坚持了才会看到希望。
1、现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行?
思路:多线程之间怎么协同工作,如何让一个线程执行完毕后处于什么状态。
Thread t1 = new Thread(new T1());
Thread t2 = new Thread(new T2());
Thread t3 = new Thread(new T3());
t1.start();
t1.join();
t2.start();
t2.join();
t3.start();
t3.join();
或者使用第二种方法,在t2里边放入t1.join(),在t3里边放入t2.join()
为什么使用了join方法呢?
熟悉一下jdk join方法的源码就会了解:
public final synchronized void join(long millis) throws InterruptedException{
long base = System.currentTimeMills();
long now = 0;
if(millis < 0){
throw new IllegalArgumentException("timeout value is negative");
}
if(millis == 0){
while(isAlive()){
wait(0);
}
}else{
while(isAlive()){
long delay = millis-now;
if(delay <= 0){
break;
}
wait(delay);
now = System.currentTimeMillis()-base;
}
}
}
线程会一直循环isAlive(),知道false,关键词:join
2、java中的++i操作是线程安全的吗,为什么?如何使其线程安全呢?
思路:synchronized、AtomicInteger(valitile)
AtomicInteger,一个提供原子操作的Integer类,在java语言中,++i和i++操作并不是线程安全的,在使用的时候,不可避免的会用到synchronized关键字,而AtomicInteger则通过一种线程安全的加减操作接口。
我们接下来看一下AtomicInteger类的jdk源码:
private volatile int value;
/**
* Creates a new AtomicInteger with the given initial value.
*
* @param initialValue the initial value
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
/**
* Creates a new AtomicInteger with initial value {@code 0}.
*/
public AtomicInteger() {
}
/**
* Gets the current value.
*
* @return the current value
*/
public final int get() {
return value;
}
/**
* Sets to the given value.
*
* @param newValue the new value
*/
public final void set(int newValue) {
value = newValue;
}
为什么不用计数器自加呢,例如count++,因为这种计数是线程不安全的,高并发访问时统计会有误,而AtomicInteger为什么能够达到坐怀不乱,应付自如呢?不难发现其private volatile int value;
大家可以看到有这个变量,value就是你设置的自加起始值。注意看它的访问控制符,是volatile,这个就是保证AtomicInteger线程安全的根源,熟悉并发的同学一定知道在java中处理并发主要有两种方式:
1,synchronized关键字,这个大家应当都各种面试和笔试中经常遇到。
2,volatile修饰符的使用,相信这个修饰符大家平时在项目中使用的也不是很多。
Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存重新读取该成员的值,而且,当成员变量值发生变化时,强迫将变化的值重新写入共享内存,这样两个不同的线程在访问同一个共享变量的值时,始终看到的是同一个值。
java语言规范指出:为了获取最佳的运行速度,允许线程保留共享变量的副本,当这个线程进入或者离开同步代码块时,才与共享成员变量进行比对,如果有变化再更新共享成员变量。这样当多个线程同时访问一个共享变量时,可能会存在值不同步的现象。
而volatile这个值的作用就是告诉VM:对于这个成员变量不能保存它的副本,要直接与共享成员变量交互。
建议:当多个线程同时访问一个共享变量时,可以使用volatile,而当访问的变量已在synchronized代码块中时,不必使用。
缺点:使用volatile将使得VM优化失去作用,导致效率较低,所以要在必要的时候使用。
例子
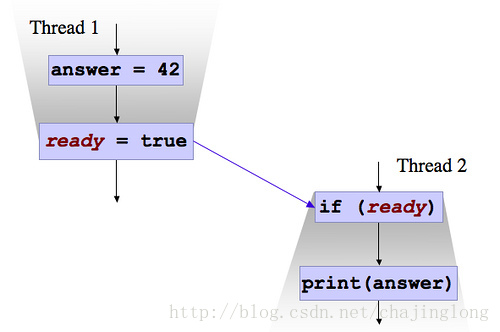
借用Google JEREMY MANSON 的解释,上图表示两个线程并发执行,而且代码顺序上为Thread1->Thread2
1. 不用 volatile
假如ready字段不使用volatile,那么Thread 1对ready做出的修改对于Thread2来说未必是可见的,是否可见是不确定的.假如此时thread1 ready泄露了(leak through)了,那么Thread 2可以看见ready为true,但是有可能answer的改变并没有泄露,则thread2有可能会输出 0 (answer=42对thread2并不可见)
2. 使用 volatile
使用volatile以后,做了如下事情
* 每次修改volatile变量都会同步到主存中
* 每次读取volatile变量的值都强制从主存读取最新的值(强制JVM不可优化volatile变量,如JVM优化后变量读取会使用cpu缓存而不从主存中读取)
* 线程 A 中写入 volatile 变量之前可见的变量, 在线程 B 中读取该 volatile 变量以后, 线程 B 对其他在 A 中的可见变量也可见. 换句话说, 写 volatile 类似于退出同步块, 而读取 volatile 类似于进入同步块
所以如果使用了volatile,那么Thread2读取到的值为read=>true,answer=>42,当然使用volatile的同时也会增加性能开销
优缺点:volatile解决了线程间共享变量的可见性问题
使用volatile会增加性能开销
volatile并不鞥解决线程同步问题
解决了i++或者++i这样的线程同步问题需要使用synchronized或者AtomicXX系列下的包装类,同时也会增加性能的开销
Volatileg关键字保证了在多线程环境下,被修饰的变量在别的线程修改后会马上同步到主存,这样改线程对这个变量的修改就是对其他线程的可见性,其他线程能够马上读到这个修改后的值。
3、3*0.1 == 0.3将会返回什么,true或者false?
false,试着输出一下3*0.1的值会是0.300000000000004,因为3*0.1运算过程中自动类型提升了,有些浮点数不能完全精确 表示出来,浮点数精度默认为6位。
4、说下Java堆空间结构,及常用的jvm内存分析命令和工具
Java堆空间结构图:http://www.cnblogs.com/SaraMoring/p/5713732.html
JVM内存状况查看方法和分析工具:
http://blog.csdn.net/neosmith/article/details/47753733
5、用什么工具和方法分析线程问题
6、列举几个索引失效的情况
索引并不是时时都会生效的,比如以下几种情况,将导致索引失效:
1. 如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
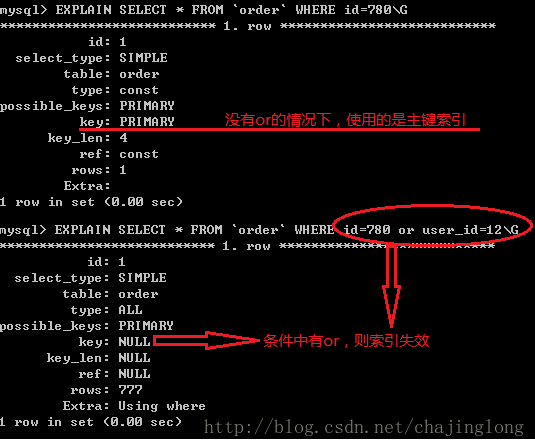
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
2.对于多列索引,不是使用的第一部分,则不会使用索引
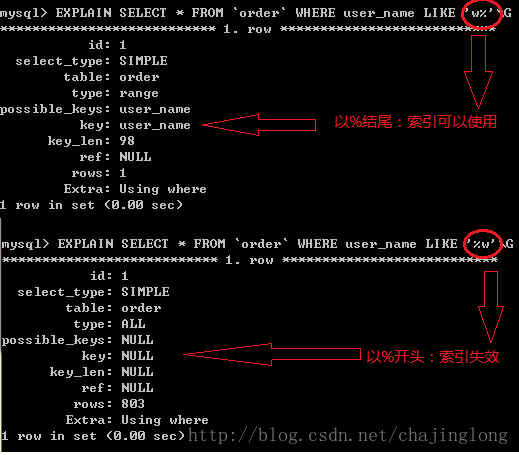
3.like查询是以%开头
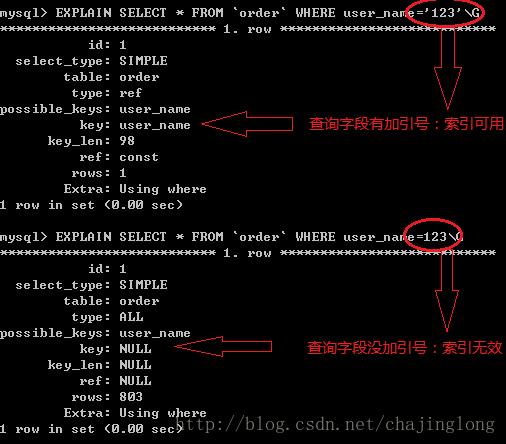
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
7、或一个时序图描述从用户在浏览器地址栏输入url并按回车,到浏览器显示相关内容的各个过程
其实考察的就是一次HTTP请求所经过的过程和Spring或者SpringMVC怎么调用dispatcherServlet的过程
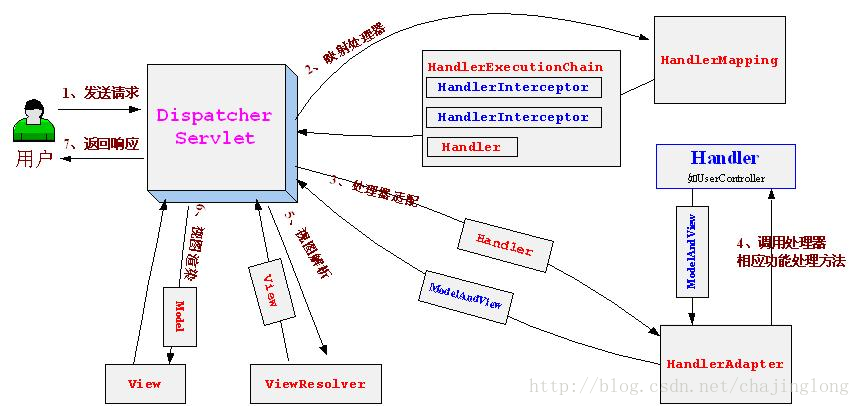
8、有一个servlet,提供对外服务,10个请求下创建了几个servlet实例
servlet共享一个,感觉首先内存占用少,毕竟并发上来之后如果每次都创建的话,内存消耗很大,另一方面servlet只有一个对象的话,可以只在第一次请求过来时候创建一个对象,然后调用init初始化一些参数之后就可以在后面直接使用了。
connection链接利用链接池的概念,这样在服务启动时候直接创建固定数量的链接,避免在高并发线程请求时候不断的创建链接,这样会消耗大量的资源,这样就把这资源消耗的过程放在了服务启动的过程中。
9、有如下表:
Create table T_A{
id bigint primary key,
status int
}
用户A 和 B几乎同时对表里同一条数据的status字段进行更新,其中A用户时字段从0变到1,B用户时从0变到2;如何保证最先执行的结果不被后面执行的干掉
考察悲观锁和乐观锁的,使用乐观锁加版本号。
10、在jdbc编程中,如何避免sql注入漏洞
1.传统JDBC,采用PreparedStatement 。预编译语句集,内置了处理SQL注入的能力
String sql= “select * from users where username=? and password=?”; //如果把?改为:username1,按参数名绑定
PreparedStatement preState = conn.prepareStatement(sql);
preState.setString(1, userName); //则此处变为.setString(“username1”,username)
preState.setString(2, password);
ResultSet rs = preState.executeQuery();
2. 采用正则表达式,将输入的所有特殊符号转换为空格或其他字符
public static String TransactSQLInjection(String str)
{
return str.replaceAll(“.([‘;]+|(–)+).“, ” “);
// 我认为 应该是return str.replaceAll(“([‘;])+|(–)+”,”“);–>这是原作者的注释,个人不是很赞同。
}
userName=TransactSQLInjection(userName);
password=TransactSQLInjection(password);
String sql=”select * from users where username=’”+userName+”’ and password=’”+password+”’ “;
Statement sta = conn.createStatement();
ResultSet rs = sta.executeQuery(sql);
- JAVA Web中,编写Fileter,实现对renquest请求中参数的不合法字符替换
for(String word : invalidsql){
if(word.equalsIgnoreCase(value) || value.contains(word)){
if(value.contains(“<”)){
value = value.replace(“<”, “<”); //这个个人认为括号中第二个<应该替换成其他符号
}
if(value.contains(“>”)){
value = value.replace(“>”, “>”);
}
request.getSession().setAttribute(“sqlInjectError”, “the request parameter \”“+value+”\” contains keyword: \”“+word+”\”“);
response.sendRedirect(request.getContextPath()+error);
return;
}
}
4、通过Hibernate框架的sql注入防范
11,如果由你编写一个类似于guava中的缓存组件,有哪些场景需要考虑,有什么解决方式
最后一道,由你们自由发挥吧,针对部门不一样,考察的重点不一样,基本上都是多线程,多线程会出现什么问题?高并发怎么处理?希望你们自己有自己的理解!















 2123
2123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









