







本文是python入门练习题,为大家总结了python入门的最基础知识同时也是最常用的知识以及相应的题目,大家可以用于练习python,也适合用于python期末复习哦!
- 输出由任意字符串堆积的等腰三角形,行数由用户输入确定。
输出示例:

实现代码:
n = eval(input("请输入行数:"))
for i in range(1,n+1):
print("{0:^{1}}".format("*"*(i*2-1),2*n-1))
涉及知识:
format方法控制格式:
{<要控制的参数序号>:<格式控制标记符》}
以实现代码为例:{0:^{1}} 0 对应的参数即为填充字符,只有一个参数时,可省略, ^为中间对齐,若 ^前无字符则不足宽度时默认用空格填充,{1}对应的就是宽度
- 能力值的计算:一年 365 天,以第 1 天的能力值为基数,记为 1.0,当每天好好学习时能力值相比前一天提高 1‰,当没有学习时由于遗忘等原因能力值相比前一天下降 1‰, 完成下列能力值的计算:
(1) 每天努力和每天放任,一年下来的能力值分别多少?
(2) 一周 5 个工作日,如果每个工作日都好好学习,在周末放任一下,计算 1 年后的能力值。
输出示例:
 实现代码:
实现代码:
base=1.0
factor=0.001
print("每天努力,你的能力值为: {:.2f}".format(pow(base+factor,365))+';'+"每天放任,你的能力值为:{:.2f}".format(pow(base-factor,365)))
base=1.0
for i in range(1,366):
if(i%7 in [0,6]):
base=base*(1+factor)
else:
base=base*(1-factor)
print('工作日努力,周末放任,一年后你的能力值为: {:.2f}'.format(base))
- 凯撒密码:设想在某些情况下给朋友传递字条信息,但又不希望传递中途被第三方看懂这些信息,因此需要对字条信息进行加密处理。凯撒密码采用了替换算法对信息中的每一个英文字符循环替换为该字符后面第三个字符,对应关系如下:
原文: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文: D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
其它字符保持不变。编程实现:程序接收用户输入待加密的信息,输出加密后的密文。
输出示例:
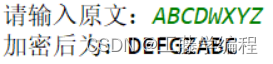 实现代码:
实现代码:
str=input("请输入原文: ")
n=len(str)
str1=''
for ch in str:
if('A'<=ch<='Z'):
str1+=chr((ord(ch)-ord('A')+3)%26+ord('A'))
else:
str1+=ch
print("加密后为: {}".format(str1))
知识点:ord函数将字符转换为数字,chr函数将数字转换为对应的字符
- 假设个人所得税税率表如下:
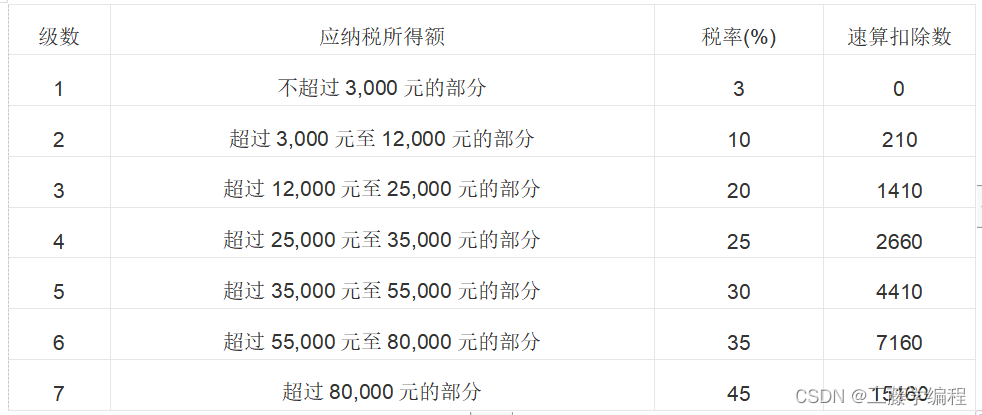 所得税计算公式如下:
所得税计算公式如下:
应纳税额 = (工资薪金所得 - 五险一金 - 个税免征额) × 适用税率 - 速算扣除数
请编写一个个人所税计算器,用户输入应发工资薪金所得、五险一金金额和个税免征额,输出应缴税款和实发工资,结果保留小数点后两位。当输入数字小于0或等于0时,输出“error”。
其中:实发工资 = 应发工资 - 五险一金 - 应缴税款
示例:

实现代码:
shouldPay=eval(input("请输入应发工资薪金所得:"))
fiveFund=eval(input("请输入五险一金:"))
taxExemption=eval(input("请输入个税免征额:"))
shouldPayTax=shouldPay-fiveFund-taxExemption
payTax = 0
if(shouldPay<=0 or fiveFund<=0 or taxExemption <= 0):
print("error")
else:
if shouldPayTax > 80000:
payTax = shouldPayTax * 0.45 - 15160
elif shouldPayTax > 55000:
payTax = shouldPayTax * 0.35 - 7160
elif shouldPayTax > 35000:
payTax = shouldPayTax * 0.3 - 4410
elif shouldPayTax > 25000:
payTax = shouldPayTax * 0.25 - 2660
elif shouldPayTax > 12000:
payTax = shouldPayTax * 0.20 - 1410
elif shouldPayTax > 3000:
payTax = shouldPayTax * 0.10 - 210
else:
payTax = shouldPayTax * 0.03
salary = shouldPay-payTax-fiveFund
print('应缴税款{0:.2f},实发工资{1:.2f}'.format(payTax,salary))
- 实现用户输入用户名和密码登录,当用户名为admin或administrator且密码为666666时,显示“登录成功”,否则显示“登录失败”,登录失败时允许重复输入三次。
示例:
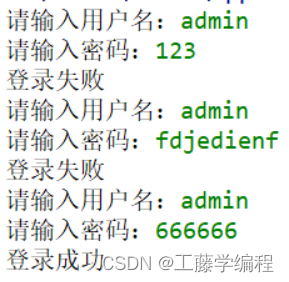 实现代码:
实现代码:
account=input("请输入用户名:")
password=input("请输入密码:")
if password=="666666" and (account=="admin" or account==administrator):
print("登录成功")
else:
print("登录失败")
for i in range(3):
account = input("请输入用户名:")
password = input("请输入密码:")
if password == "666666" and (account == "admin" or account == administrator):
print("登录成功")
break
else:
print("登录失败")
- 输入一个整数作为随机函数种子,随机生成5个不同的长度为10的激活码。
要求1:如果用户输入的不是整数,需要异常处理并进行提示。
要求2:使用随机生成时,生成数字概率为1/5,大写字母和小写字母概率各为2/5。

import random
list=[0,1,2,3,4,5,6,7,8,9]
try:
rand=eval(input("请输入随机数种子:"))
except NameError:
print("输入错误,请输入一个整数!")
else:
random.seed(rand)
for i in range(5) :
randStr=""
for j in range(10):
b = random.randint(0, 4)
if b == 0 :
randStr+=repr(list[random.randint(0, 9)])
elif b==1 or b==2 :
randStr+=chr(random.randint(ord("a"), ord("z"))-32)
elif b==3 or b==4:
randStr+=chr(random.randint(ord("a"), ord("z")))
print(randStr)
知识点:randint(a,b)生成一个[a,b]之间的整数
- 学校举办朗诵比赛,邀请了10位评委为每一名参赛选手的表现打分,打分由random库中的随机函数进行,打分范围在[80,100]之间,打分的结果存放在列表lst_score中。编写程序,根据以下规则计算参赛选手的最终得分:
1.去掉一个最高分;(要求使用pop或者del)
2.去掉一个最低分;(要求使用pop或者del)
3.最终得分为剩下8个分数的平均值,保留小数点后两位输出。(要求使用sum)
实现代码如下:
import random
lst_score = []
for i in range(10):
randScore = random.uniform(80, 100)
lst_score.append(randScore)
del lst_score[lst_score.index(max(lst_score))]
del lst_score[(lst_score.index(min(lst_score)))]
print("最终得分为:{0:.2f}".format(sum(lst_score)/8))
知识点:uniform(a,b)生成一个[a,b]之间的随机小数
序列相关函数:
len(s)返回序列s的元素个数
min(s)序列s中最小的元素
max(s)序列s中最大的元素
s.index(X)返回该元素X在在序列中第一次出现的位置
- 假设平均绩点计算方法如下:(课程学分1绩点+课程学分2绩点+课程学分n*绩点)/(课程学分1+课程学分2+课程学分n)。用户循环输入五分制成绩和课程学分,输入‘-1’时结束输入,计算学生平均绩点。等级与绩点对应关系如下表:
成绩 等级 绩点
90-100 A 4.0
85-89 A- 3.7
82-84 B+ 3.3
78-81 B 3.0
75-77 B- 2.7
72-74 C+ 2.3
68-71 C 2.0
64-67 C- 1.5
60-63 D 1.3
补考60 D- 1.0
60以下 F 0
要求:平均绩点保留小数点后2位,注意处理用户的异常输入,提示“输入不合法!”。
示例:
 实现代码:
实现代码:
ziDian = {"A":4.0,"A-":3.7,"B+":3.3,"B":3.0,"B-":2.7,"C+":2.3,"C":2.0,"C-":1.5,"D":1.3,
"D-":1.0,"F":0}
listScore=[]
listXue=[]
while(1):
grade = input("请输入课程成绩,-1结束! ")
if(grade == "-1"):
break;
try:
xueFen= eval(input("请输入课程学分,-1结束!"))
if(xueFen==-1):
break;
except NameError:
print("输入不合法!")
else:
if( not grade in ziDian):
print("输入不合法!")
continue
listScore.append(ziDian.get(grade)*xueFen)
listXue.append(xueFen)
print("你的平均绩点为:{0:.2f}".format(sum(listScore)/sum(listXue)))
- 一个IP地址是由四个字节(每个字节8个位)的二进制码组成。请将32位二进制码表示的IP地址转换为十进制格式表示的IP地址输出。如果输入的数字不足32位或超过32位或输入的数字中有非0和1的数字时输出“data error!”。
要求:综合使用列表,集合和生成式。
示例:
 实现代码:
实现代码:
print("请输入32位的二进制IP地址:")
ipStr = input()
convertSet = set(('0','1'))
if len(ipStr) != 32:
print('data error!')
elif set(ipStr) > convertSet:
print('data error!')
else :
convertList = [int(ipStr[i:i+8],2) for i in range(25) if(i%8==0)]
for i in range(4):
if not i==3:
print(convertList[i],end=".")
else:
print(convertList[i])
- 编写一个函数,模拟微信发红包的红包分配过程。函数有两个参数:一个参数表示红包总金额,默认值为100,另一个参数表示红包数量,默认为10。程序输入:红包总金额和红包数量;程序输出:每个红包的金额。要求:每个红包最低为0.01元;红包总金额不高于200元;红包的随机分配算法尽量公平。
屏幕输出示例:

import random
def redPacket(total_money=100, count=10):
ls = []
if(total_money>200 or total_money/count<0.01):
return None
for i in range(count - 1):
m = random.uniform(0.01,min(total_money / (count - i) * 2,200))
if(total_money/(count-i)<=0.01):
m=0.01
m = round(m, 2)
ls.append(m)
total_money = total_money - m
ls.append(round(total_money, 2))
return ls
totalMoney,count=eval(input('输入红包金额和个数,以逗号隔开:'))
ans = redPacket(totalMoney,count)
if ans==None:
print("输入不合法")
else:
res=[str(i) for i in ans]
res=' '.join(res)
print("每个红包的金额为:\n",res)
知识点:
join函数就是连接列表中的多个字符串,并在相邻两个字符串之间插入指定字符,并返回新的字符串
- 假设我们有一份文件“data.txt”(编码格式UTF-8),文件中包含了很多个人隐私信息。现在需要一份去除其中敏感信息的版本,将文件中所有手机号的47位和身份证号的714位用替换,然后追加到原文件的最后(新起一行),请自己划分功能由不同的函数来完成。
示例:
如果读入文件内容为:张三 居住地:武汉 身份证号:420111199909091234 手机号:13013013130
输出结果是:
张三 居住地:武汉 身份证号:420111********1234 手机号:130***3130
实现代码:
f=open('C:\\Desktop\\data.txt',mode='a+',encoding='utf-8')
f.seek(0)
ls=[]
lines=[]
j=0;
for line in f:
if line.__contains__("身份证号"):
ls=list(line)
for i in range(12,19):
ls[i]="*"
line=''.join(ls)
if line.__contains__("手机号"):
ls=list(line)
for i in range(7,11):
ls[i]="*"
line=''.join(ls)
lines.append(line)
f.write('\n')
for i in lines:
f.write(i)
f.close()
知识点:f.seek(0)就是让读指针指向文件最开始的地方,避免有时读出来数据是空的,还有就是路径写自己的
现在有UTF-8格式编码的名为 “score1.csv”的文件,里面存放着某班学生的Python课程成绩,共有学号、平时成绩、阶段测试、实报报告,机考成绩五列。请根据平时成绩10%,阶段测试30%,实验报告20%,机考成绩占40%的比例计算考核成绩(取整数),并分学号、考核成绩两列,按照考核成绩由高到低的顺序写入另一文件“score2.txt”中。同时在屏幕上输出班级学生总人数,按考核成绩计90以上、80~89、70~79、60~69、60分以下各成绩档的人数和班级总平均分(取整数)。要求不能使用第三方库,自己划分功能由不同的函数来完成。
屏幕输出示例:
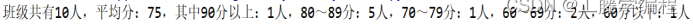 文件输出示例:
文件输出示例:
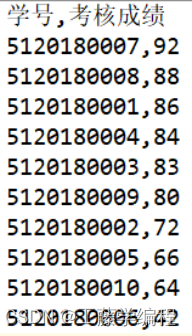
实现代码:
def readData():
f=open('C:\\Desktop\\score1.csv',mode='a+')
f.seek(0)
for line in f:
line=line.replace("\n","")
ls.append(line.split(","))
f.close()
def caculateScore():
for i in range(len(ls)):
score=0
for j in range(len(ls[i])):
if i!=0 and j!=0:
ls[i][j]=int(ls[i][j])
score=dictSocre.get(j)*ls[i][j]+score
dict[ls[i][0]]=int(score)
lsSocre.append(int(score))
def getResult():
for i in lsSocre:
if i>=90:
ls1.append(1)
elif i>=80:
ls2.append(1)
elif i>=70:
ls3.append(1)
elif i>=60:
ls4.append(1)
else:
ls5.append(1)
def outInFile():
f = open('C:\\Desktop\\score2.txt', mode='a+')
f.write("学号,"+" 课程成绩")
for i in range(len(dict)):
f.write('\n'+dict[i][0]+","+repr(dict[i][1]))
ls=[]
dict={}
lsSocre=[]
dictSocre={1:0.1,2:0.3,3:0.2,4:0.4}
ls1=[]
ls2=[]
ls3=[]
ls4=[]
ls5=[]
readData()
caculateScore()
dict.pop("学号")
lsSocre.pop(0)
dict=(sorted(dict.items(),key=lambda x:x[1],reverse=True))
outInFile()
getResult()
print("班级共有:{0},平均分:{1},其中90分以上:{2}人,80~89分:{3}人,70~79分:{4}人,60~69分:{5}人,60分以下:{6}人".format(len(dict),int(sum(lsSocre)/len(dict)),sum(ls1),sum(ls2),sum(ls3),sum(ls4),sum(ls5)))
知识点:
w+为覆盖写,a+为追加写
split()函数:用指定字符(必须是字符串中包含的,并且用于分割的字符将会出现)将字符串分割为多个字符串,并返回列表
sorted函数,第一个是将字典的键值对进行排序,key用于控制排序的依据,x:x[1]就是按字典的值进行排序,由于默认从小到大,所以revese之后就是从大到小,并且sorted之后再赋值给原来的字典,将变为元组。
repr()函数:将指定内容转换为字符串
注意遍历二维数组必须加range(len())
拓充:
二维csv的写入:
for i in ls1:
f.write(",".join(i)+'\n')
其中,ls1为二维数组,且数组中元数必须为字符串,因为无论是join函数还是写入文件时,都需要为字符串
jieba库的简单使用说明:
读入数据:
data=open(“C:\Desktop\天龙八部.txt”,‘r’,encoding=“gb18030”).read()
jieba.luct(data),返回一个列表

















 5415
5415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











