






我们前面把每种格式的模型参数设置已经讲解清楚,下面我们应该弄清楚通用模型切片剩下的流程,不管是人工模型,还是shp矢量面、bim模型,剩下的处理过程都是一样的,这里我们一起讲述。
- 资源库

通用模型处理分为两个过程:数据导入 和 模型切片
数据导入过程会让各种格式的数据归一化,模型切片过程不再考虑格式的差异。
1)资源文件

资源文件如果没有设置,我们会在内存中创建一个资源文件。如果设置了本地一个文件,那么会创建在本地。
设置本地资源路径的两种可能:1,数据量过大,内存不够用。2,为了方便进行【跳过导入】的调试。
2)跳过导入
模型切片过程是个慢过程,数据容易处理失败,为了方便调试,我们可以直接选择一个
已经存在硬盘上的资源文件,并且

,那么就直接跳过 数据导入过程,直接进行模型切片过程。
2.小场景处理器
根据数据特点和用户可视化需求,我们把通用模型处理分为两种处理策略,一种是小场景,一种是八叉树。
界面上如下选择:

小场景处理器不对输入数据做任何简化和缩放,直接使用的原始精度。但是会做合并、压缩(注意简化和压缩的区别,简化是生成粗数据,顶点个数可能会改变,压缩是减少硬盘、内存、显存的消耗,顶点个数不变)、分割等。在保证显示质量不损失的前提下,最大化提升数据加载效率。
1)大小参数
小参数控制产生的最小切片数据量,比如默认是 2MB,比如我们处理过程种有一些 b3dm 或者 i3dm 小于 2MB,我们会进行合并生成 cmpt,这么做目的是减少请求数量。
大参数控制产生的最大切片数据量,比如默认是 20MB,我们处理过程中如果有一些 b3dm 超过 20MB,我们会尝试进行分割。需要注意,这个分割是在空间进行的,我们碰到过一些特例,一个肉眼不可见的小构件竟然有几十万顶点(BIM 数据本身的问题),这种无法在空间上分割,导致最终产生的单个b3dm 有 200 多 MB。
这两个参数判断未做顶点压缩之前的数据,所以开启了顶点压缩后,实际产生的 b3dm要比设置的更小一些。
2)I3dm 优化数
通用模型处理工具里已经实现了对于具有同样几何体数据的对象做实例化渲染优化。这种优化对于模型复用率较高的数据有很大优化,比如 BIM 中的道路附属物,建筑内部的一些小型设备等等。
这里默认是 50,表示如果一个几何体复用次数超过了 50 次,那么我们就把该几何体使用 i3dm 方式渲染。反之使用 b3dm。
模型复用率越高,i3dm 优化意义越大。有人尝试把这个值设置为 2,只要复用超过 2次,就使用 i3dm,就会发现 i3dm 的个数会很多,反倒导致最终的渲染效率降低。所以这个阈值最好和你的数据来匹配调整更合适一些,达到一个渲染批次和数据量的平衡。
3)纹理合并
纹理合并开关打开之后,我们会尝试对 repeat 方式的纹理贴图进行合并,合并之后的数据在官方 Cesium 版本上无法浏览,需要在 EarthSDK 下浏览。如果场景中 repeat 纹理过多,通过此参数可以提升渲染效率。
4)中心线
我们在一些项目实践中,经常要做一些针对线性数据(管道、巷道、隧道)做沿着线性方向的着色等控制,如下图:

我们设置中心线之后,内部处理模型的时候,我们会增加模型的逐顶点属性(atrribute),三个 float 值,分别对应了:
1, 相对中心线起点的距离比例(0~1)0 表示起点位置,1 表示终点位置。
2, 中心线序号,从 0 开始,是中心线 shp 的 fid。
3, 相对中心线起点的绝对距离,单位是米。

另外我们在 3dtiles 的属性里增加了 centerline 属性,通过 lab 的点击工具可以看到,这个值表示构件所属的中心线序号:
为了效果正确,这里必须对中心线有要求:
1, 必须是 shp 格式,而且要信息完整,包括 prj,dbf 等文件。
2, 里面矢量元素必须是折线(linestring)而且坐标点带 z 值,不支持其他类型的中心线格式。
3, 中心线的位置必须和模型位置匹配,中心线落在线状模型的内部。
4, 每个构件只能属于一个中心线,所以构件的长度需要小于等于中心线,而且不能跨越中心线。
最后说明,处理的数据携带上述的 atrribute 之后,不影响在 cesium 里的加载和使用,但是如果要做类似上述热力图效果,需要自己写 shader 实现,未来可能会在 EarthSDK 上做一些封装来支持。
3.八叉树处理器
点击中间的按钮,切换到八叉树处理器,界面如下:

关于八叉树 LOD ,我们需要澄清一个误区:
数据不是带了 LOD 就更优,加载更平滑,渲染更高效。尤其你数据总量就 1G 左右,那其实更应该选择小场景,小场景不带 LOD,可以通过其他的优化手段来最快速加载数据,展示效果和效率基本和建模的精度相当。对于小数据建了 LOD,可能大多情况下都是多此一举。
当数据实在是无法用小场景加载,再考虑采用我们的八叉树处理器来创建 LOD,创建 LOD 是个算法要求很高的过程,直到当前的 Cesiumlab3,我们也无法宣称这个算法很完美,它依然不能应对不限量的数据加载。
1)LOD 策略
创建 LOD 有很多策略,比如以前做数字城市的时候根据建筑对象,每个建筑去生成 lod,然后每个建筑根据远近单独调度。但是我们既然这个工具叫通用模型处理,那么其实也就表示,我们的 LOD 策略需要更通用一些。我们无法预先知道用户的数据是建筑还是道路或者是很精细的 BIM 模型,甚至是某种设备模型。目前我们有两种 LOD 策略:
2)重建化简:
严格按照八叉树分块边界对数据分块,然后每块内尝试简化。3dtiles 在调度中是子块完全替换父块(refine:replace)
这种LOD 策略简单暴力适应性强,适合传统的数字城市的城市建筑模型,目前主要缺陷是:简化速度过慢,而且有个别表面法向量不正确。
3)尺寸过滤:
根据每个对象的大小和当前八叉树级别来计算对象的像素大小
对象当前的像素大小 = 对象 AABB 包围盒 / 当前八叉树块大小 * 512
当这个像素大于最小像素参数的时候,那么该对象会存在于当前八叉树节点中
3dtiles 调度中是增量方式,子块和父块同时渲染(refine:add)
这种 LOD 策略下,每个对象实际并未精简,只是每个对象根据大小加载的优先级不同,适合构件个数非常多的复杂 BIM 模型。
即便有两种策略,但是对于每一类特定数据可能都不是最好方案,如果你们有搞不定的已知数据,可以拿给我们来定制 LOD 生成策略。
4)最小级别
我们的级别和精度 是如下计算的

默认的最小级别 16 级,对应的精度 0.59,也就是说这种尺度下最多能看清楚半米左右的区别。最大级别是 20 级,对应的精度是 0.037,也就是这种尺度下最多能看清 4 厘米左右的区别。
这个尺度对于我们一般的建筑模型完全足够了。
八叉树计算是个极度缓慢的过程,一个块需要的时间大约是在分钟级别。1000 米*1000米范围的大约有 9 个 16 级块,可能有 50 或者 60 个 17 级块,500 个 18 级块,4000 个 19级块,32000 个 20 级。这一平方公里要处理需要的时间很夸张,如果数据已知,那就降低下最大级别。
最小级别按照 数据总范围来设定,如果还是 1000 米*1000 米的模型数据,我们可能设置到 16 或者 17 级比较合适,保证顶层的块个数小于 100 即可。
5)最大级别
一般最大级别 = 最小级别 + 3
这样设置的目的是为了保证数据能够处理完毕如果等的起,可以设置的更大一些。
另外也不是所有位置我们都会处理到最大级别:
如果某个八叉树块内已经没有包含任何数据或者我们统计出来包含的数据量最高精度也不超过我们的阈值,那么这个块就不再继续细分。
有一类特殊数据,比如对于建筑物白模,可以设置 最大级别=最小级别,因为它的几何体简单而且几乎没有纹理。
6)三角网简化
如果场景里几何体复杂密度很高,那么可以开启。但是我们见过很多模型,他的几何体其实很简单,纹理非常大,比如 20MB 的 obj,但是纹理竟然有 8000 多张,这种模型就无需开启三角网进化,我们内部仅对纹理进行简化处理。
在 LOD 策略选择了重建化简得时候有效,如果不开启,那么不对几何体重建,但是会对纹理重建。
7)可见大小
单位是像素,在 LOD 策略是尺寸筛选的时候有效,具体见 LOD 策略的解释。
4.压缩参数

1)纹理格式

选择【默认】使用 jpg(非透明)或者 png(透明)格式。
选择【basis】比原来的综合优化(crn)的压缩速度更快,且支持 pc,android,iphone
多平台使用,只能在 EarthSDK 下使用。
选择【Webp】使用 webp 格式的纹理,webp 存储量大约是默认 jpg 的 70%,可以加快网络传输,但是它只能在 chrome 下使用,而且不会减少显存占用。
选择【ktx2】 使用 ktx2 格式的纹理,存储量大约是默认 jpg 的 90%,可以固定减少显存消耗 5/6 左右,比如一张 1024*1024 分辨率纹理,默认 jpg 在显存里实际占用是固定 3MB显存,处理程 ktx2 只占 3MB / 6 = 512KB,这个对于显卡来说极度友好。不过目前处理过程来相对缓慢。
目前 ktx2 需要付费才可以选择。
我们建议对陌生数据分两次处理,第一次默认纹理处理一遍,检查有无效果异常。如果没问题,第二次再进行 ktx2 压缩处理提升显示效率。
2)顶点压缩
顶点压缩采用了 Draco 压缩算法来减少顶点数据的存储量,Draco 是比较高效的一种压缩方式,目前我们内部的配置是顶点采用 14bit,法向量采用 10bit,纹理坐标采用 10bit,总计 34bit 存储一个顶点。未压缩的数据顶点是 96bit(3个 float),法向量 96bit(3 个 float),
纹理坐标 64bit(2 个 float),总计 256bit。那么压缩率是 :大约 1/7.5,这个压缩率很强大的,大量节省传输数据量。如果你的模型观察视角都是较大范围,那么可以开启这个,如果你的模型包含一些细小的零件,那么最好不要开启,会导致模型扭曲变形。
3)颜色转纹理
这个开关选项,如果开启,如果模型 Mesh 的材质存在基础颜色(baseColorFactor),且不等于纯白色,会做如下操作:
如果此 Mesh 材质也存在基础色纹理,那么该纹理的每个像素值会乘以这个基础颜色。
如果此 Mesh 材质不存在基础色纹理,那么会构造一个 4x4 的小纹理设置到这个材质上,并且把材质的基础色设置为白色。
这么做的意义在于,对于一些 BIM 构件,内部几乎没有纹理,绝大部分构件都是不同颜色,为了能降低渲染批次,而进行此操作。
5.属性字段

1)文件名称
当开启之后,我们生成的 3dtiles,会多出一个 file 的属性,该属性保存的是该对象的导入文件名,在 3dtiles 预览的时候点击可以看到该属性。主要用来区分模型对象的所属文件,方便做业务。
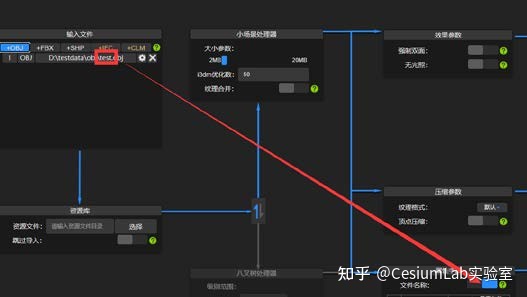
2)属性存储
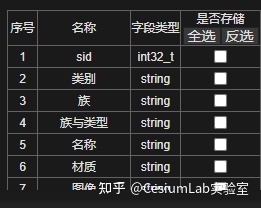
当添加 clm、shp、ifc 这些自带属性字段的文件,或者添加有属性文件配置的 fbx,obj的时候,属性字段列表会列出所有字段是否存储列通过勾选来选择需要存储到 3dtiles 里的属性。3dtiles 属性可以用来做着色分析和控制可见性,同时也会增加数据量,根据你可视化业务的需要酌情选择。
6.数据存储

1)原始坐标
这是一个特殊需求选项,在本文的【通用功能】【空间参考】【输出数据的空间参考】部分我们讨论过 3dtiles 里存储的坐标和输入文件里的坐标并不一致,但是有一些需求会要求保证 3dtiles 里坐标和输入一致,那么可以打开这个选项。
有一些限制条件,要求输入数据的空间参考必须是 ENU:{纬度},{经度}形式,EPSG 形式的即便勾选了此选项也没有作用。如果有多个输入文件,只能保证和第一个输入文件的原始坐标一致(除非所有文件的空间参考是一致的,那么所有文件都可以保证)。
2)模型结构树
通用模型处理的时候默认会生成一个 scenetree.json 文件和 tileset.json 同时存放:
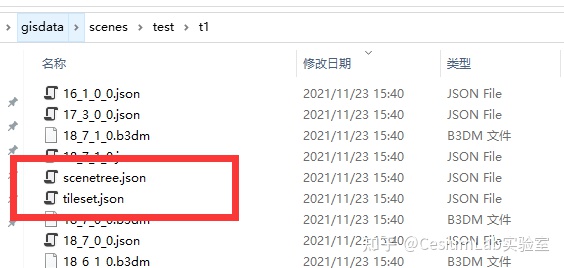
此文件不是 3dtiles 的标准,仅仅是我们自定义的一个文件,但是这个文件在实际使用的时候非常有用,CesiumLab 自带的三维可视页面上,添加一个新的瓦片图层(3dtile)的时候,会尝试自动请求该文件,如果请求成功,会在图层管理上构造模型结构树:

通过模型结构树可以定位构件,以及控制可见性。
- Scenetree.json 文件说明
scenetree.json 是 utf8 编码的 json 格式文件。


最根上是 scenes,它是一个数组,表示json 里有几个场景,此处场景的个数实际对应了你处理数据时候的输入文件个数。除 scenes 之外,其他都是节点对象,对象有以下属性:
type:如果为“node”表示节点对象是一个文件夹,node 在三维数据上并没有对应的渲染内容,仅仅是为了组织这个树结构。如果为”element”表示节点对象是一个构件,element 在三维数据上一定有对应的渲染内容,可以通过 3dtilestyle 去根据 id 控制可见性和着色。
id:节点对象的 id,具体来源参考 id 属性的来源。
name:节点对象的名称,这个名称是为了 UI 上显示方便,具体来源参考 name 属性的来源。
sphere:wgs84 世界坐标系下包围球,前三个值表示 x,y,z 坐标,最后一个表示半径。对于“node”对象来说它的包围球是它下面所有“node”和“element“的并集包围球。
children:“node“对象下包含此属性,表示在这个对象下的子对象,用来构造树状结构。
2.Scenetree.json 生成方式
Scenetree 的树结构对于不同的输入文件按照如下方式组织:
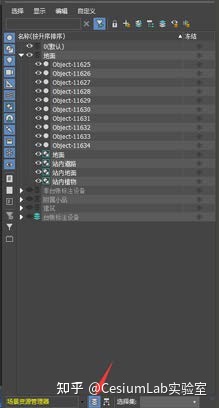
对于 3dsmax 导出的 fbx 格式,该场景组织是和 3dmax 里的结构组织是完全一致的

对于 revit 导出的 clm,我们按照:
标高(Level),类别(Category),构件(Element)三级来构造此树
对于 microstation 导出的 clm,我们按照:
层(Layer),构件(element)两级构造此树。
















 5129
5129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









