







首先在三台虚拟机上成功安装好jdk并配置好环境
加压缩命令:tar -zxvf jdk-8u141-linux-x64.tar.gz
解压好后将文件放置/usr/local文件下
配置环境变量:vi /etc/profile
环境变量生效:source /etc/profile
测试是否成功:java -version
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
在三台虚拟机上都安装好!
安装hadoop
学习阶段的主要方式:分布模式(官方) 2.7.1 三个角色在三台虚拟机(电脑)
(工作中大多数都是HA模式,但是在学习中不太方便实用)
(先展示单机模式的):
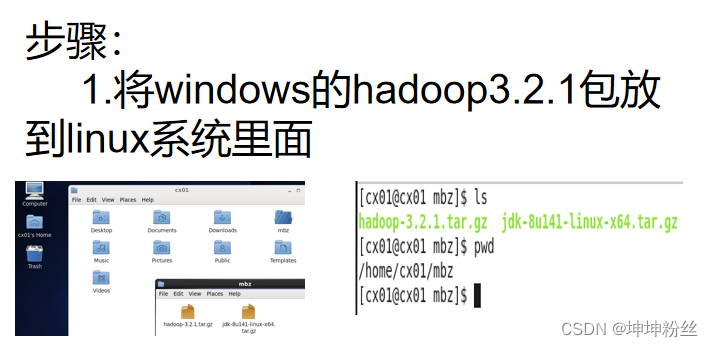
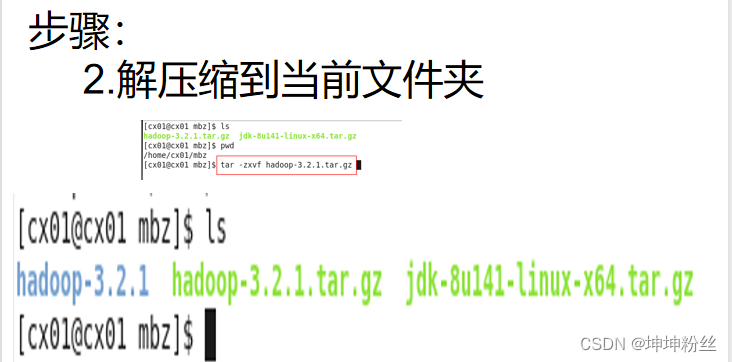



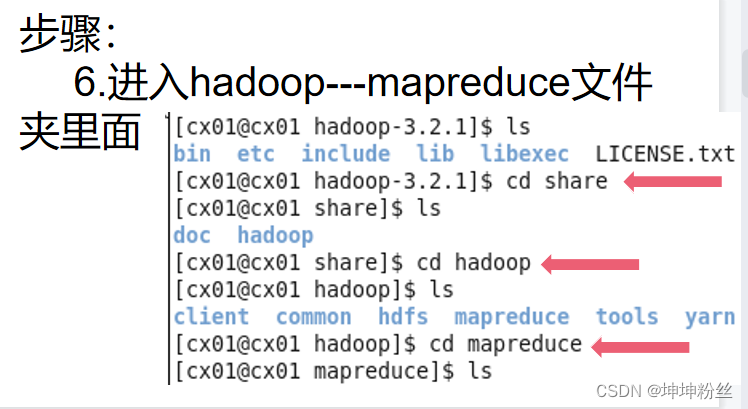




初识hadoop
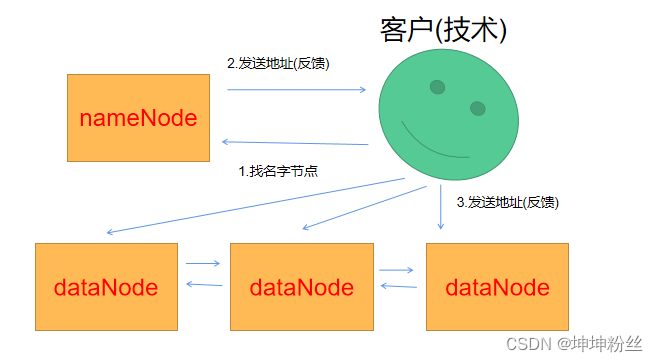
hadoop 分布式系统
hdfs 分布式存储系统
mapReduce 分布式计算系统

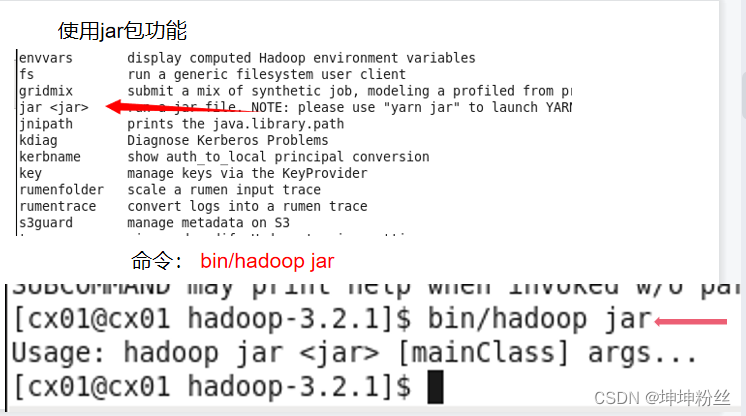
hadoop打包
内部提供了一些打包的方式
甚至还可以
重写方法(覆盖原本的打包方式)
hadoop RPC通信方式
不同节点之间的
数据
交互
hadoop 序列化与反序列化
方便存储
(有一定的规则)
方便传递/交互
(序列化的数据正好可以通过RPC来通信) 重写方法(覆盖原本的打包方式)
搭建hadoop
方式:分布式文件存储系统
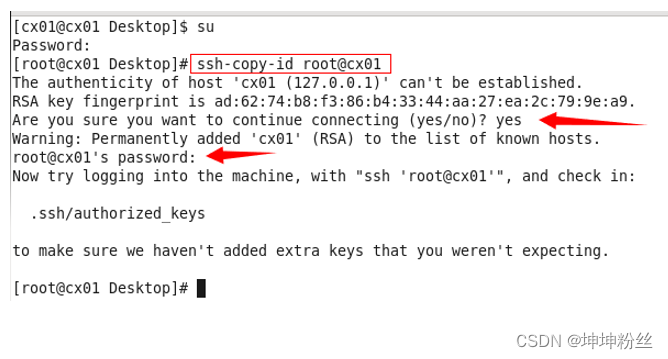
先整一个和自身的ssh免密登录
搭建集群的前提:
前提: 1.主机01 ssh免密: 01 、 02 、 03
2.三台虚拟机都已经安装了jdk
3.关闭防火墙
防火墙:
查看状态:service iptables status
关闭:service iptables stop
永久关闭:chkconfig iptables off
配置环境变量:(需要修改的东西在最底部)



配置hadoop文件









初始化




配置环境变量
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
vi hadoop-env.sh
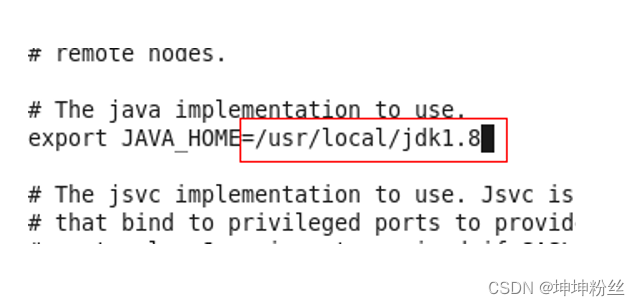
指定jdk路径
export JAVA_HOME=/usr/local/jdk1.8
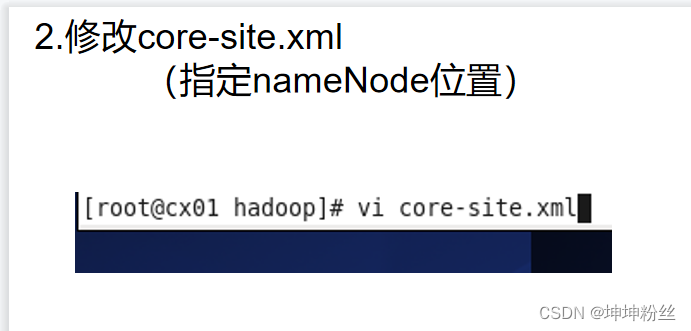
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://bz01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
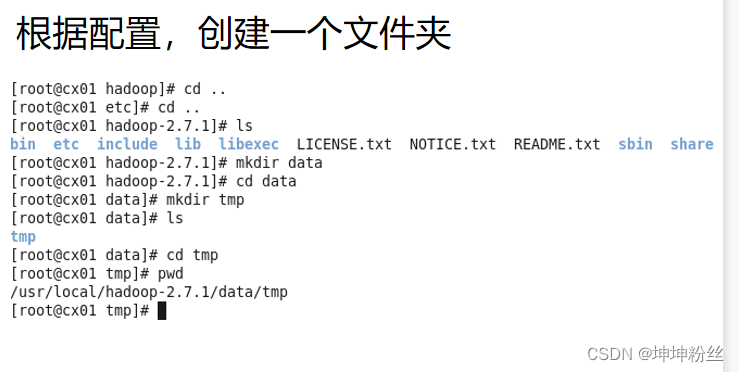
<value>/usr/local/hadoop-2.7.1/data/tmp</value> 三台虚拟机都需要自己创建一个目录
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bz02:50090</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
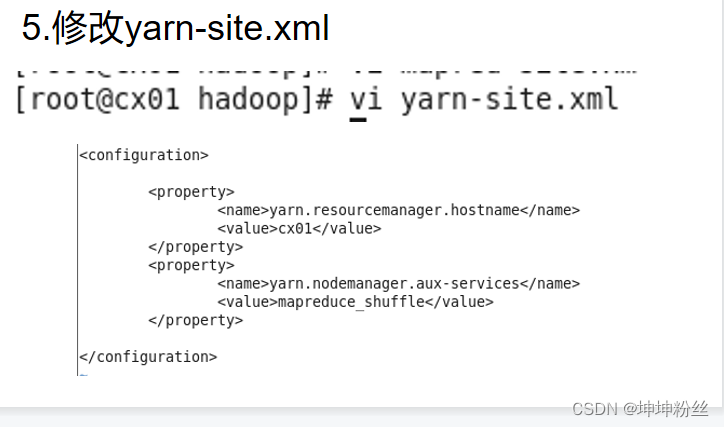
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bz01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
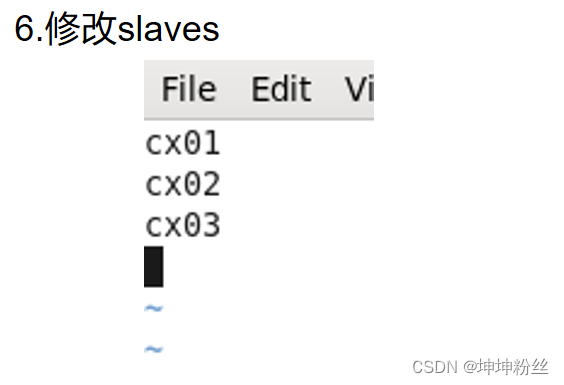
</configuration>vi slaves
bz01
bz02
bz03
分发
scp /etc/profile bz02:/etc/profile
scp /etc/profile bz03:/etc/profilescp -r /usr/local/hadoop-2.7.1 bz02:/usr/local/
scp -r /usr/local/hadoop-2.7.1 bz03:/usr/local/
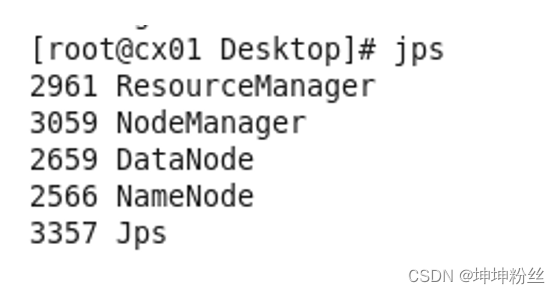
检查02 03:hadoop命令启动之前格式化hdfs namenode -format
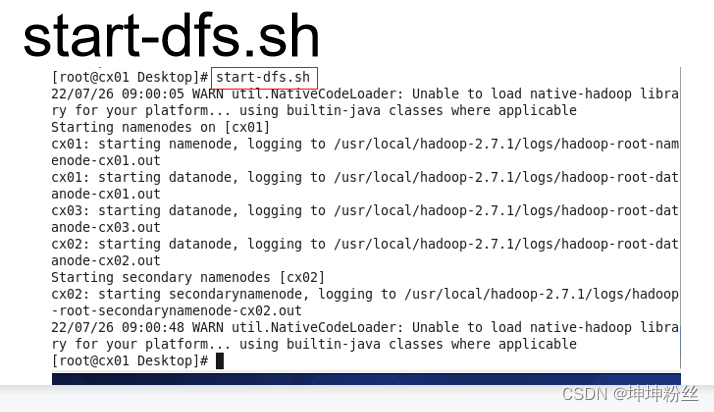
start-dfs.sh stop-dfs.sh















 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









